 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBankTweak: Adversarial Attack against Multi-Object Trackers by Manipulating Feature Banks
Aug 22, 2024



Multi-object tracking (MOT) aims to construct moving trajectories for objects, and modern multi-object trackers mainly utilize the tracking-by-detection methodology. Initial approaches to MOT attacks primarily aimed to degrade the detection quality of the frames under attack, thereby reducing accuracy only in those specific frames, highlighting a lack of \textit{efficiency}. To improve efficiency, recent advancements manipulate object positions to cause persistent identity (ID) switches during the association phase, even after the attack ends within a few frames. However, these position-manipulating attacks have inherent limitations, as they can be easily counteracted by adjusting distance-related parameters in the association phase, revealing a lack of \textit{robustness}. In this paper, we present \textsf{BankTweak}, a novel adversarial attack designed for MOT trackers, which features efficiency and robustness. \textsf{BankTweak} focuses on the feature extractor in the association phase and reveals vulnerability in the Hungarian matching method used by feature-based MOT systems. Exploiting the vulnerability, \textsf{BankTweak} induces persistent ID switches (addressing \textit{efficiency}) even after the attack ends by strategically injecting altered features into the feature banks without modifying object positions (addressing \textit{robustness}). To demonstrate the applicability, we apply \textsf{BankTweak} to three multi-object trackers (DeepSORT, StrongSORT, and MOTDT) with one-stage, two-stage, anchor-free, and transformer detectors. Extensive experiments on the MOT17 and MOT20 datasets show that our method substantially surpasses existing attacks, exposing the vulnerability of the tracking-by-detection framework to \textsf{BankTweak}.
Semantic-aware Binary Code Representation with BERT
Jun 10, 2021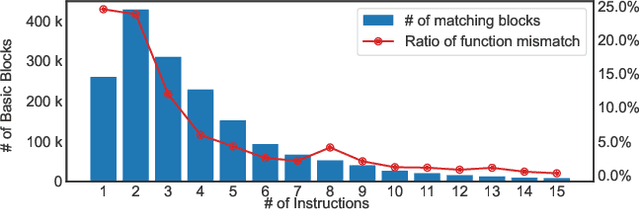
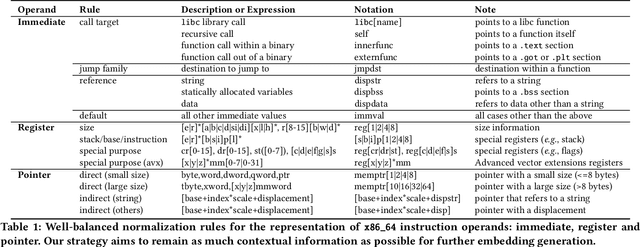
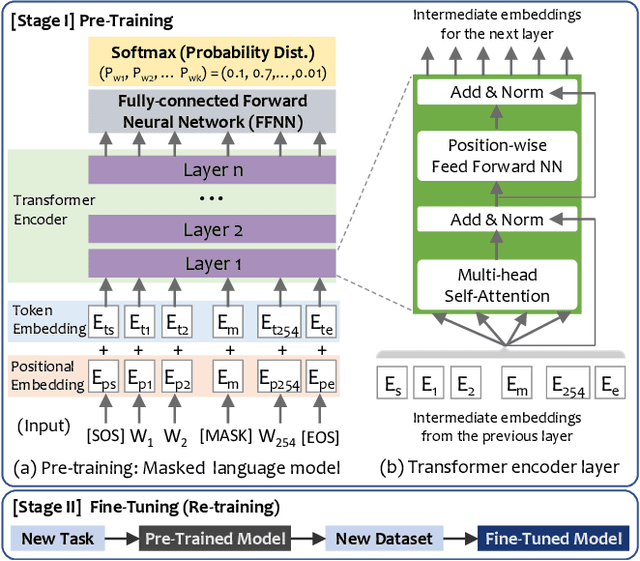
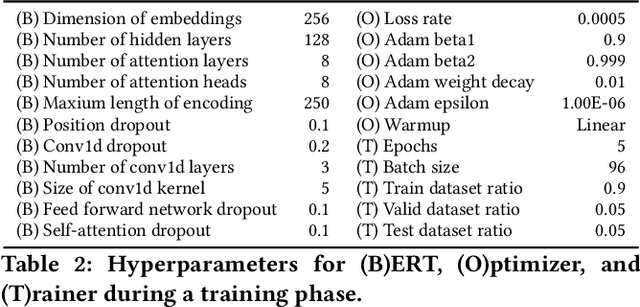
A wide range of binary analysis applications, such as bug discovery, malware analysis and code clone detection, require recovery of contextual meanings on a binary code. Recently, binary analysis techniques based on machine learning have been proposed to automatically reconstruct the code representation of a binary instead of manually crafting specifics of the analysis algorithm. However, the existing approaches utilizing machine learning are still specialized to solve one domain of problems, rendering recreation of models for different types of binary analysis. In this paper, we propose DeepSemantic utilizing BERT in producing the semantic-aware code representation of a binary code. To this end, we introduce well-balanced instruction normalization that holds rich information for each of instructions yet minimizing an out-of-vocabulary (OOV) problem. DeepSemantic has been carefully designed based on our study with large swaths of binaries. Besides, DeepSemantic leverages the essence of the BERT architecture into re-purposing a pre-trained generic model that is readily available as a one-time processing, followed by quickly applying specific downstream tasks with a fine-tuning process. We demonstrate DeepSemantic with two downstream tasks, namely, binary similarity comparison and compiler provenance (i.e., compiler and optimization level) prediction. Our experimental results show that the binary similarity model outperforms two state-of-the-art binary similarity tools, DeepBinDiff and SAFE, 49.84% and 15.83% on average, respectively.