 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Emotion Transfer for Emotion Editing in Talking Face Video
Apr 09, 2026Talking face generation has gained significant attention as a core application of generative models. To enhance the expressiveness and realism of synthesized videos, emotion editing in talking face video plays a crucial role. However, existing approaches often limit expressive flexibility and struggle to generate extended emotions. Label-based methods represent emotions with discrete categories, which fail to capture a wide range of emotions. Audio-based methods can leverage emotionally rich speech signals - and even benefit from expressive text-to-speech (TTS) synthesis - but they fail to express the target emotions because emotions and linguistic contents are entangled in emotional speeches. Images-based methods, on the other hand, rely on target reference images to guide emotion transfer, yet they require high-quality frontal views and face challenges in acquiring reference data for extended emotions (e.g., sarcasm). To address these limitations, we propose Cross-Modal Emotion Transfer (C-MET), a novel approach that generates facial expressions based on speeches by modeling emotion semantic vectors between speech and visual feature spaces. C-MET leverages a large-scale pretrained audio encoder and a disentangled facial expression encoder to learn emotion semantic vectors that represent the difference between two different emotional embeddings across modalities. Extensive experiments on the MEAD and CREMA-D datasets demonstrate that our method improves emotion accuracy by 14% over state-of-the-art methods, while generating expressive talking face videos - even for unseen extended emotions. Code, checkpoint, and demo are available at https://chanhyeok-choi.github.io/C-MET/
OSS-CRS: Liberating AIxCC Cyber Reasoning Systems for Real-World Open-Source Security
Mar 09, 2026DARPA's AI Cyber Challenge (AIxCC) showed that cyber reasoning systems (CRSs) can go beyond vulnerability discovery to autonomously confirm and patch bugs: seven teams built such systems and open-sourced them after the competition. Yet all seven open-sourced CRSs remain largely unusable outside their original teams, each bound to the competition cloud infrastructure that no longer exists. We present OSS-CRS, an open, locally deployable framework for running and combining CRS techniques against real-world open-source projects, with budget-aware resource management. We ported the first-place system (Atlantis) and discovered 10 previously unknown bugs (three of high severity) across 8 OSS-Fuzz projects. OSS-CRS is publicly available.
SoK: DARPA's AI Cyber Challenge (AIxCC): Competition Design, Architectures, and Lessons Learned
Feb 07, 2026DARPA's AI Cyber Challenge (AIxCC, 2023--2025) is the largest competition to date for building fully autonomous cyber reasoning systems (CRSs) that leverage recent advances in AI -- particularly large language models (LLMs) -- to discover and remediate vulnerabilities in real-world open-source software. This paper presents the first systematic analysis of AIxCC. Drawing on design documents, source code, execution traces, and discussions with organizers and competing teams, we examine the competition's structure and key design decisions, characterize the architectural approaches of finalist CRSs, and analyze competition results beyond the final scoreboard. Our analysis reveals the factors that truly drove CRS performance, identifies genuine technical advances achieved by teams, and exposes limitations that remain open for future research. We conclude with lessons for organizing future competitions and broader insights toward deploying autonomous CRSs in practice.
Towards Human-like Multimodal Conversational Agent by Generating Engaging Speech
Sep 18, 2025Human conversation involves language, speech, and visual cues, with each medium providing complementary information. For instance, speech conveys a vibe or tone not fully captured by text alone. While multimodal LLMs focus on generating text responses from diverse inputs, less attention has been paid to generating natural and engaging speech. We propose a human-like agent that generates speech responses based on conversation mood and responsive style information. To achieve this, we build a novel MultiSensory Conversation dataset focused on speech to enable agents to generate natural speech. We then propose a multimodal LLM-based model for generating text responses and voice descriptions, which are used to generate speech covering paralinguistic information. Experimental results demonstrate the effectiveness of utilizing both visual and audio modalities in conversation to generate engaging speech. The source code is available in https://github.com/kimtaesu24/MSenC
ATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025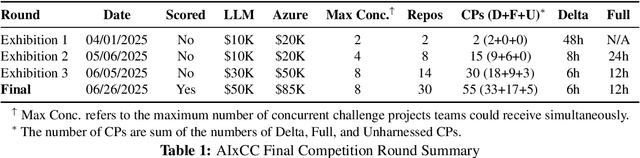
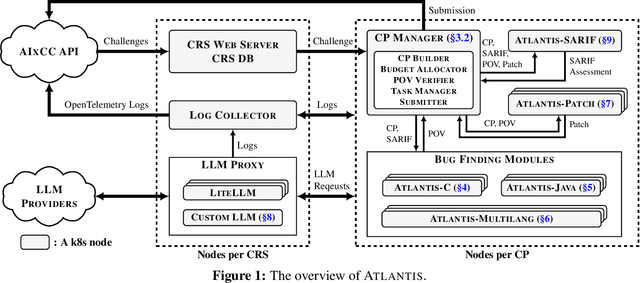
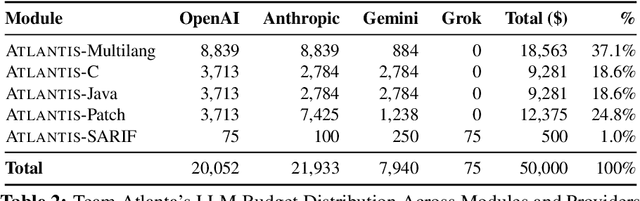
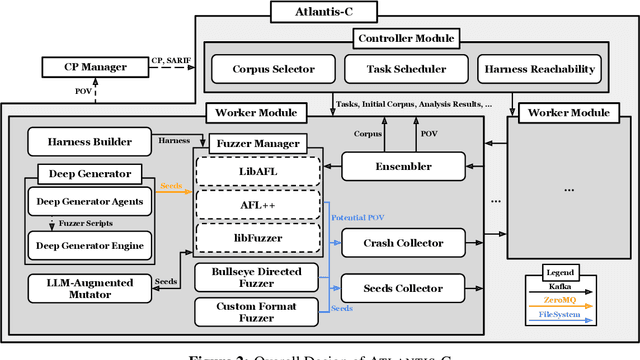
We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
Do Not Mimic My Voice: Speaker Identity Unlearning for Zero-Shot Text-to-Speech
Jul 27, 2025The rapid advancement of Zero-Shot Text-to-Speech (ZS-TTS) technology has enabled high-fidelity voice synthesis from minimal audio cues, raising significant privacy and ethical concerns. Despite the threats to voice privacy, research to selectively remove the knowledge to replicate unwanted individual voices from pre-trained model parameters has not been explored. In this paper, we address the new challenge of speaker identity unlearning for ZS-TTS systems. To meet this goal, we propose the first machine unlearning frameworks for ZS-TTS, especially Teacher-Guided Unlearning (TGU), designed to ensure the model forgets designated speaker identities while retaining its ability to generate accurate speech for other speakers. Our proposed methods incorporate randomness to prevent consistent replication of forget speakers' voices, assuring unlearned identities remain untraceable. Additionally, we propose a new evaluation metric, speaker-Zero Retrain Forgetting (spk-ZRF). This assesses the model's ability to disregard prompts associated with forgotten speakers, effectively neutralizing its knowledge of these voices. The experiments conducted on the state-of-the-art model demonstrate that TGU prevents the model from replicating forget speakers' voices while maintaining high quality for other speakers. The demo is available at https://speechunlearn.github.io/
ReInc: Scaling Training of Dynamic Graph Neural Networks
Jan 25, 2025Dynamic Graph Neural Networks (DGNNs) have gained widespread attention due to their applicability in diverse domains such as traffic network prediction, epidemiological forecasting, and social network analysis. In this paper, we present ReInc, a system designed to enable efficient and scalable training of DGNNs on large-scale graphs. ReInc introduces key innovations that capitalize on the unique combination of Graph Neural Networks (GNNs) and Recurrent Neural Networks (RNNs) inherent in DGNNs. By reusing intermediate results and incrementally computing aggregations across consecutive graph snapshots, ReInc significantly enhances computational efficiency. To support these optimizations, ReInc incorporates a novel two-level caching mechanism with a specialized caching policy aligned to the DGNN execution workflow. Additionally, ReInc addresses the challenges of managing structural and temporal dependencies in dynamic graphs through a new distributed training strategy. This approach eliminates communication overheads associated with accessing remote features and redistributing intermediate results. Experimental results demonstrate that ReInc achieves up to an order of magnitude speedup compared to state-of-the-art frameworks, tested across various dynamic GNN architectures and real-world graph datasets.
HetTree: Heterogeneous Tree Graph Neural Network
Feb 21, 2024



The recent past has seen an increasing interest in Heterogeneous Graph Neural Networks (HGNNs) since many real-world graphs are heterogeneous in nature, from citation graphs to email graphs. However, existing methods ignore a tree hierarchy among metapaths, which is naturally constituted by different node types and relation types. In this paper, we present HetTree, a novel heterogeneous tree graph neural network that models both the graph structure and heterogeneous aspects in a scalable and effective manner. Specifically, HetTree builds a semantic tree data structure to capture the hierarchy among metapaths. Existing tree encoding techniques aggregate children nodes by weighting the contribution of children nodes based on similarity to the parent node. However, we find that this tree encoding fails to capture the entire parent-children hierarchy by only considering the parent node. Hence, HetTree uses a novel subtree attention mechanism to emphasize metapaths that are more helpful in encoding parent-children relationships. Moreover, instead of separating feature learning from label learning or treating features and labels equally by projecting them to the same latent space, HetTree proposes to match them carefully based on corresponding metapaths, which provides more accurate and richer information between node features and labels. Our evaluation of HetTree on a variety of real-world datasets demonstrates that it outperforms all existing baselines on open benchmarks and efficiently scales to large real-world graphs with millions of nodes and edges.
RainSD: Rain Style Diversification Module for Image Synthesis Enhancement using Feature-Level Style Distribution
Dec 31, 2023
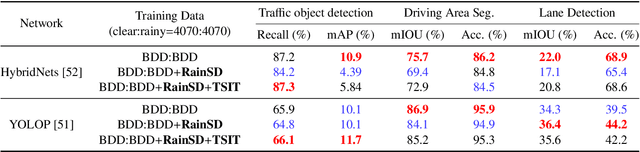
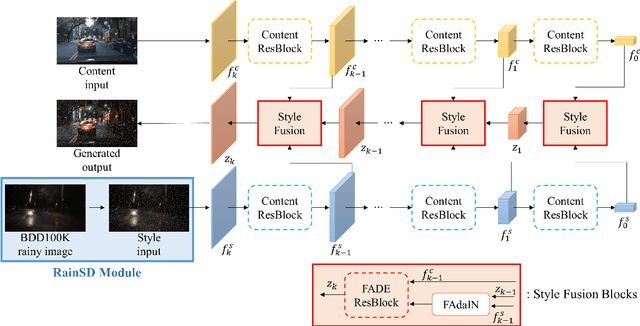

Autonomous driving technology nowadays targets to level 4 or beyond, but the researchers are faced with some limitations for developing reliable driving algorithms in diverse challenges. To promote the autonomous vehicles to spread widely, it is important to address safety issues on this technology. Among various safety concerns, the sensor blockage problem by severe weather conditions can be one of the most frequent threats for multi-task learning based perception algorithms during autonomous driving. To handle this problem, the importance of the generation of proper datasets is becoming more significant. In this paper, a synthetic road dataset with sensor blockage generated from real road dataset BDD100K is suggested in the format of BDD100K annotation. Rain streaks for each frame were made by an experimentally established equation and translated utilizing the image-to-image translation network based on style transfer. Using this dataset, the degradation of the diverse multi-task networks for autonomous driving, such as lane detection, driving area segmentation, and traffic object detection, has been thoroughly evaluated and analyzed. The tendency of the performance degradation of deep neural network-based perception systems for autonomous vehicle has been analyzed in depth. Finally, we discuss the limitation and the future directions of the deep neural network-based perception algorithms and autonomous driving dataset generation based on image-to-image translation.
PAC Neural Prediction Set Learning to Quantify the Uncertainty of Generative Language Models
Jul 18, 2023
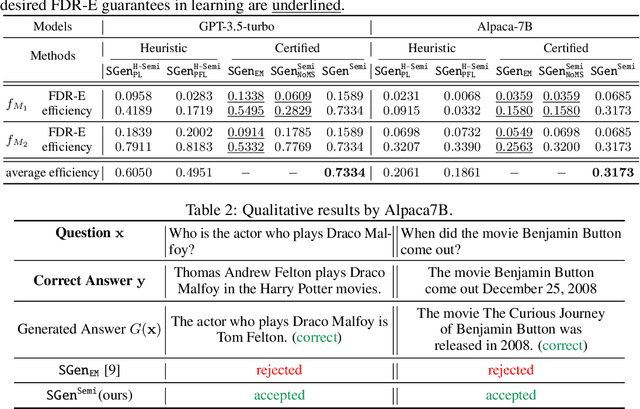
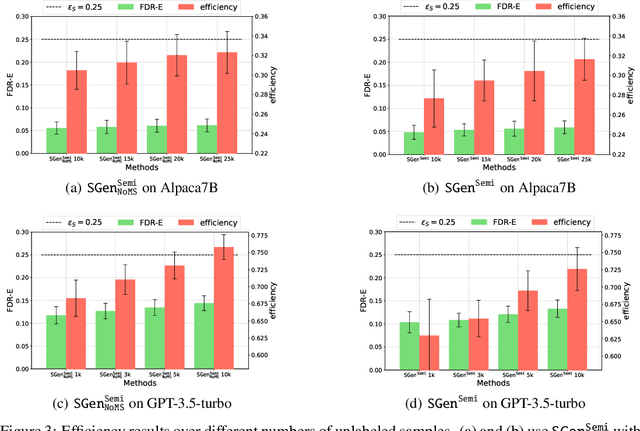
Uncertainty learning and quantification of models are crucial tasks to enhance the trustworthiness of the models. Importantly, the recent surge of generative language models (GLMs) emphasizes the need for reliable uncertainty quantification due to the concerns on generating hallucinated facts. In this paper, we propose to learn neural prediction set models that comes with the probably approximately correct (PAC) guarantee for quantifying the uncertainty of GLMs. Unlike existing prediction set models, which are parameterized by a scalar value, we propose to parameterize prediction sets via neural networks, which achieves more precise uncertainty quantification but still satisfies the PAC guarantee. We demonstrate the efficacy of our method on four types of language datasets and six types of models by showing that our method improves the quantified uncertainty by $63\%$ on average, compared to a standard baseline method.