 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnPII: Unlearning Personally Identifiable Information with Quantifiable Exposure Risk
Jan 05, 2026The ever-increasing adoption of Large Language Models in critical sectors like finance, healthcare, and government raises privacy concerns regarding the handling of sensitive Personally Identifiable Information (PII) during training. In response, regulations such as European Union's General Data Protection Regulation (GDPR) mandate the deletion of PII upon requests, underscoring the need for reliable and cost-effective data removal solutions. Machine unlearning has emerged as a promising direction for selectively forgetting data points. However, existing unlearning techniques typically apply a uniform forgetting strategy that neither accounts for the varying privacy risks posed by different PII attributes nor reflects associated business risks. In this work, we propose UnPII, the first PII-centric unlearning approach that prioritizes forgetting based on the risk of individual or combined PII attributes. To this end, we introduce the PII risk index (PRI), a composite metric that incorporates multiple dimensions of risk factors: identifiability, sensitivity, usability, linkability, permanency, exposability, and compliancy. The PRI enables a nuanced evaluation of privacy risks associated with PII exposures and can be tailored to align with organizational privacy policies. To support realistic assessment, we systematically construct a synthetic PII dataset (e.g., 1,700 PII instances) that simulates realistic exposure scenarios. UnPII seamlessly integrates with established unlearning algorithms, such as Gradient Ascent, Negative Preference Optimization, and Direct Preference Optimization, without modifying their underlying principles. Our experimental results demonstrate that UnPII achieves the improvements of accuracy up to 11.8%, utility up to 6.3%, and generalizability up to 12.4%, respectively, while incurring a modest fine-tuning overhead of 27.5% on average during unlearning.
A Deep Dive into Function Inlining and its Security Implications for ML-based Binary Analysis
Dec 16, 2025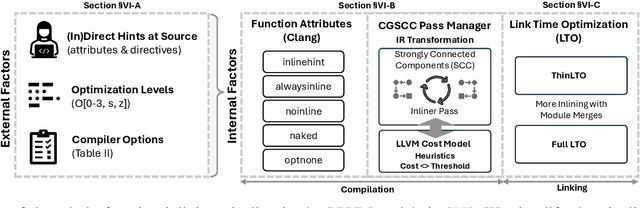



A function inlining optimization is a widely used transformation in modern compilers, which replaces a call site with the callee's body in need. While this transformation improves performance, it significantly impacts static features such as machine instructions and control flow graphs, which are crucial to binary analysis. Yet, despite its broad impact, the security impact of function inlining remains underexplored to date. In this paper, we present the first comprehensive study of function inlining through the lens of machine learning-based binary analysis. To this end, we dissect the inlining decision pipeline within the LLVM's cost model and explore the combinations of the compiler options that aggressively promote the function inlining ratio beyond standard optimization levels, which we term extreme inlining. We focus on five ML-assisted binary analysis tasks for security, using 20 unique models to systematically evaluate their robustness under extreme inlining scenarios. Our extensive experiments reveal several significant findings: i) function inlining, though a benign transformation in intent, can (in)directly affect ML model behaviors, being potentially exploited by evading discriminative or generative ML models; ii) ML models relying on static features can be highly sensitive to inlining; iii) subtle compiler settings can be leveraged to deliberately craft evasive binary variants; and iv) inlining ratios vary substantially across applications and build configurations, undermining assumptions of consistency in training and evaluation of ML models.
Semantic-aware Binary Code Representation with BERT
Jun 10, 2021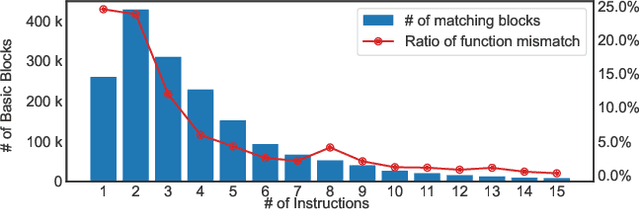
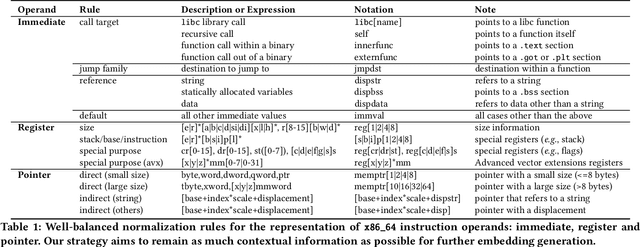
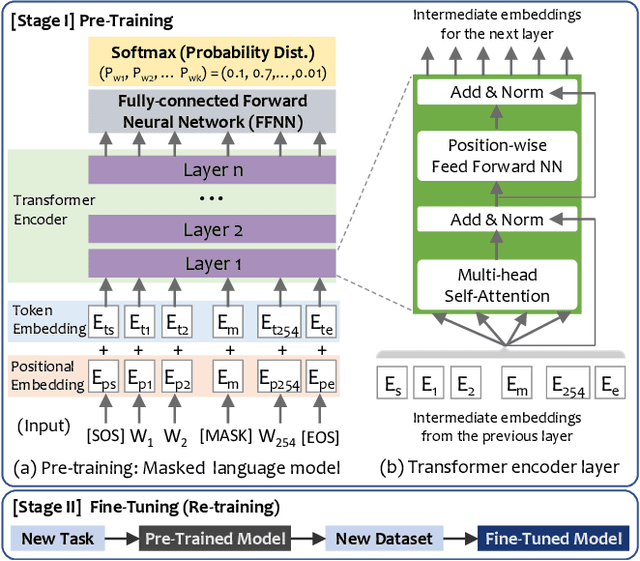
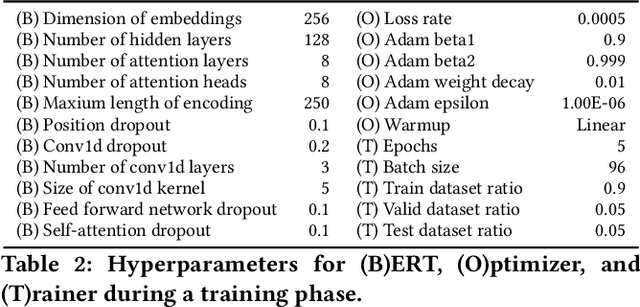
A wide range of binary analysis applications, such as bug discovery, malware analysis and code clone detection, require recovery of contextual meanings on a binary code. Recently, binary analysis techniques based on machine learning have been proposed to automatically reconstruct the code representation of a binary instead of manually crafting specifics of the analysis algorithm. However, the existing approaches utilizing machine learning are still specialized to solve one domain of problems, rendering recreation of models for different types of binary analysis. In this paper, we propose DeepSemantic utilizing BERT in producing the semantic-aware code representation of a binary code. To this end, we introduce well-balanced instruction normalization that holds rich information for each of instructions yet minimizing an out-of-vocabulary (OOV) problem. DeepSemantic has been carefully designed based on our study with large swaths of binaries. Besides, DeepSemantic leverages the essence of the BERT architecture into re-purposing a pre-trained generic model that is readily available as a one-time processing, followed by quickly applying specific downstream tasks with a fine-tuning process. We demonstrate DeepSemantic with two downstream tasks, namely, binary similarity comparison and compiler provenance (i.e., compiler and optimization level) prediction. Our experimental results show that the binary similarity model outperforms two state-of-the-art binary similarity tools, DeepBinDiff and SAFE, 49.84% and 15.83% on average, respectively.