 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-wise Retrieval for Multivariate Time Series Forecasting
Apr 07, 2026Multivariate time series forecasting often struggles to capture long-range dependencies due to fixed lookback windows. Retrieval-augmented forecasting addresses this by retrieving historical segments from memory, but existing approaches rely on a channel-agnostic strategy that applies the same references to all variables. This neglects inter-variable heterogeneity, where different channels exhibit distinct periodicities and spectral profiles. We propose CRAFT (Channel-wise retrieval-augmented forecasting), a novel framework that performs retrieval independently for each channel. To ensure efficiency, CRAFT adopts a two-stage pipeline: a sparse relation graph constructed in the time domain prunes irrelevant candidates, and spectral similarity in the frequency domain ranks references, emphasizing dominant periodic components while suppressing noise. Experiments on seven public benchmarks demonstrate that CRAFT outperforms state-of-the-art forecasting baselines, achieving superior accuracy with practical inference efficiency.
Multimodal Forecasting for Commodity Prices Using Spectrogram-Based and Time Series Representations
Mar 28, 2026Forecasting multivariate time series remains challenging due to complex cross-variable dependencies and the presence of heterogeneous external influences. This paper presents Spectrogram-Enhanced Multimodal Fusion (SEMF), which combines spectral and temporal representations for more accurate and robust forecasting. The target time series is transformed into Morlet wavelet spectrograms, from which a Vision Transformer encoder extracts localized, frequency-aware features. In parallel, exogenous variables, such as financial indicators and macroeconomic signals, are encoded via a Transformer to capture temporal dependencies and multivariate dynamics. A bidirectional cross-attention module integrates these modalities into a unified representation that preserves distinct signal characteristics while modeling cross-modal correlations. Applied to multiple commodity price forecasting tasks, SEMF achieves consistent improvements over seven competitive baselines across multiple forecasting horizons and evaluation metrics. These results demonstrate the effectiveness of multimodal fusion and spectrogram-based encoding in capturing multi-scale patterns within complex financial time series.
Adaptive Information Routing for Multimodal Time Series Forecasting
Dec 23, 2025Time series forecasting is a critical task for artificial intelligence with numerous real-world applications. Traditional approaches primarily rely on historical time series data to predict the future values. However, in practical scenarios, this is often insufficient for accurate predictions due to the limited information available. To address this challenge, multimodal time series forecasting methods which incorporate additional data modalities, mainly text data, alongside time series data have been explored. In this work, we introduce the Adaptive Information Routing (AIR) framework, a novel approach for multimodal time series forecasting. Unlike existing methods that treat text data on par with time series data as interchangeable auxiliary features for forecasting, AIR leverages text information to dynamically guide the time series model by controlling how and to what extent multivariate time series information should be combined. We also present a text-refinement pipeline that employs a large language model to convert raw text data into a form suitable for multimodal forecasting, and we introduce a benchmark that facilitates multimodal forecasting experiments based on this pipeline. Experiment results with the real world market data such as crude oil price and exchange rates demonstrate that AIR effectively modulates the behavior of the time series model using textual inputs, significantly enhancing forecasting accuracy in various time series forecasting tasks.
ATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System
Sep 18, 2025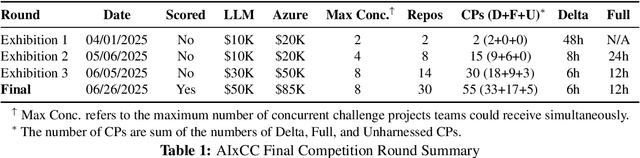
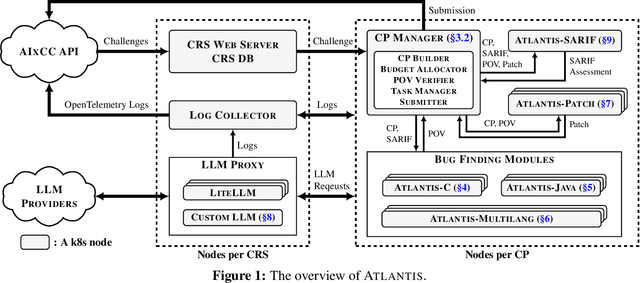
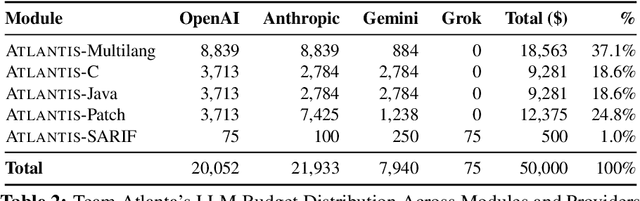
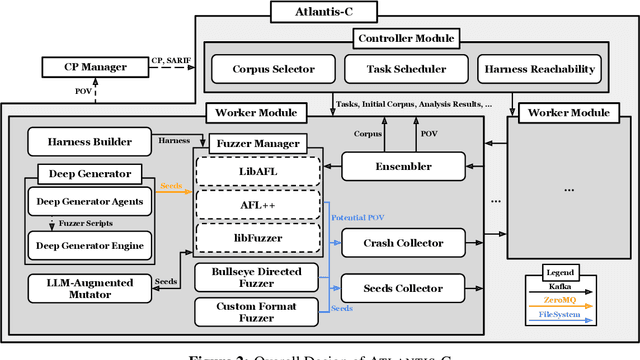
We present ATLANTIS, the cyber reasoning system developed by Team Atlanta that won 1st place in the Final Competition of DARPA's AI Cyber Challenge (AIxCC) at DEF CON 33 (August 2025). AIxCC (2023-2025) challenged teams to build autonomous cyber reasoning systems capable of discovering and patching vulnerabilities at the speed and scale of modern software. ATLANTIS integrates large language models (LLMs) with program analysis -- combining symbolic execution, directed fuzzing, and static analysis -- to address limitations in automated vulnerability discovery and program repair. Developed by researchers at Georgia Institute of Technology, Samsung Research, KAIST, and POSTECH, the system addresses core challenges: scaling across diverse codebases from C to Java, achieving high precision while maintaining broad coverage, and producing semantically correct patches that preserve intended behavior. We detail the design philosophy, architectural decisions, and implementation strategies behind ATLANTIS, share lessons learned from pushing the boundaries of automated security when program analysis meets modern AI, and release artifacts to support reproducibility and future research.
Can We Utilize Pre-trained Language Models within Causal Discovery Algorithms?
Nov 19, 2023Scaling laws have allowed Pre-trained Language Models (PLMs) into the field of causal reasoning. Causal reasoning of PLM relies solely on text-based descriptions, in contrast to causal discovery which aims to determine the causal relationships between variables utilizing data. Recently, there has been current research regarding a method that mimics causal discovery by aggregating the outcomes of repetitive causal reasoning, achieved through specifically designed prompts. It highlights the usefulness of PLMs in discovering cause and effect, which is often limited by a lack of data, especially when dealing with multiple variables. Conversely, the characteristics of PLMs which are that PLMs do not analyze data and they are highly dependent on prompt design leads to a crucial limitation for directly using PLMs in causal discovery. Accordingly, PLM-based causal reasoning deeply depends on the prompt design and carries out the risk of overconfidence and false predictions in determining causal relationships. In this paper, we empirically demonstrate the aforementioned limitations of PLM-based causal reasoning through experiments on physics-inspired synthetic data. Then, we propose a new framework that integrates prior knowledge obtained from PLM with a causal discovery algorithm. This is accomplished by initializing an adjacency matrix for causal discovery and incorporating regularization using prior knowledge. Our proposed framework not only demonstrates improved performance through the integration of PLM and causal discovery but also suggests how to leverage PLM-extracted prior knowledge with existing causal discovery algorithms.
Semantic-aware Binary Code Representation with BERT
Jun 10, 2021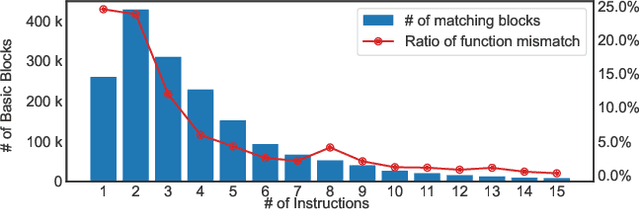
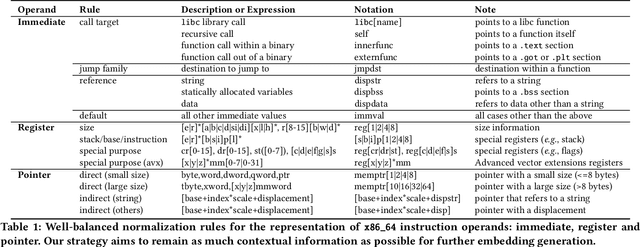
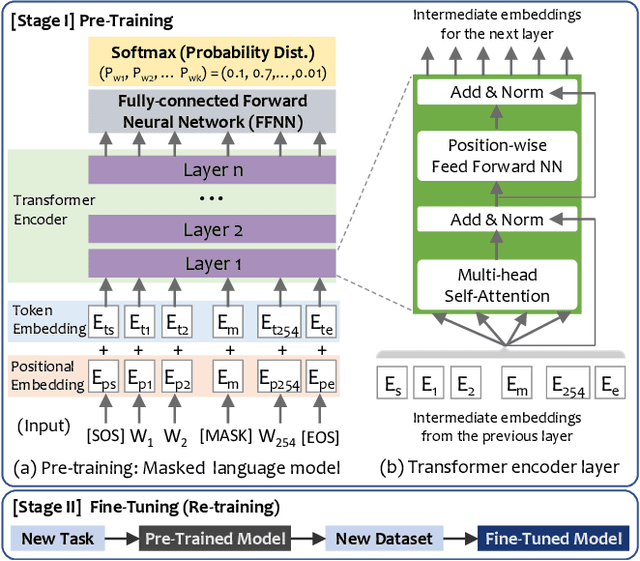
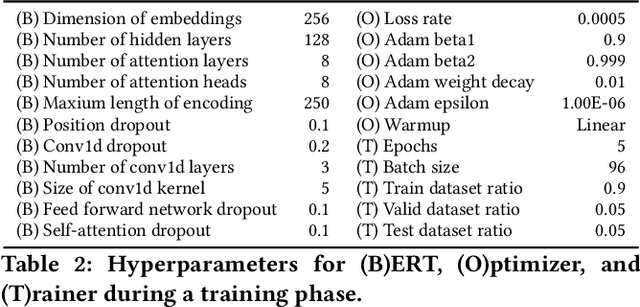
A wide range of binary analysis applications, such as bug discovery, malware analysis and code clone detection, require recovery of contextual meanings on a binary code. Recently, binary analysis techniques based on machine learning have been proposed to automatically reconstruct the code representation of a binary instead of manually crafting specifics of the analysis algorithm. However, the existing approaches utilizing machine learning are still specialized to solve one domain of problems, rendering recreation of models for different types of binary analysis. In this paper, we propose DeepSemantic utilizing BERT in producing the semantic-aware code representation of a binary code. To this end, we introduce well-balanced instruction normalization that holds rich information for each of instructions yet minimizing an out-of-vocabulary (OOV) problem. DeepSemantic has been carefully designed based on our study with large swaths of binaries. Besides, DeepSemantic leverages the essence of the BERT architecture into re-purposing a pre-trained generic model that is readily available as a one-time processing, followed by quickly applying specific downstream tasks with a fine-tuning process. We demonstrate DeepSemantic with two downstream tasks, namely, binary similarity comparison and compiler provenance (i.e., compiler and optimization level) prediction. Our experimental results show that the binary similarity model outperforms two state-of-the-art binary similarity tools, DeepBinDiff and SAFE, 49.84% and 15.83% on average, respectively.