 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Mixture-of-Experts Framework for Discrete-Time Survival Analysis
Oct 29, 2025Survival analysis is a task to model the time until an event of interest occurs, widely used in clinical and biomedical research. A key challenge is to model patient heterogeneity while also adapting risk predictions to both individual characteristics and temporal dynamics. We propose a dual mixture-of-experts (MoE) framework for discrete-time survival analysis. Our approach combines a feature-encoder MoE for subgroup-aware representation learning with a hazard MoE that leverages patient features and time embeddings to capture temporal dynamics. This dual-MoE design flexibly integrates with existing deep learning based survival pipelines. On METABRIC and GBSG breast cancer datasets, our method consistently improves performance, boosting the time-dependent C-index up to 0.04 on the test sets, and yields further gains when incorporated into the Consurv framework.
Is user feedback always informative? Retrieval Latent Defending for Semi-Supervised Domain Adaptation without Source Data
Jul 22, 2024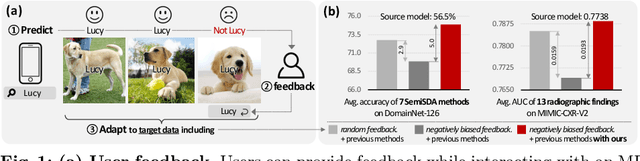

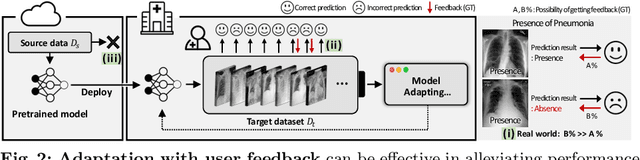
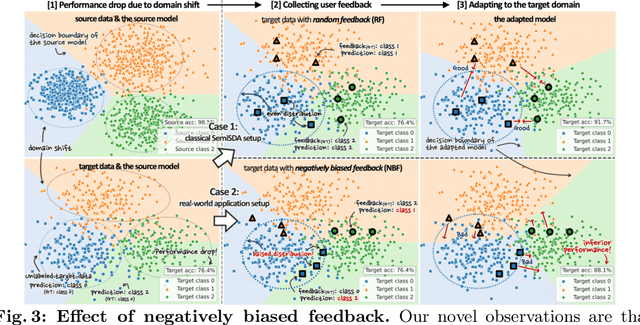
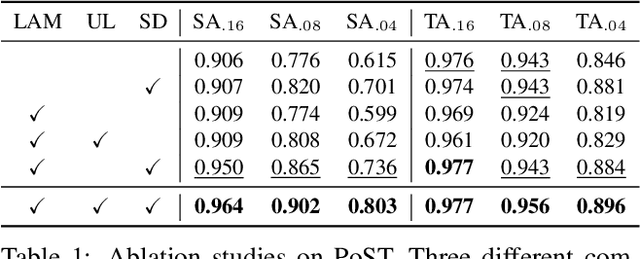
This paper aims to adapt the source model to the target environment, leveraging small user feedback (i.e., labeled target data) readily available in real-world applications. We find that existing semi-supervised domain adaptation (SemiSDA) methods often suffer from poorly improved adaptation performance when directly utilizing such feedback data, as shown in Figure 1. We analyze this phenomenon via a novel concept called Negatively Biased Feedback (NBF), which stems from the observation that user feedback is more likely for data points where the model produces incorrect predictions. To leverage this feedback while avoiding the issue, we propose a scalable adapting approach, Retrieval Latent Defending. This approach helps existing SemiSDA methods to adapt the model with a balanced supervised signal by utilizing latent defending samples throughout the adaptation process. We demonstrate the problem caused by NBF and the efficacy of our approach across various benchmarks, including image classification, semantic segmentation, and a real-world medical imaging application. Our extensive experiments reveal that integrating our approach with multiple state-of-the-art SemiSDA methods leads to significant performance improvements.
OOOE: Only-One-Object-Exists Assumption to Find Very Small Objects in Chest Radiographs
Oct 13, 2022The accurate localization of inserted medical tubes and parts of human anatomy is a common problem when analyzing chest radiographs and something deep neural networks could potentially automate. However, many foreign objects like tubes and various anatomical structures are small in comparison to the entire chest X-ray, which leads to severely unbalanced data and makes training deep neural networks difficult. In this paper, we present a simple yet effective `Only-One-Object-Exists' (OOOE) assumption to improve the deep network's ability to localize small landmarks in chest radiographs. The OOOE enables us to recast the localization problem as a classification problem and we can replace commonly used continuous regression techniques with a multi-class discrete objective. We validate our approach using a large scale proprietary dataset of over 100K radiographs as well as publicly available RANZCR-CLiP Kaggle Challenge dataset and show that our method consistently outperforms commonly used regression-based detection models as well as commonly used pixel-wise classification methods. Additionally, we find that the method using the OOOE assumption generalizes to multiple detection problems in chest X-rays and the resulting model shows state-of-the-art performance on detecting various tube tips inserted to the patient as well as patient anatomy.
Polygonal Point Set Tracking
May 30, 2021
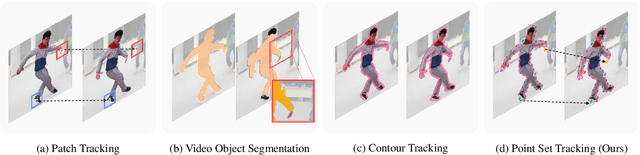
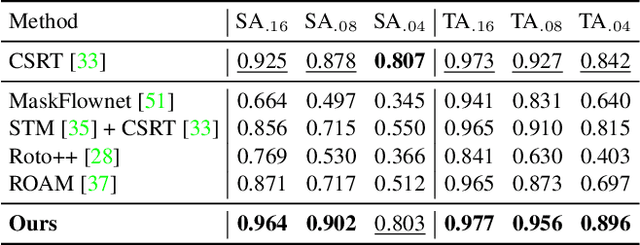
In this paper, we propose a novel learning-based polygonal point set tracking method. Compared to existing video object segmentation~(VOS) methods that propagate pixel-wise object mask information, we propagate a polygonal point set over frames. Specifically, the set is defined as a subset of points in the target contour, and our goal is to track corresponding points on the target contour. Those outputs enable us to apply various visual effects such as motion tracking, part deformation, and texture mapping. To this end, we propose a new method to track the corresponding points between frames by the global-local alignment with delicately designed losses and regularization terms. We also introduce a novel learning strategy using synthetic and VOS datasets that makes it possible to tackle the problem without developing the point correspondence dataset. Since the existing datasets are not suitable to validate our method, we build a new polygonal point set tracking dataset and demonstrate the superior performance of our method over the baselines and existing contour-based VOS methods. In addition, we present visual-effects applications of our method on part distortion and text mapping.
DMV: Visual Object Tracking via Part-level Dense Memory and Voting-based Retrieval
Mar 20, 2020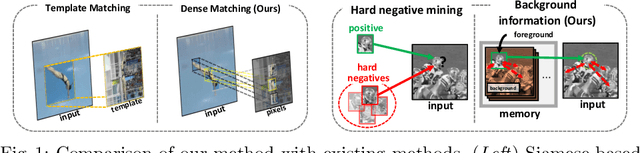

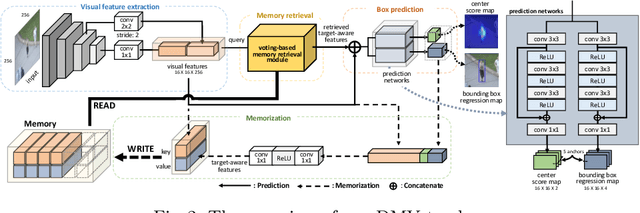
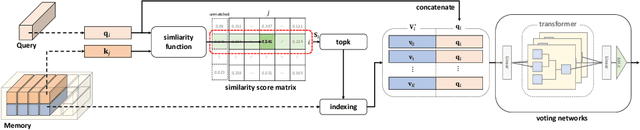
We propose a novel memory-based tracker via part-level dense memory and voting-based retrieval, called DMV. Since deep learning techniques have been introduced to the tracking field, Siamese trackers have attracted many researchers due to the balance between speed and accuracy. However, most of them are based on a single template matching, which limits the performance as it restricts the accessible in-formation to the initial target features. In this paper, we relieve this limitation by maintaining an external memory that saves the tracking record. Part-level retrieval from the memory also liberates the information from the template and allows our tracker to better handle the challenges such as appearance changes and occlusions. By updating the memory during tracking, the representative power for the target object can be enhanced without online learning. We also propose a novel voting mechanism for the memory reading to filter out unreliable information in the memory. We comprehensively evaluate our tracker on OTB-100,TrackingNet, GOT-10k, LaSOT, and UAV123, which show that our method yields comparable results to the state-of-the-art methods.