 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs user feedback always informative? Retrieval Latent Defending for Semi-Supervised Domain Adaptation without Source Data
Jul 22, 2024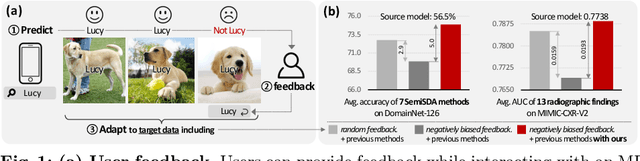

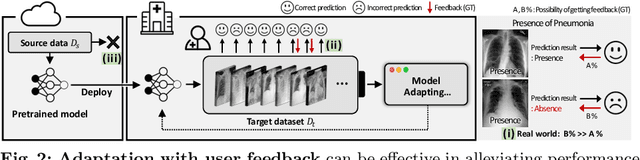
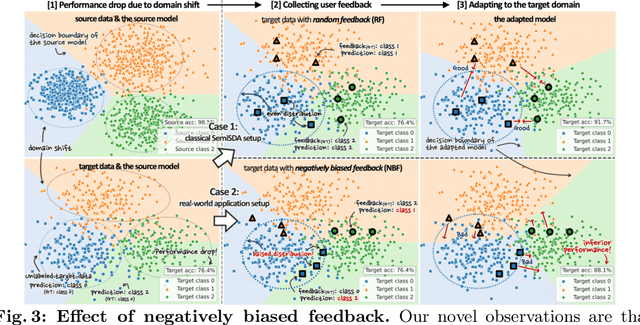
This paper aims to adapt the source model to the target environment, leveraging small user feedback (i.e., labeled target data) readily available in real-world applications. We find that existing semi-supervised domain adaptation (SemiSDA) methods often suffer from poorly improved adaptation performance when directly utilizing such feedback data, as shown in Figure 1. We analyze this phenomenon via a novel concept called Negatively Biased Feedback (NBF), which stems from the observation that user feedback is more likely for data points where the model produces incorrect predictions. To leverage this feedback while avoiding the issue, we propose a scalable adapting approach, Retrieval Latent Defending. This approach helps existing SemiSDA methods to adapt the model with a balanced supervised signal by utilizing latent defending samples throughout the adaptation process. We demonstrate the problem caused by NBF and the efficacy of our approach across various benchmarks, including image classification, semantic segmentation, and a real-world medical imaging application. Our extensive experiments reveal that integrating our approach with multiple state-of-the-art SemiSDA methods leads to significant performance improvements.
EcoTTA: Memory-Efficient Continual Test-time Adaptation via Self-distilled Regularization
Mar 13, 2023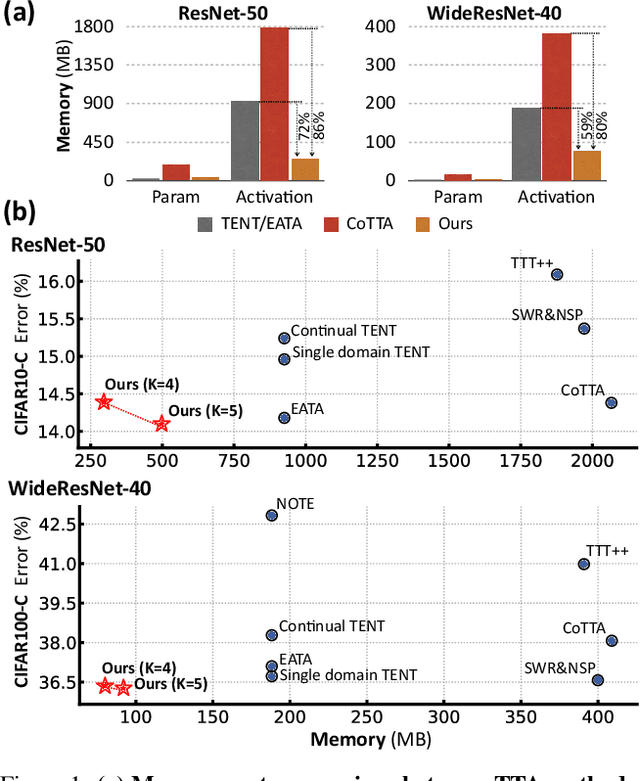
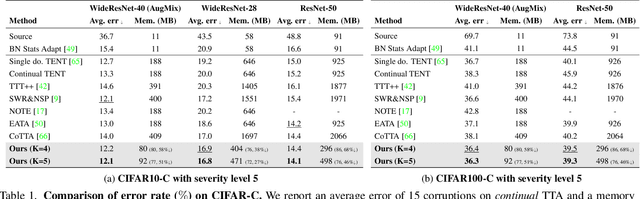

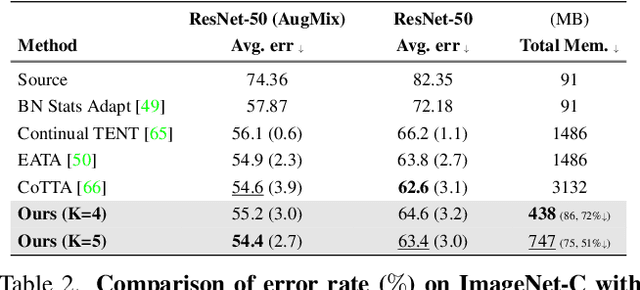
This paper presents a simple yet effective approach that improves continual test-time adaptation (TTA) in a memory-efficient manner. TTA may primarily be conducted on edge devices with limited memory, so reducing memory is crucial but has been overlooked in previous TTA studies. In addition, long-term adaptation often leads to catastrophic forgetting and error accumulation, which hinders applying TTA in real-world deployments. Our approach consists of two components to address these issues. First, we present lightweight meta networks that can adapt the frozen original networks to the target domain. This novel architecture minimizes memory consumption by decreasing the size of intermediate activations required for backpropagation. Second, our novel self-distilled regularization controls the output of the meta networks not to deviate significantly from the output of the frozen original networks, thereby preserving well-trained knowledge from the source domain. Without additional memory, this regularization prevents error accumulation and catastrophic forgetting, resulting in stable performance even in long-term test-time adaptation. We demonstrate that our simple yet effective strategy outperforms other state-of-the-art methods on various benchmarks for image classification and semantic segmentation tasks. Notably, our proposed method with ResNet-50 and WideResNet-40 takes 86% and 80% less memory than the recent state-of-the-art method, CoTTA.
CD-TTA: Compound Domain Test-time Adaptation for Semantic Segmentation
Dec 16, 2022



Test-time adaptation (TTA) has attracted significant attention due to its practical properties which enable the adaptation of a pre-trained model to a new domain with only target dataset during the inference stage. Prior works on TTA assume that the target dataset comes from the same distribution and thus constitutes a single homogeneous domain. In practice, however, the target domain can contain multiple homogeneous domains which are sufficiently distinctive from each other and those multiple domains might occur cyclically. Our preliminary investigation shows that domain-specific TTA outperforms vanilla TTA treating compound domain (CD) as a single one. However, domain labels are not available for CD, which makes domain-specific TTA not practicable. To this end, we propose an online clustering algorithm for finding pseudo-domain labels to obtain similar benefits as domain-specific configuration and accumulating knowledge of cyclic domains effectively. Moreover, we observe that there is a significant discrepancy in terms of prediction quality among samples, especially in the CD context. This further motivates us to boost its performance with gradient denoising by considering the image-wise similarity with the source distribution. Overall, the key contribution of our work lies in proposing a highly significant new task compound domain test-time adaptation (CD-TTA) on semantic segmentation as well as providing a strong baseline to facilitate future works to benchmark.
A Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond
Jul 30, 2022

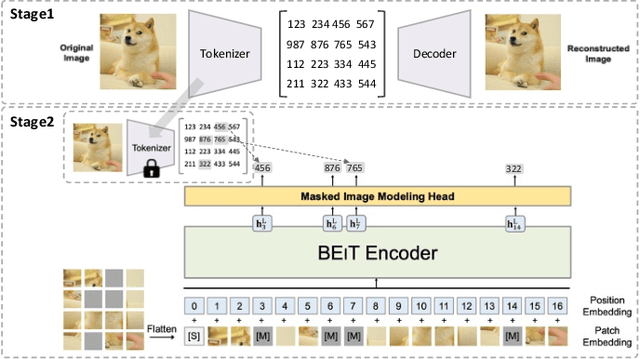
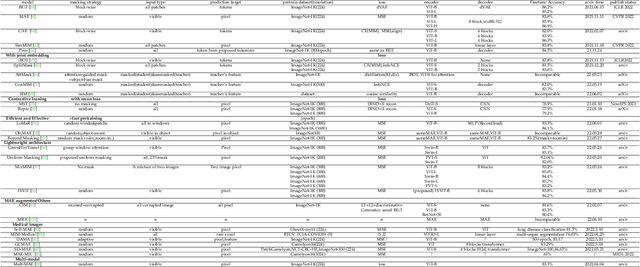
Masked autoencoders are scalable vision learners, as the title of MAE \cite{he2022masked}, which suggests that self-supervised learning (SSL) in vision might undertake a similar trajectory as in NLP. Specifically, generative pretext tasks with the masked prediction (e.g., BERT) have become a de facto standard SSL practice in NLP. By contrast, early attempts at generative methods in vision have been buried by their discriminative counterparts (like contrastive learning); however, the success of mask image modeling has revived the masking autoencoder (often termed denoising autoencoder in the past). As a milestone to bridge the gap with BERT in NLP, masked autoencoder has attracted unprecedented attention for SSL in vision and beyond. This work conducts a comprehensive survey of masked autoencoders to shed insight on a promising direction of SSL. As the first to review SSL with masked autoencoders, this work focuses on its application in vision by discussing its historical developments, recent progress, and implications for diverse applications.