 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Agents: A Post-Training Procedure for Internalized Multi-Agent Debate
Apr 27, 2026Multi-agent debate has been shown to improve reasoning in large language models (LLMs). However, it is compute-intensive, requiring generation of long transcripts before answering questions. To address this inefficiency, we develop a framework that distills multi-agent debate into a single LLM through a two-stage fine-tuning pipeline combining debate structure learning with internalization via dynamic reward scheduling and length clipping. Across multiple models and benchmarks, our internalized models match or exceed explicit multi-agent debate performance using up to 93% fewer tokens. We then investigate the mechanistic basis of this capability through activation steering, finding that internalization creates agent-specific subspaces: interpretable directions in activation space corresponding to different agent perspectives. We further demonstrate a practical application: by instilling malicious agents into the LLM through internalized debate, then applying negative steering to suppress them, we show that distillation makes harmful behaviors easier to localize and control with smaller reductions in general performance compared to steering base models. Our findings offer a new perspective for understanding multi-agent capabilities in distilled models and provide practical guidelines for controlling internalized reasoning behaviors. Code available at https://github.com/johnsk95/latent_agents
A Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond
Jul 30, 2022

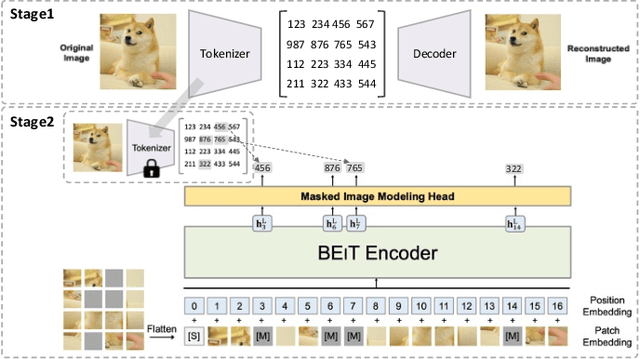
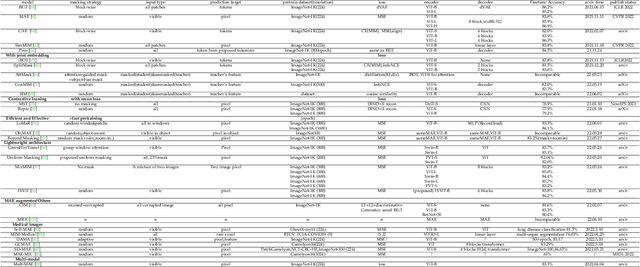
Masked autoencoders are scalable vision learners, as the title of MAE \cite{he2022masked}, which suggests that self-supervised learning (SSL) in vision might undertake a similar trajectory as in NLP. Specifically, generative pretext tasks with the masked prediction (e.g., BERT) have become a de facto standard SSL practice in NLP. By contrast, early attempts at generative methods in vision have been buried by their discriminative counterparts (like contrastive learning); however, the success of mask image modeling has revived the masking autoencoder (often termed denoising autoencoder in the past). As a milestone to bridge the gap with BERT in NLP, masked autoencoder has attracted unprecedented attention for SSL in vision and beyond. This work conducts a comprehensive survey of masked autoencoders to shed insight on a promising direction of SSL. As the first to review SSL with masked autoencoders, this work focuses on its application in vision by discussing its historical developments, recent progress, and implications for diverse applications.
Using Self-Supervised Pretext Tasks for Active Learning
Jan 19, 2022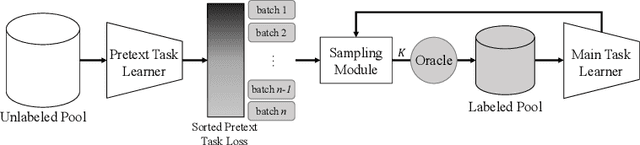
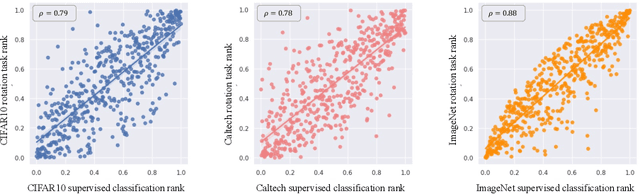
Labeling a large set of data is expensive. Active learning aims to tackle this problem by asking to annotate only the most informative data from the unlabeled set. We propose a novel active learning approach that utilizes self-supervised pretext tasks and a unique data sampler to select data that are both difficult and representative. We discover that the loss of a simple self-supervised pretext task, such as rotation prediction, is closely correlated to the downstream task loss. The pretext task learner is trained on the unlabeled set, and the unlabeled data are sorted and grouped into batches by their pretext task losses. In each iteration, the main task model is used to sample the most uncertain data in a batch to be annotated. We evaluate our method on various image classification and segmentation benchmarks and achieve compelling performances on CIFAR10, Caltech-101, ImageNet, and CityScapes.
Incremental Object Grounding Using Scene Graphs
Jan 06, 2022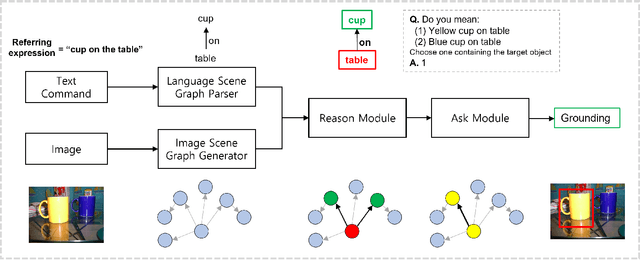


Object grounding tasks aim to locate the target object in an image through verbal communications. Understanding human command is an important process needed for effective human-robot communication. However, this is challenging because human commands can be ambiguous and erroneous. This paper aims to disambiguate the human's referring expressions by allowing the agent to ask relevant questions based on semantic data obtained from scene graphs. We test if our agent can use relations between objects from a scene graph to ask semantically relevant questions that can disambiguate the original user command. In this paper, we present Incremental Grounding using Scene Graphs (IGSG), a disambiguation model that uses semantic data from an image scene graph and linguistic structures from a language scene graph to ground objects based on human command. Compared to the baseline, IGSG shows promising results in complex real-world scenes where there are multiple identical target objects. IGSG can effectively disambiguate ambiguous or wrong referring expressions by asking disambiguating questions back to the user.