 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Language-Model-Guided State Estimation for Partially Observable Task and Motion Planning
Mar 04, 2026Robot planning in partially observable environments, where not all objects are known or visible, is a challenging problem, as it requires reasoning under uncertainty through partially observable Markov decision processes. During the execution of a computed plan, a robot may unexpectedly observe task-irrelevant objects, which are typically ignored by naive planners. In this work, we propose incorporating two types of common-sense knowledge: (1) certain objects are more likely to be found in specific locations; and (2) similar objects are likely to be co-located, while dissimilar objects are less likely to be found together. Manually engineering such knowledge is complex, so we explore leveraging the powerful common-sense reasoning capabilities of large language models (LLMs). Our planning and execution framework, CoCo-TAMP, introduces a hierarchical state estimation that uses LLM-guided information to shape the belief over task-relevant objects, enabling efficient solutions to long-horizon task and motion planning problems. In experiments, CoCo-TAMP achieves an average reduction of 62.7 in planning and execution time in simulation, and 72.6 in real-world demonstrations, compared to a baseline that does not incorporate either type of common-sense knowledge.
Incremental Object Grounding Using Scene Graphs
Jan 06, 2022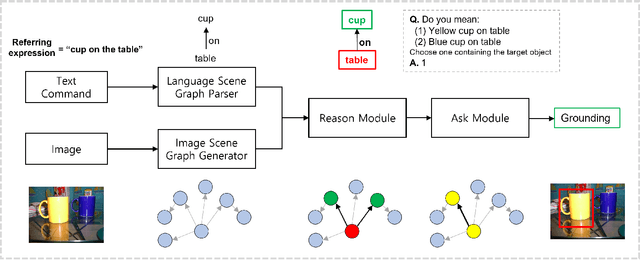


Object grounding tasks aim to locate the target object in an image through verbal communications. Understanding human command is an important process needed for effective human-robot communication. However, this is challenging because human commands can be ambiguous and erroneous. This paper aims to disambiguate the human's referring expressions by allowing the agent to ask relevant questions based on semantic data obtained from scene graphs. We test if our agent can use relations between objects from a scene graph to ask semantically relevant questions that can disambiguate the original user command. In this paper, we present Incremental Grounding using Scene Graphs (IGSG), a disambiguation model that uses semantic data from an image scene graph and linguistic structures from a language scene graph to ground objects based on human command. Compared to the baseline, IGSG shows promising results in complex real-world scenes where there are multiple identical target objects. IGSG can effectively disambiguate ambiguous or wrong referring expressions by asking disambiguating questions back to the user.