 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Masked Autoencoder for Self-supervised Learning in Vision and Beyond
Paper and Code
Jul 30, 2022

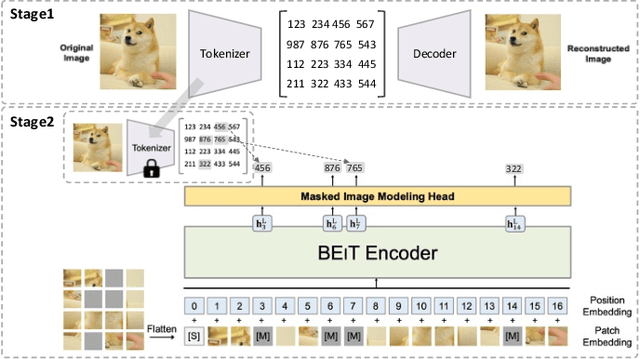
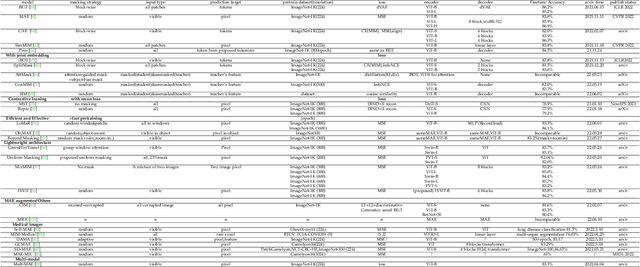
Masked autoencoders are scalable vision learners, as the title of MAE \cite{he2022masked}, which suggests that self-supervised learning (SSL) in vision might undertake a similar trajectory as in NLP. Specifically, generative pretext tasks with the masked prediction (e.g., BERT) have become a de facto standard SSL practice in NLP. By contrast, early attempts at generative methods in vision have been buried by their discriminative counterparts (like contrastive learning); however, the success of mask image modeling has revived the masking autoencoder (often termed denoising autoencoder in the past). As a milestone to bridge the gap with BERT in NLP, masked autoencoder has attracted unprecedented attention for SSL in vision and beyond. This work conducts a comprehensive survey of masked autoencoders to shed insight on a promising direction of SSL. As the first to review SSL with masked autoencoders, this work focuses on its application in vision by discussing its historical developments, recent progress, and implications for diverse applications.