 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Assisted Stitching for Offline Hierarchical Reinforcement Learning
Jun 09, 2025Existing offline hierarchical reinforcement learning methods rely on high-level policy learning to generate subgoal sequences. However, their efficiency degrades as task horizons increase, and they lack effective strategies for stitching useful state transitions across different trajectories. We propose Graph-Assisted Stitching (GAS), a novel framework that formulates subgoal selection as a graph search problem rather than learning an explicit high-level policy. By embedding states into a Temporal Distance Representation (TDR) space, GAS clusters semantically similar states from different trajectories into unified graph nodes, enabling efficient transition stitching. A shortest-path algorithm is then applied to select subgoal sequences within the graph, while a low-level policy learns to reach the subgoals. To improve graph quality, we introduce the Temporal Efficiency (TE) metric, which filters out noisy or inefficient transition states, significantly enhancing task performance. GAS outperforms prior offline HRL methods across locomotion, navigation, and manipulation tasks. Notably, in the most stitching-critical task, it achieves a score of 88.3, dramatically surpassing the previous state-of-the-art score of 1.0. Our source code is available at: https://github.com/qortmdgh4141/GAS.
Pretraining a Shared Q-Network for Data-Efficient Offline Reinforcement Learning
May 09, 2025Offline reinforcement learning (RL) aims to learn a policy from a static dataset without further interactions with the environment. Collecting sufficiently large datasets for offline RL is exhausting since this data collection requires colossus interactions with environments and becomes tricky when the interaction with the environment is restricted. Hence, how an agent learns the best policy with a minimal static dataset is a crucial issue in offline RL, similar to the sample efficiency problem in online RL. In this paper, we propose a simple yet effective plug-and-play pretraining method to initialize a feature of a $Q$-network to enhance data efficiency in offline RL. Specifically, we introduce a shared $Q$-network structure that outputs predictions of the next state and $Q$-value. We pretrain the shared $Q$-network through a supervised regression task that predicts a next state and trains the shared $Q$-network using diverse offline RL methods. Through extensive experiments, we empirically demonstrate that our method enhances the performance of existing popular offline RL methods on the D4RL, Robomimic and V-D4RL benchmarks. Furthermore, we show that our method significantly boosts data-efficient offline RL across various data qualities and data distributions trough D4RL and ExoRL benchmarks. Notably, our method adapted with only 10% of the dataset outperforms standard algorithms even with full datasets.
CyberBOT: Towards Reliable Cybersecurity Education via Ontology-Grounded Retrieval Augmented Generation
Apr 01, 2025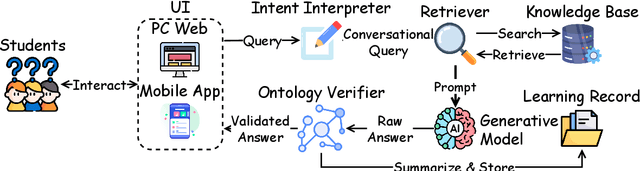
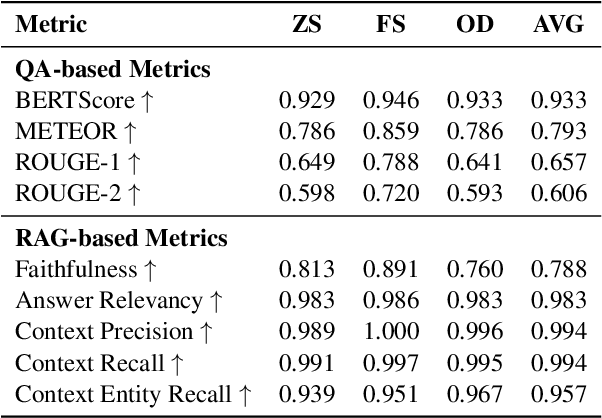

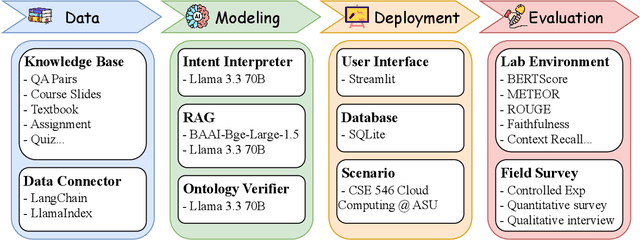
Advancements in large language models (LLMs) have enabled the development of intelligent educational tools that support inquiry-based learning across technical domains. In cybersecurity education, where accuracy and safety are paramount, systems must go beyond surface-level relevance to provide information that is both trustworthy and domain-appropriate. To address this challenge, we introduce CyberBOT, a question-answering chatbot that leverages a retrieval-augmented generation (RAG) pipeline to incorporate contextual information from course-specific materials and validate responses using a domain-specific cybersecurity ontology. The ontology serves as a structured reasoning layer that constrains and verifies LLM-generated answers, reducing the risk of misleading or unsafe guidance. CyberBOT has been deployed in a large graduate-level course at Arizona State University (ASU), where more than one hundred students actively engage with the system through a dedicated web-based platform. Computational evaluations in lab environments highlight the potential capacity of CyberBOT, and a forthcoming field study will evaluate its pedagogical impact. By integrating structured domain reasoning with modern generative capabilities, CyberBOT illustrates a promising direction for developing reliable and curriculum-aligned AI applications in specialized educational contexts.
Generalizing AI-driven Assessment of Immunohistochemistry across Immunostains and Cancer Types: A Universal Immunohistochemistry Analyzer
Jul 30, 2024Despite advancements in methodologies, immunohistochemistry (IHC) remains the most utilized ancillary test for histopathologic and companion diagnostics in targeted therapies. However, objective IHC assessment poses challenges. Artificial intelligence (AI) has emerged as a potential solution, yet its development requires extensive training for each cancer and IHC type, limiting versatility. We developed a Universal IHC (UIHC) analyzer, an AI model for interpreting IHC images regardless of tumor or IHC types, using training datasets from various cancers stained for PD-L1 and/or HER2. This multi-cohort trained model outperforms conventional single-cohort models in interpreting unseen IHCs (Kappa score 0.578 vs. up to 0.509) and consistently shows superior performance across different positive staining cutoff values. Qualitative analysis reveals that UIHC effectively clusters patches based on expression levels. The UIHC model also quantitatively assesses c-MET expression with MET mutations, representing a significant advancement in AI application in the era of personalized medicine and accumulating novel biomarkers.
Unsupervised Change Detection Based on Image Reconstruction Loss
Apr 05, 2022
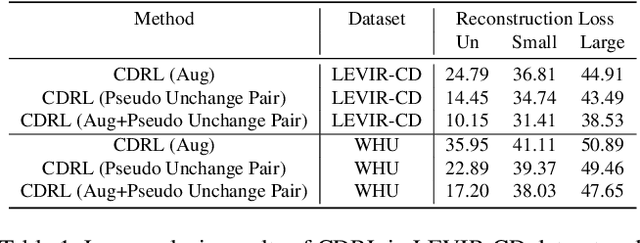


To train the change detector, bi-temporal images taken at different times in the same area are used. However, collecting labeled bi-temporal images is expensive and time consuming. To solve this problem, various unsupervised change detection methods have been proposed, but they still require unlabeled bi-temporal images. In this paper, we propose unsupervised change detection based on image reconstruction loss using only unlabeled single temporal single image. The image reconstruction model is trained to reconstruct the original source image by receiving the source image and the photometrically transformed source image as a pair. During inference, the model receives bi-temporal images as the input, and tries to reconstruct one of the inputs. The changed region between bi-temporal images shows high reconstruction loss. Our change detector showed significant performance in various change detection benchmark datasets even though only a single temporal single source image was used. The code and trained models will be publicly available for reproducibility.
Using Self-Supervised Pretext Tasks for Active Learning
Jan 19, 2022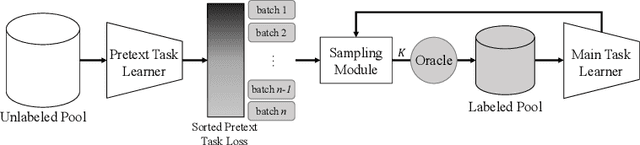
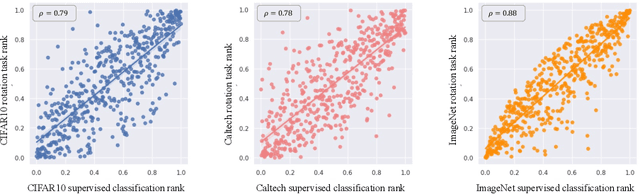
Labeling a large set of data is expensive. Active learning aims to tackle this problem by asking to annotate only the most informative data from the unlabeled set. We propose a novel active learning approach that utilizes self-supervised pretext tasks and a unique data sampler to select data that are both difficult and representative. We discover that the loss of a simple self-supervised pretext task, such as rotation prediction, is closely correlated to the downstream task loss. The pretext task learner is trained on the unlabeled set, and the unlabeled data are sorted and grouped into batches by their pretext task losses. In each iteration, the main task model is used to sample the most uncertain data in a batch to be annotated. We evaluate our method on various image classification and segmentation benchmarks and achieve compelling performances on CIFAR10, Caltech-101, ImageNet, and CityScapes.
Studying the Effects of Self-Attention for Medical Image Analysis
Sep 02, 2021


When the trained physician interprets medical images, they understand the clinical importance of visual features. By applying cognitive attention, they apply greater focus onto clinically relevant regions while disregarding unnecessary features. The use of computer vision to automate the classification of medical images is widely studied. However, the standard convolutional neural network (CNN) does not necessarily employ subconscious feature relevancy evaluation techniques similar to the trained medical specialist and evaluates features more generally. Self-attention mechanisms enable CNNs to focus more on semantically important regions or aggregated relevant context with long-range dependencies. By using attention, medical image analysis systems can potentially become more robust by focusing on more important clinical feature regions. In this paper, we provide a comprehensive comparison of various state-of-the-art self-attention mechanisms across multiple medical image analysis tasks. Through both quantitative and qualitative evaluations along with a clinical user-centric survey study, we aim to provide a deeper understanding of the effects of self-attention in medical computer vision tasks.
Exploiting Features with Split-and-Share Module
Aug 11, 2021



Deep convolutional neural networks (CNNs) have shown state-of-the-art performances in various computer vision tasks. Advances on CNN architectures have focused mainly on designing convolutional blocks of the feature extractors, but less on the classifiers that exploit extracted features. In this work, we propose Split-and-Share Module (SSM),a classifier that splits a given feature into parts, which are partially shared by multiple sub-classifiers. Our intuition is that the more the features are shared, the more common they will become, and SSM can encourage such structural characteristics in the split features. SSM can be easily integrated into any architecture without bells and whistles. We have extensively validated the efficacy of SSM on ImageNet-1K classification task, andSSM has shown consistent and significant improvements over baseline architectures. In addition, we analyze the effect of SSM using the Grad-CAM visualization.
Learning Visual Context by Comparison
Jul 15, 2020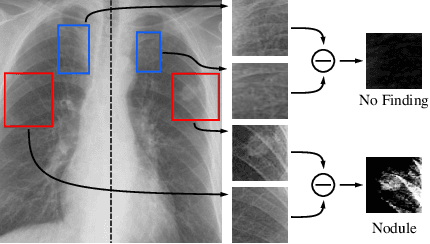

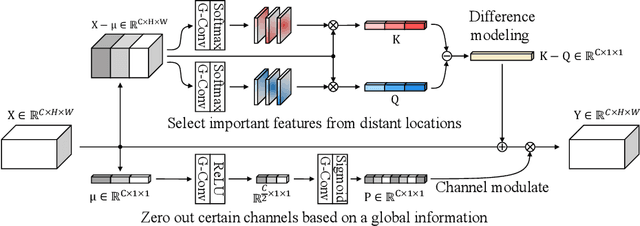
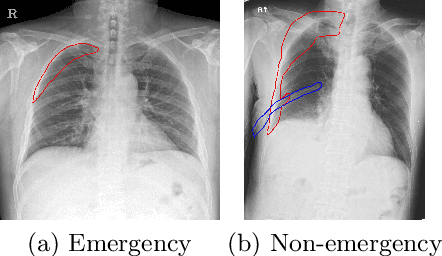
Finding diseases from an X-ray image is an important yet highly challenging task. Current methods for solving this task exploit various characteristics of the chest X-ray image, but one of the most important characteristics is still missing: the necessity of comparison between related regions in an image. In this paper, we present Attend-and-Compare Module (ACM) for capturing the difference between an object of interest and its corresponding context. We show that explicit difference modeling can be very helpful in tasks that require direct comparison between locations from afar. This module can be plugged into existing deep learning models. For evaluation, we apply our module to three chest X-ray recognition tasks and COCO object detection & segmentation tasks and observe consistent improvements across tasks. The code is available at https://github.com/mk-minchul/attend-and-compare.
Sequential Feature Filtering Classifier
Jun 21, 2020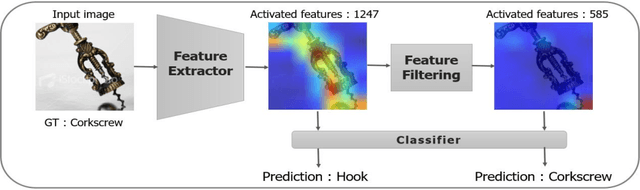



We propose Sequential Feature Filtering Classifier (FFC), a simple but effective classifier for convolutional neural networks (CNNs). With sequential LayerNorm and ReLU, FFC zeroes out low-activation units and preserves high-activation units. The sequential feature filtering process generates multiple features, which are fed into a shared classifier for multiple outputs. FFC can be applied to any CNNs with a classifier, and significantly improves performances with negligible overhead. We extensively validate the efficacy of FFC on various tasks: ImageNet-1K classification, MS COCO detection, Cityscapes segmentation, and HMDB51 action recognition. Moreover, we empirically show that FFC can further improve performances upon other techniques, including attention modules and augmentation techniques. The code and models will be publicly available.