 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitchLight: Co-design of Physics-driven Architecture and Pre-training Framework for Human Portrait Relighting
Feb 29, 2024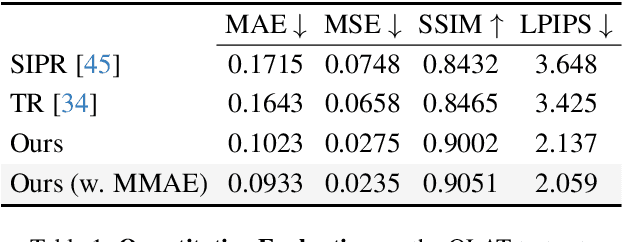


We introduce a co-designed approach for human portrait relighting that combines a physics-guided architecture with a pre-training framework. Drawing on the Cook-Torrance reflectance model, we have meticulously configured the architecture design to precisely simulate light-surface interactions. Furthermore, to overcome the limitation of scarce high-quality lightstage data, we have developed a self-supervised pre-training strategy. This novel combination of accurate physical modeling and expanded training dataset establishes a new benchmark in relighting realism.
MHSAN: Multi-Head Self-Attention Network for Visual Semantic Embedding
Jan 11, 2020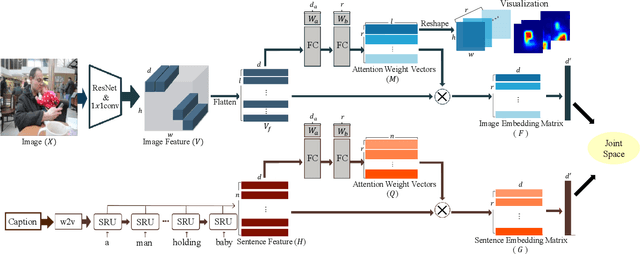
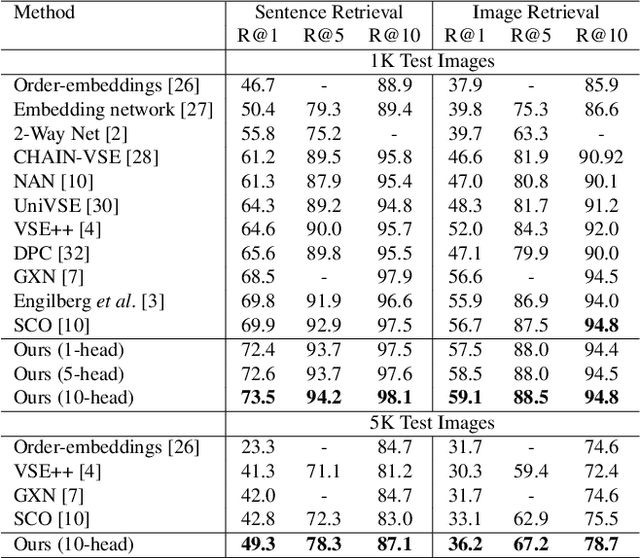
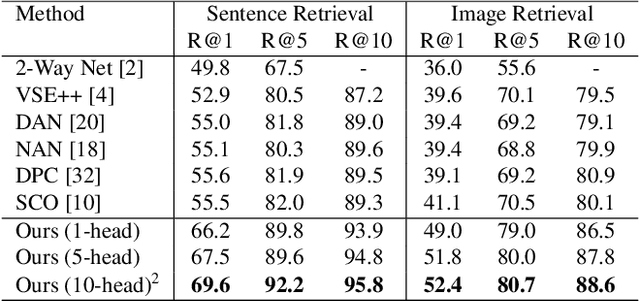

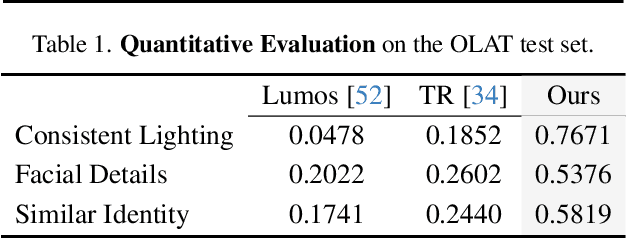
Visual-semantic embedding enables various tasks such as image-text retrieval, image captioning, and visual question answering. The key to successful visual-semantic embedding is to express visual and textual data properly by accounting for their intricate relationship. While previous studies have achieved much advance by encoding the visual and textual data into a joint space where similar concepts are closely located, they often represent data by a single vector ignoring the presence of multiple important components in an image or text. Thus, in addition to the joint embedding space, we propose a novel multi-head self-attention network to capture various components of visual and textual data by attending to important parts in data. Our approach achieves the new state-of-the-art results in image-text retrieval tasks on MS-COCO and Flicker30K datasets. Through the visualization of the attention maps that capture distinct semantic components at multiple positions in the image and the text, we demonstrate that our method achieves an effective and interpretable visual-semantic joint space.
Reducing Domain Gap via Style-Agnostic Networks
Oct 25, 2019
Deep learning models often fail to maintain their performance on new test domains. This problem has been regarded as a critical limitation of deep learning for real-world applications. One of the main causes of this vulnerability to domain changes is that the model tends to be biased to image styles (i.e. textures). To tackle this problem, we propose Style-Agnostic Networks (SagNets) to encourage the model to focus more on image contents (i.e. shapes) shared across domains but ignore image styles. SagNets consist of three novel techniques: style adversarial learning, style blending and style consistency learning, each of which prevents the model from making decisions based upon style information. In collaboration with a few additional training techniques and an ensemble of several model variants, the proposed method won the 1st place in the semi-supervised domain adaptation task of the Visual Domain Adaptation 2019 (VisDA-2019) Challenge.
Representation of White- and Black-Box Adversarial Examples in Deep Neural Networks and Humans: A Functional Magnetic Resonance Imaging Study
May 07, 2019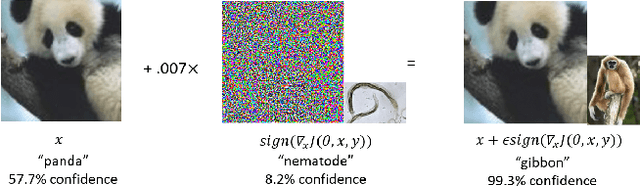
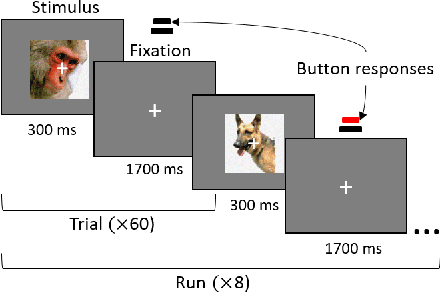
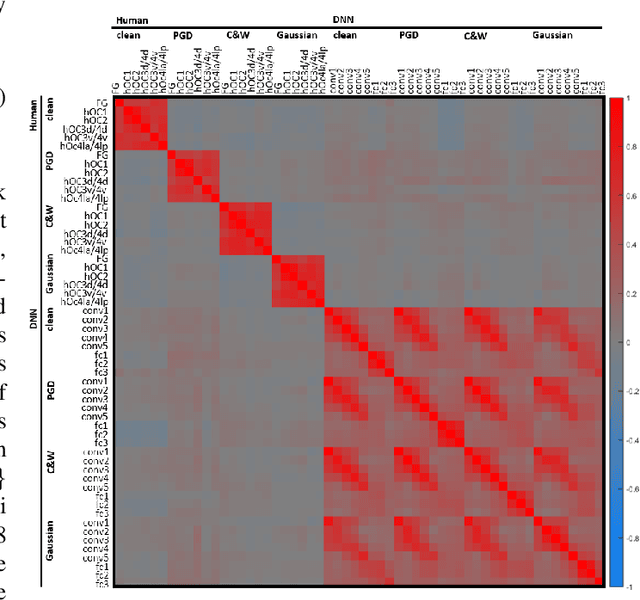
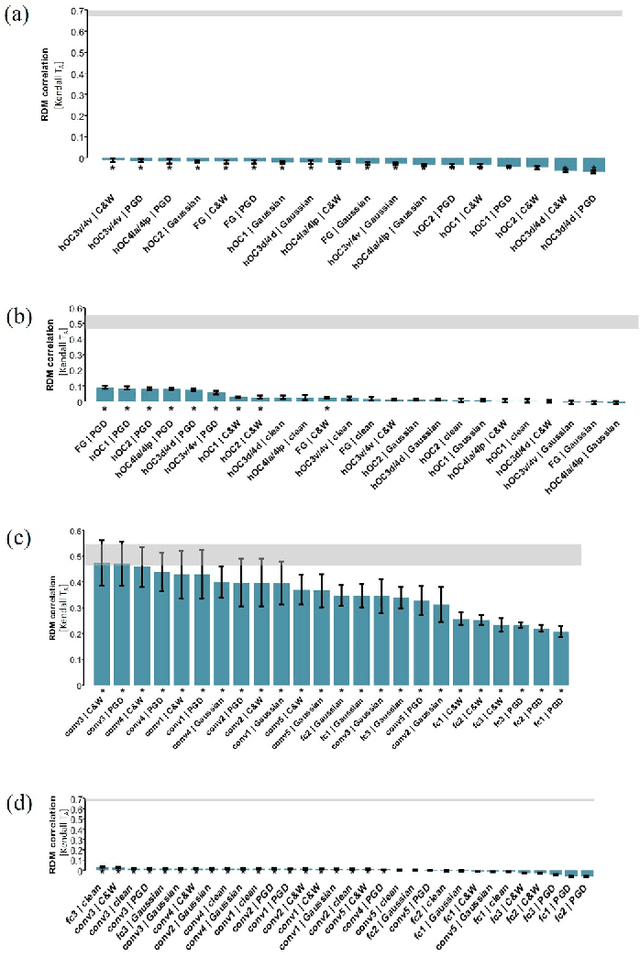
The recent success of brain-inspired deep neural networks (DNNs) in solving complex, high-level visual tasks has led to rising expectations for their potential to match the human visual system. However, DNNs exhibit idiosyncrasies that suggest their visual representation and processing might be substantially different from human vision. One limitation of DNNs is that they are vulnerable to adversarial examples, input images on which subtle, carefully designed noises are added to fool a machine classifier. The robustness of the human visual system against adversarial examples is potentially of great importance as it could uncover a key mechanistic feature that machine vision is yet to incorporate. In this study, we compare the visual representations of white- and black-box adversarial examples in DNNs and humans by leveraging functional magnetic resonance imaging (fMRI). We find a small but significant difference in representation patterns for different (i.e. white- versus black- box) types of adversarial examples for both humans and DNNs. However, human performance on categorical judgment is not degraded by noise regardless of the type unlike DNN. These results suggest that adversarial examples may be differentially represented in the human visual system, but unable to affect the perceptual experience.
An End-to-End Robot Architecture to Manipulate Non-Physical State Changes of Objects
Sep 27, 2016


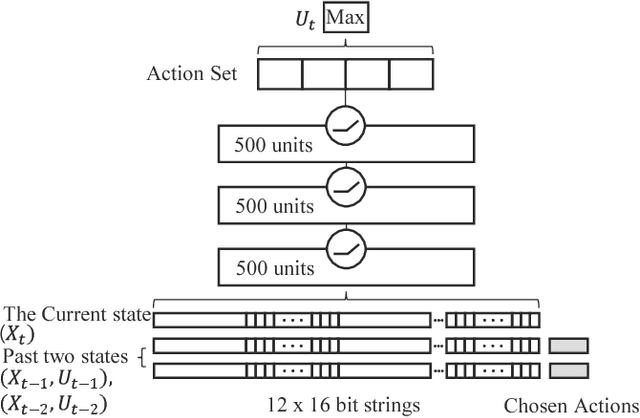
With the advance in robotic hardware and intelligent software, humanoid robot plays an important role in various tasks including service for human assistance and heavy job for hazardous industry. Recent advances in task learning enable humanoid robots to conduct dexterous manipulation tasks such as grasping objects and assembling parts of furniture. Operating objects without physical movements is an even more challenging task for humanoid robot because effects of actions may not be clearly seen in the physical configuration space and meaningful actions could be very complex in a long time horizon. As an example, playing a mobile game in a smart device has such challenges because both swipe actions and complex state transitions inside the smart devices in a long time horizon. In this paper, we solve this problem by introducing an integrated architecture which connects end-to-end dataflow from sensors to actuators in a humanoid robot to operate smart devices. We implement our integrated architecture in the Baxter Research Robot and experimentally demonstrate that the robot with our architecture could play a challenging mobile game, the 2048 game, as accurate as in a simulated environment.