 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Domain Gap via Style-Agnostic Networks
Oct 25, 2019
Deep learning models often fail to maintain their performance on new test domains. This problem has been regarded as a critical limitation of deep learning for real-world applications. One of the main causes of this vulnerability to domain changes is that the model tends to be biased to image styles (i.e. textures). To tackle this problem, we propose Style-Agnostic Networks (SagNets) to encourage the model to focus more on image contents (i.e. shapes) shared across domains but ignore image styles. SagNets consist of three novel techniques: style adversarial learning, style blending and style consistency learning, each of which prevents the model from making decisions based upon style information. In collaboration with a few additional training techniques and an ensemble of several model variants, the proposed method won the 1st place in the semi-supervised domain adaptation task of the Visual Domain Adaptation 2019 (VisDA-2019) Challenge.
SRM : A Style-based Recalibration Module for Convolutional Neural Networks
Mar 26, 2019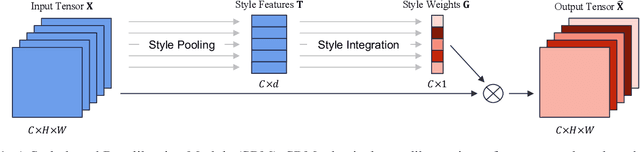
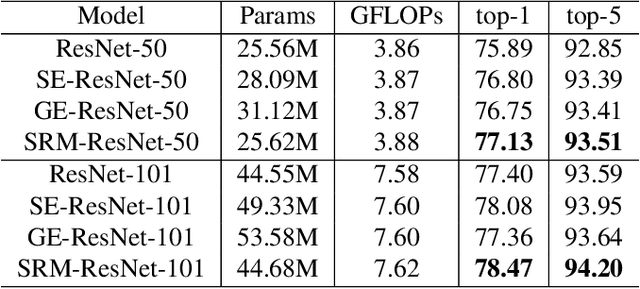
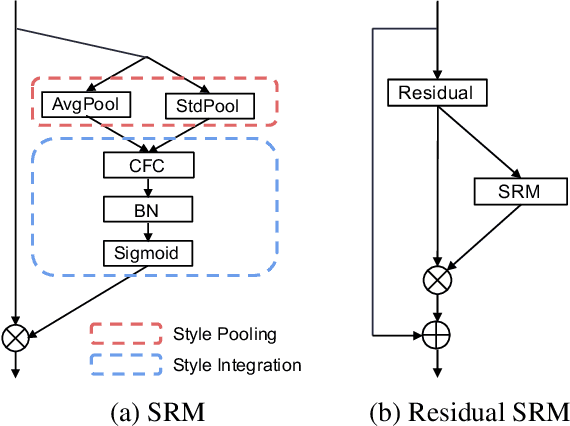
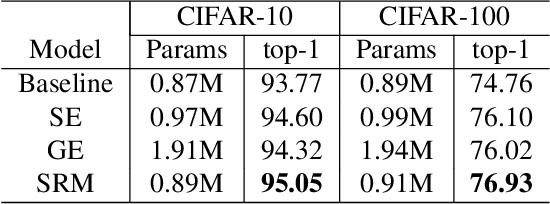
Following the advance of style transfer with Convolutional Neural Networks (CNNs), the role of styles in CNNs has drawn growing attention from a broader perspective. In this paper, we aim to fully leverage the potential of styles to improve the performance of CNNs in general vision tasks. We propose a Style-based Recalibration Module (SRM), a simple yet effective architectural unit, which adaptively recalibrates intermediate feature maps by exploiting their styles. SRM first extracts the style information from each channel of the feature maps by style pooling, then estimates per-channel recalibration weight via channel-independent style integration. By incorporating the relative importance of individual styles into feature maps, SRM effectively enhances the representational ability of a CNN. The proposed module is directly fed into existing CNN architectures with negligible overhead. We conduct comprehensive experiments on general image recognition as well as tasks related to styles, which verify the benefit of SRM over recent approaches such as Squeeze-and-Excitation (SE). To explain the inherent difference between SRM and SE, we provide an in-depth comparison of their representational properties.
Batch-Instance Normalization for Adaptively Style-Invariant Neural Networks
Oct 17, 2018
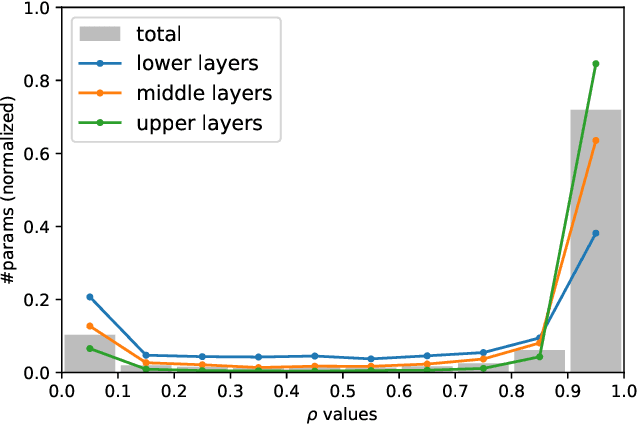
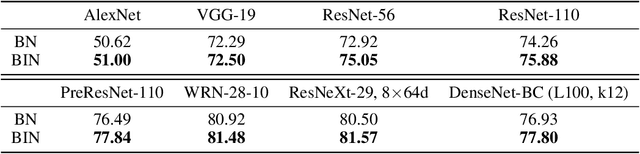

Real-world image recognition is often challenged by the variability of visual styles including object textures, lighting conditions, filter effects, etc. Although these variations have been deemed to be implicitly handled by more training data and deeper networks, recent advances in image style transfer suggest that it is also possible to explicitly manipulate the style information. Extending this idea to general visual recognition problems, we present Batch-Instance Normalization (BIN) to explicitly normalize unnecessary styles from images. Considering certain style features play an essential role in discriminative tasks, BIN learns to selectively normalize only disturbing styles while preserving useful styles. The proposed normalization module is easily incorporated into existing network architectures such as Residual Networks, and surprisingly improves the recognition performance in various scenarios. Furthermore, experiments verify that BIN effectively adapts to completely different tasks like object classification and style transfer, by controlling the trade-off between preserving and removing style variations. BIN can be implemented with only a few lines of code using popular deep learning frameworks.
Dual Attention Networks for Multimodal Reasoning and Matching
Mar 21, 2017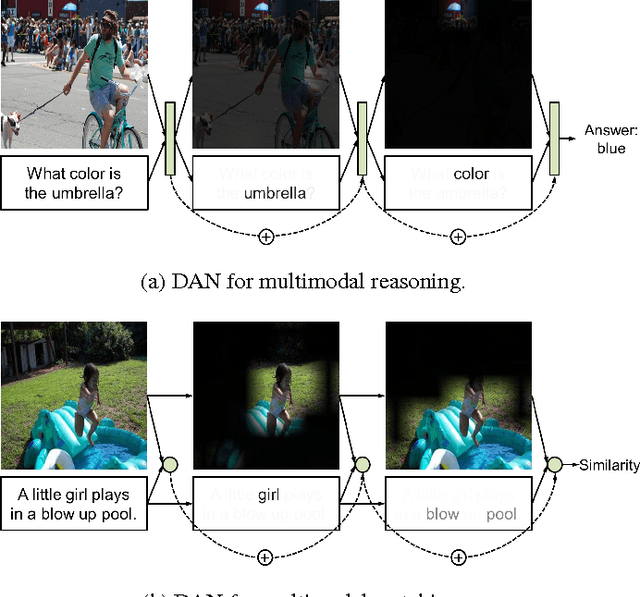
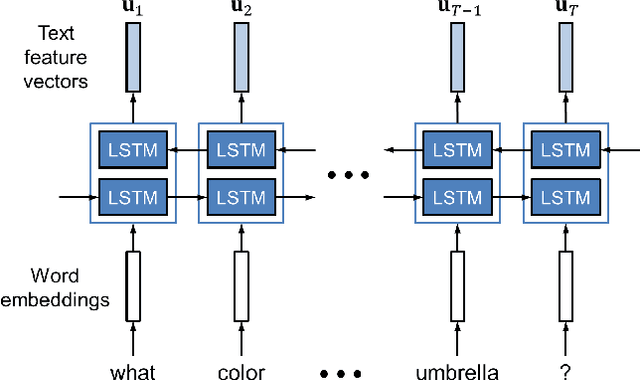
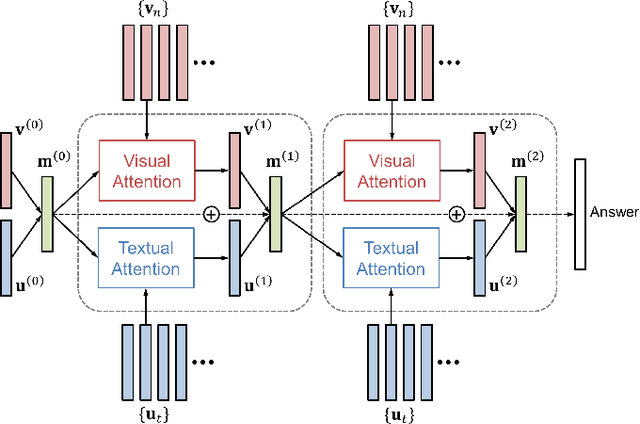
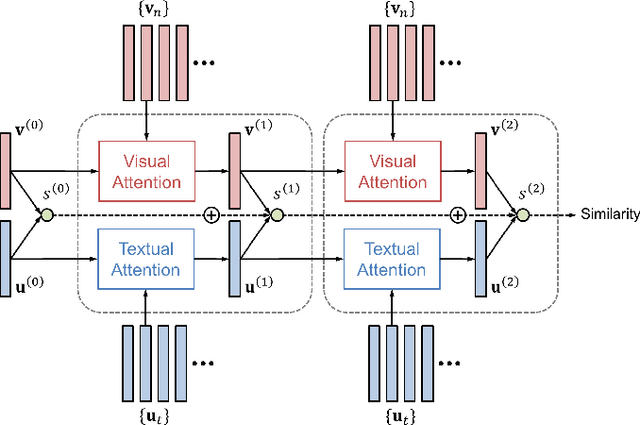
We propose Dual Attention Networks (DANs) which jointly leverage visual and textual attention mechanisms to capture fine-grained interplay between vision and language. DANs attend to specific regions in images and words in text through multiple steps and gather essential information from both modalities. Based on this framework, we introduce two types of DANs for multimodal reasoning and matching, respectively. The reasoning model allows visual and textual attentions to steer each other during collaborative inference, which is useful for tasks such as Visual Question Answering (VQA). In addition, the matching model exploits the two attention mechanisms to estimate the similarity between images and sentences by focusing on their shared semantics. Our extensive experiments validate the effectiveness of DANs in combining vision and language, achieving the state-of-the-art performance on public benchmarks for VQA and image-text matching.
Modeling and Propagating CNNs in a Tree Structure for Visual Tracking
Aug 25, 2016


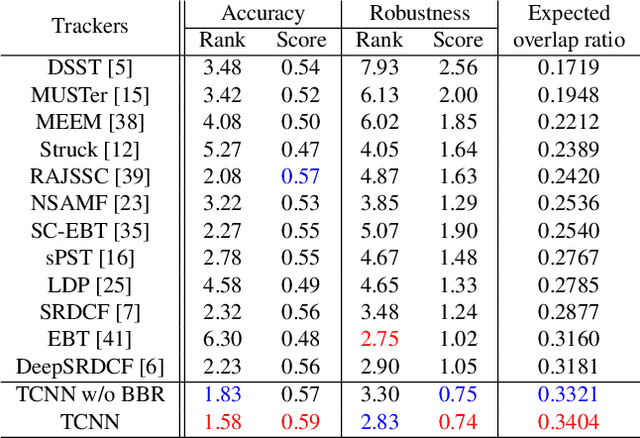
We present an online visual tracking algorithm by managing multiple target appearance models in a tree structure. The proposed algorithm employs Convolutional Neural Networks (CNNs) to represent target appearances, where multiple CNNs collaborate to estimate target states and determine the desirable paths for online model updates in the tree. By maintaining multiple CNNs in diverse branches of tree structure, it is convenient to deal with multi-modality in target appearances and preserve model reliability through smooth updates along tree paths. Since multiple CNNs share all parameters in convolutional layers, it takes advantage of multiple models with little extra cost by saving memory space and avoiding redundant network evaluations. The final target state is estimated by sampling target candidates around the state in the previous frame and identifying the best sample in terms of a weighted average score from a set of active CNNs. Our algorithm illustrates outstanding performance compared to the state-of-the-art techniques in challenging datasets such as online tracking benchmark and visual object tracking challenge.
Learning Multi-Domain Convolutional Neural Networks for Visual Tracking
Jan 06, 2016
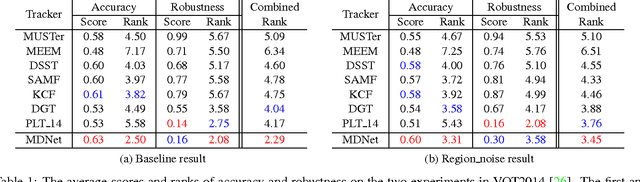

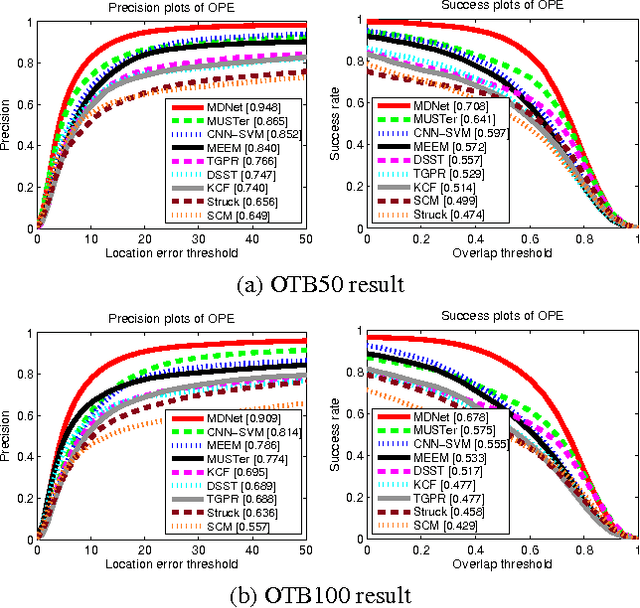
We propose a novel visual tracking algorithm based on the representations from a discriminatively trained Convolutional Neural Network (CNN). Our algorithm pretrains a CNN using a large set of videos with tracking ground-truths to obtain a generic target representation. Our network is composed of shared layers and multiple branches of domain-specific layers, where domains correspond to individual training sequences and each branch is responsible for binary classification to identify the target in each domain. We train the network with respect to each domain iteratively to obtain generic target representations in the shared layers. When tracking a target in a new sequence, we construct a new network by combining the shared layers in the pretrained CNN with a new binary classification layer, which is updated online. Online tracking is performed by evaluating the candidate windows randomly sampled around the previous target state. The proposed algorithm illustrates outstanding performance compared with state-of-the-art methods in existing tracking benchmarks.