 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotometric Transformer Networks and Label Adjustment for Breast Density Prediction
May 08, 2019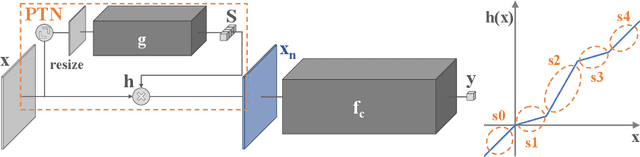
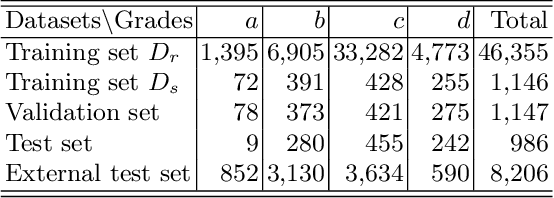
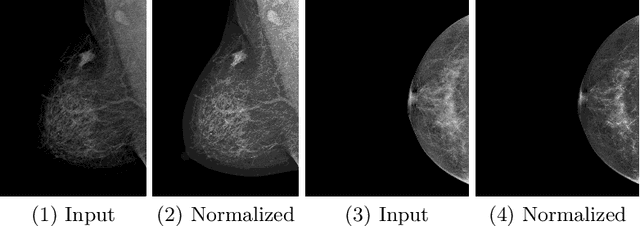
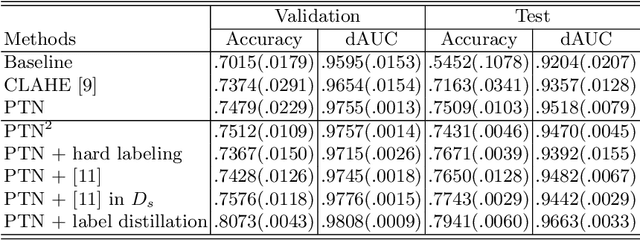
Grading breast density is highly sensitive to normalization settings of digital mammogram as the density is tightly correlated with the distribution of pixel intensity. Also, the grade varies with readers due to uncertain grading criteria. These issues are inherent in the density assessment of digital mammography. They are problematic when designing a computer-aided prediction model for breast density and become worse if the data comes from multiple sites. In this paper, we proposed two novel deep learning techniques for breast density prediction: 1) photometric transformation which adaptively normalizes the input mammograms, and 2) label distillation which adjusts the label by using its output prediction. The photometric transformer network predicts optimal parameters for photometric transformation on the fly, learned jointly with the main prediction network. The label distillation, a type of pseudo-label techniques, is intended to mitigate the grading variation. We experimentally showed that the proposed methods are beneficial in terms of breast density prediction, resulting in significant performance improvement compared to various previous approaches.
SRM : A Style-based Recalibration Module for Convolutional Neural Networks
Mar 26, 2019
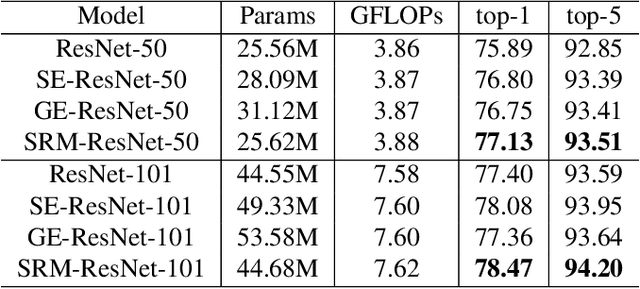
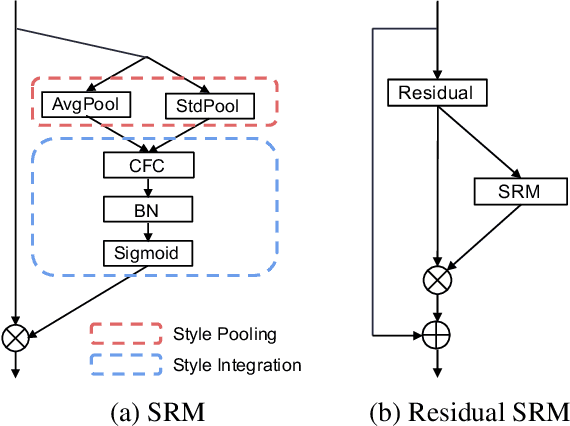
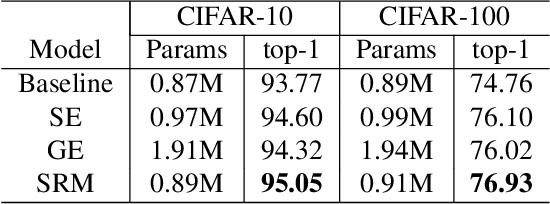
Following the advance of style transfer with Convolutional Neural Networks (CNNs), the role of styles in CNNs has drawn growing attention from a broader perspective. In this paper, we aim to fully leverage the potential of styles to improve the performance of CNNs in general vision tasks. We propose a Style-based Recalibration Module (SRM), a simple yet effective architectural unit, which adaptively recalibrates intermediate feature maps by exploiting their styles. SRM first extracts the style information from each channel of the feature maps by style pooling, then estimates per-channel recalibration weight via channel-independent style integration. By incorporating the relative importance of individual styles into feature maps, SRM effectively enhances the representational ability of a CNN. The proposed module is directly fed into existing CNN architectures with negligible overhead. We conduct comprehensive experiments on general image recognition as well as tasks related to styles, which verify the benefit of SRM over recent approaches such as Squeeze-and-Excitation (SE). To explain the inherent difference between SRM and SE, we provide an in-depth comparison of their representational properties.
Batch-Instance Normalization for Adaptively Style-Invariant Neural Networks
Oct 17, 2018
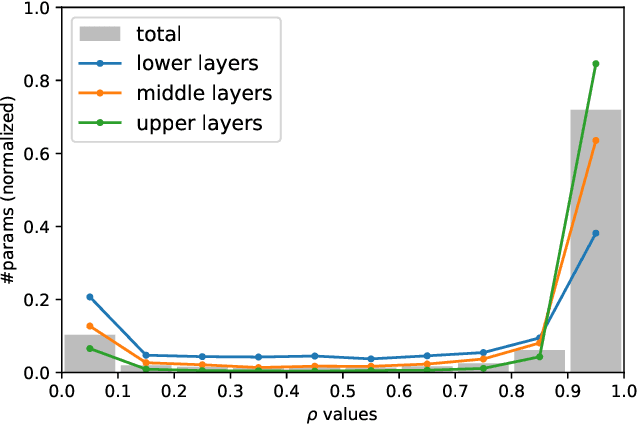
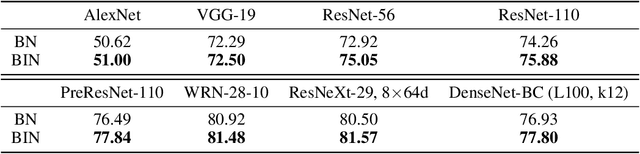

Real-world image recognition is often challenged by the variability of visual styles including object textures, lighting conditions, filter effects, etc. Although these variations have been deemed to be implicitly handled by more training data and deeper networks, recent advances in image style transfer suggest that it is also possible to explicitly manipulate the style information. Extending this idea to general visual recognition problems, we present Batch-Instance Normalization (BIN) to explicitly normalize unnecessary styles from images. Considering certain style features play an essential role in discriminative tasks, BIN learns to selectively normalize only disturbing styles while preserving useful styles. The proposed normalization module is easily incorporated into existing network architectures such as Residual Networks, and surprisingly improves the recognition performance in various scenarios. Furthermore, experiments verify that BIN effectively adapts to completely different tasks like object classification and style transfer, by controlling the trade-off between preserving and removing style variations. BIN can be implemented with only a few lines of code using popular deep learning frameworks.
Keep and Learn: Continual Learning by Constraining the Latent Space for Knowledge Preservation in Neural Networks
May 28, 2018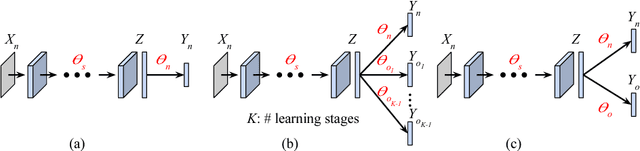


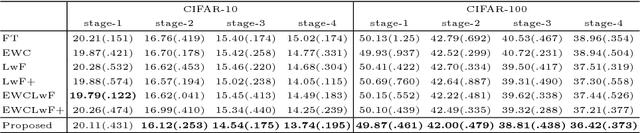
Data is one of the most important factors in machine learning. However, even if we have high-quality data, there is a situation in which access to the data is restricted. For example, access to the medical data from outside is strictly limited due to the privacy issues. In this case, we have to learn a model sequentially only with the data accessible in the corresponding stage. In this work, we propose a new method for preserving learned knowledge by modeling the high-level feature space and the output space to be mutually informative, and constraining feature vectors to lie in the modeled space during training. The proposed method is easy to implement as it can be applied by simply adding a reconstruction loss to an objective function. We evaluate the proposed method on CIFAR-10/100 and a chest X-ray dataset, and show benefits in terms of knowledge preservation compared to previous approaches.
Semantic Noise Modeling for Better Representation Learning
Nov 04, 2016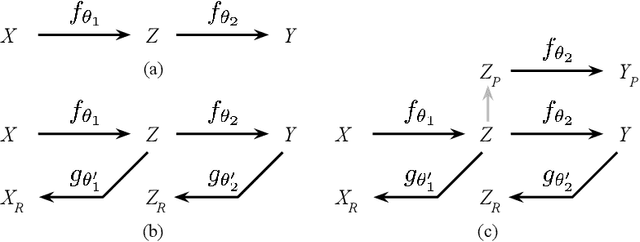
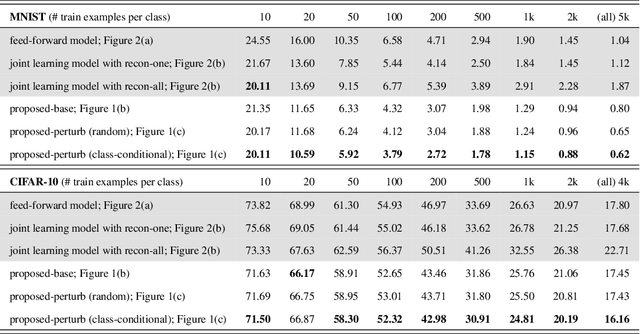


Latent representation learned from multi-layered neural networks via hierarchical feature abstraction enables recent success of deep learning. Under the deep learning framework, generalization performance highly depends on the learned latent representation which is obtained from an appropriate training scenario with a task-specific objective on a designed network model. In this work, we propose a novel latent space modeling method to learn better latent representation. We designed a neural network model based on the assumption that good base representation can be attained by maximizing the total correlation between the input, latent, and output variables. From the base model, we introduce a semantic noise modeling method which enables class-conditional perturbation on latent space to enhance the representational power of learned latent feature. During training, latent vector representation can be stochastically perturbed by a modeled class-conditional additive noise while maintaining its original semantic feature. It implicitly brings the effect of semantic augmentation on the latent space. The proposed model can be easily learned by back-propagation with common gradient-based optimization algorithms. Experimental results show that the proposed method helps to achieve performance benefits against various previous approaches. We also provide the empirical analyses for the proposed class-conditional perturbation process including t-SNE visualization.
Deconvolutional Feature Stacking for Weakly-Supervised Semantic Segmentation
Mar 12, 2016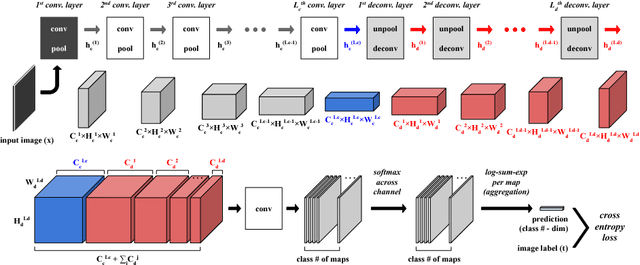
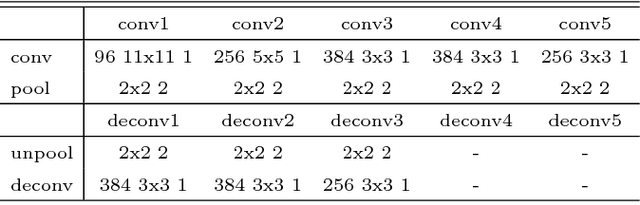
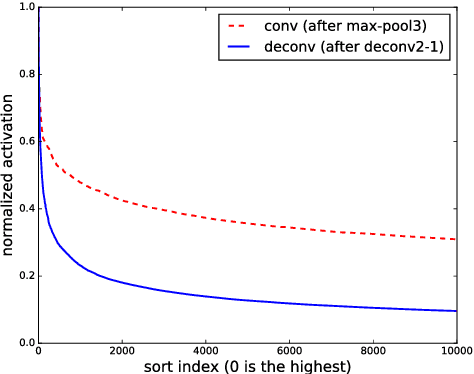
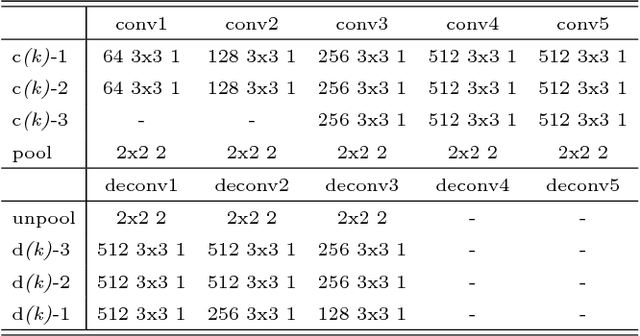
A weakly-supervised semantic segmentation framework with a tied deconvolutional neural network is presented. Each deconvolution layer in the framework consists of unpooling and deconvolution operations. 'Unpooling' upsamples the input feature map based on unpooling switches defined by corresponding convolution layer's pooling operation. 'Deconvolution' convolves the input unpooled features by using convolutional weights tied with the corresponding convolution layer's convolution operation. The unpooling-deconvolution combination helps to eliminate less discriminative features in a feature extraction stage, since output features of the deconvolution layer are reconstructed from the most discriminative unpooled features instead of the raw one. This results in reduction of false positives in a pixel-level inference stage. All the feature maps restored from the entire deconvolution layers can constitute a rich discriminative feature set according to different abstraction levels. Those features are stacked to be selectively used for generating class-specific activation maps. Under the weak supervision (image-level labels), the proposed framework shows promising results on lesion segmentation in medical images (chest X-rays) and achieves state-of-the-art performance on the PASCAL VOC segmentation dataset in the same experimental condition.
Self-Transfer Learning for Fully Weakly Supervised Object Localization
Feb 04, 2016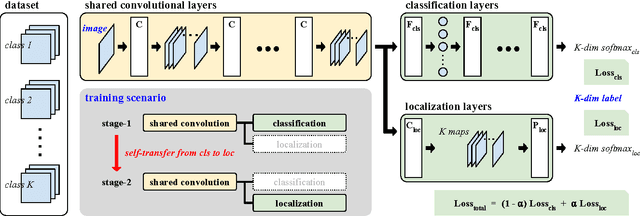

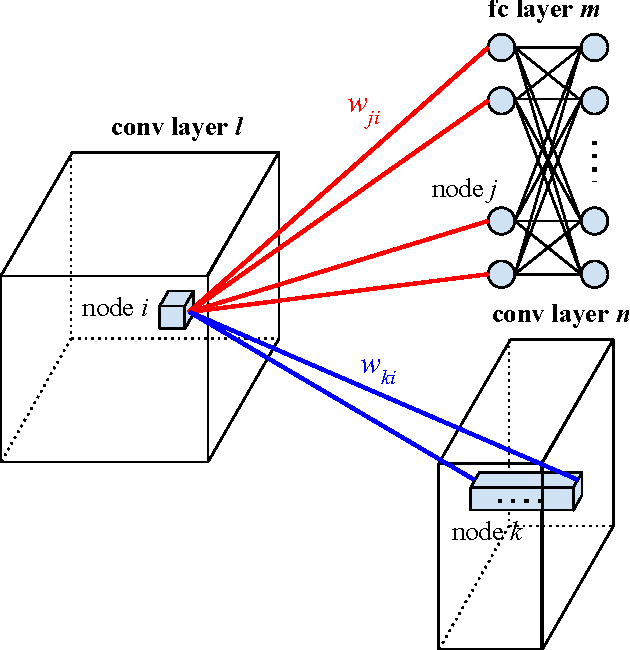
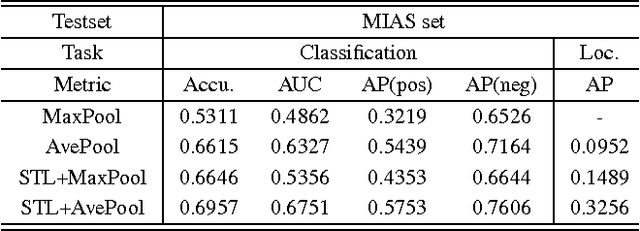
Recent advances of deep learning have achieved remarkable performances in various challenging computer vision tasks. Especially in object localization, deep convolutional neural networks outperform traditional approaches based on extraction of data/task-driven features instead of hand-crafted features. Although location information of region-of-interests (ROIs) gives good prior for object localization, it requires heavy annotation efforts from human resources. Thus a weakly supervised framework for object localization is introduced. The term "weakly" means that this framework only uses image-level labeled datasets to train a network. With the help of transfer learning which adopts weight parameters of a pre-trained network, the weakly supervised learning framework for object localization performs well because the pre-trained network already has well-trained class-specific features. However, those approaches cannot be used for some applications which do not have pre-trained networks or well-localized large scale images. Medical image analysis is a representative among those applications because it is impossible to obtain such pre-trained networks. In this work, we present a "fully" weakly supervised framework for object localization ("semi"-weakly is the counterpart which uses pre-trained filters for weakly supervised localization) named as self-transfer learning (STL). It jointly optimizes both classification and localization networks simultaneously. By controlling a supervision level of the localization network, STL helps the localization network focus on correct ROIs without any types of priors. We evaluate the proposed STL framework using two medical image datasets, chest X-rays and mammograms, and achieve signiticantly better localization performance compared to previous weakly supervised approaches.