 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHetCCL: Accelerating LLM Training with Heterogeneous GPUs
Jan 30, 2026The rapid growth of large language models is driving organizations to expand their GPU clusters, often with GPUs from multiple vendors. However, current deep learning frameworks lack support for collective communication across heterogeneous GPUs, leading to inefficiency and higher costs. We present HetCCL, a collective communication library that unifies vendor-specific backends and enables RDMA-based communication across GPUs without requiring driver modifications. HetCCL introduces two novel mechanisms that enable cross-vendor communication while leveraging optimized vendor libraries, NVIDIA NCCL and AMD RCCL. Evaluations on a multi-vendor GPU cluster show that HetCCL matches NCCL and RCCL performance in homogeneous setups while uniquely scaling in heterogeneous environments, enabling practical, high-performance training with both NVIDIA and AMD GPUs without changes to existing deep learning applications.
Adaptive Label Smoothing for Out-of-Distribution Detection
Oct 08, 2024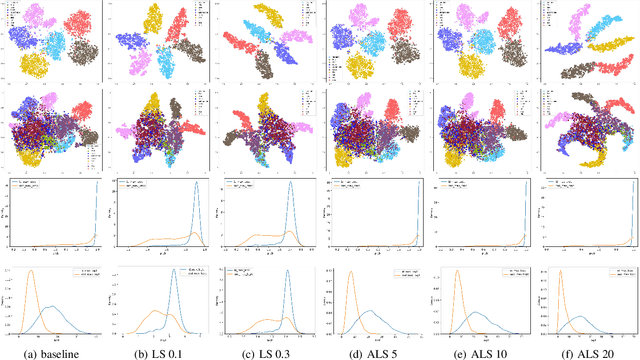
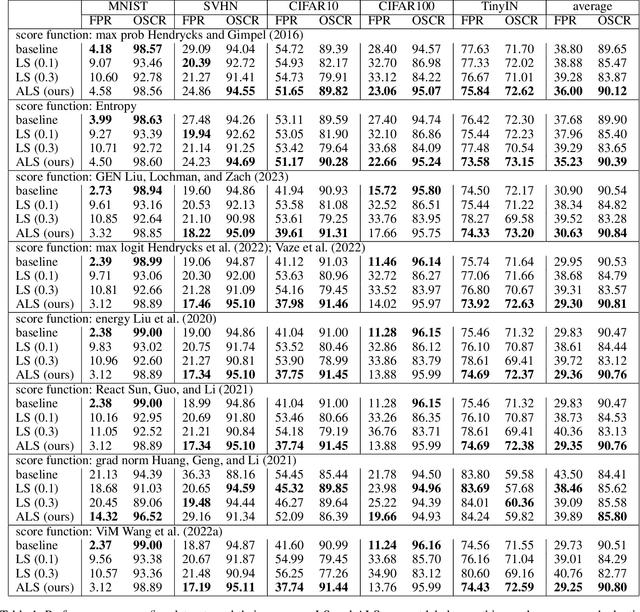
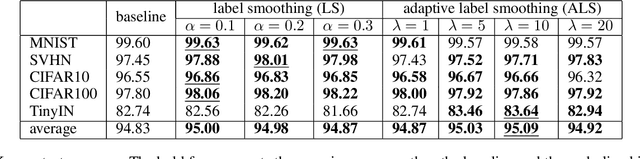
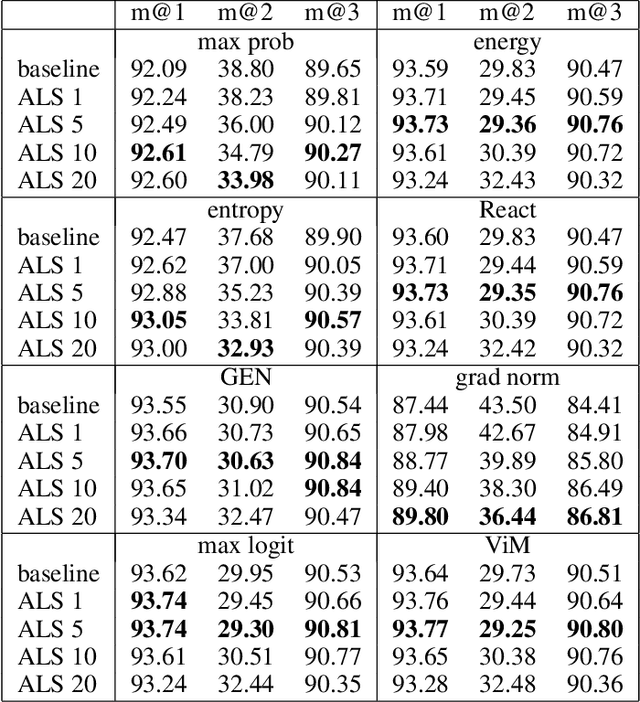
Out-of-distribution (OOD) detection, which aims to distinguish unknown classes from known classes, has received increasing attention recently. A main challenge within is the unavailable of samples from the unknown classes in the training process, and an effective strategy is to improve the performance for known classes. Using beneficial strategies such as data augmentation and longer training is thus a way to improve OOD detection. However, label smoothing, an effective method for classifying known classes, degrades the performance of OOD detection, and this phenomenon is under exploration. In this paper, we first analyze that the limited and predefined learning target in label smoothing results in the smaller maximal probability and logit, which further leads to worse OOD detection performance. To mitigate this issue, we then propose a novel regularization method, called adaptive label smoothing (ALS), and the core is to push the non-true classes to have same probabilities whereas the maximal probability is neither fixed nor limited. Extensive experimental results in six datasets with two backbones suggest that ALS contributes to classifying known samples and discerning unknown samples with clear margins. Our code will be available to the public.
Plant Disease Recognition Datasets in the Age of Deep Learning: Challenges and Opportunities
Dec 13, 2023Plant disease recognition has witnessed a significant improvement with deep learning in recent years. Although plant disease datasets are essential and many relevant datasets are public available, two fundamental questions exist. First, how to differentiate datasets and further choose suitable public datasets for specific applications? Second, what kinds of characteristics of datasets are desired to achieve promising performance in real-world applications? To address the questions, this study explicitly propose an informative taxonomy to describe potential plant disease datasets. We further provide several directions for future, such as creating challenge-oriented datasets and the ultimate objective deploying deep learning in real-world applications with satisfactory performance. In addition, existing related public RGB image datasets are summarized. We believe that this study will contributing making better datasets and that this study will contribute beyond plant disease recognition such as plant species recognition. To facilitate the community, our project is public https://github.com/xml94/PPDRD with the information of relevant public datasets.
Variation-Aware Semantic Image Synthesis
Jan 25, 2023Semantic image synthesis (SIS) aims to produce photorealistic images aligning to given conditional semantic layout and has witnessed a significant improvement in recent years. Although the diversity in image-level has been discussed heavily, class-level mode collapse widely exists in current algorithms. Therefore, we declare a new requirement for SIS to achieve more photorealistic images, variation-aware, which consists of inter- and intra-class variation. The inter-class variation is the diversity between different semantic classes while the intra-class variation stresses the diversity inside one class. Through analysis, we find that current algorithms elusively embrace the inter-class variation but the intra-class variation is still not enough. Further, we introduce two simple methods to achieve variation-aware semantic image synthesis (VASIS) with a higher intra-class variation, semantic noise and position code. We combine our method with several state-of-the-art algorithms and the experimental result shows that our models generate more natural images and achieves slightly better FIDs and/or mIoUs than the counterparts. Our codes and models will be publicly available.
Photometric Transformer Networks and Label Adjustment for Breast Density Prediction
May 08, 2019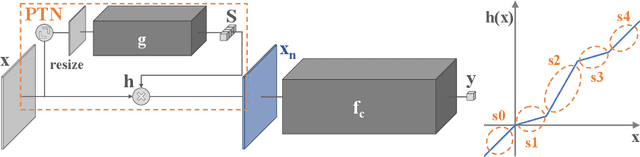
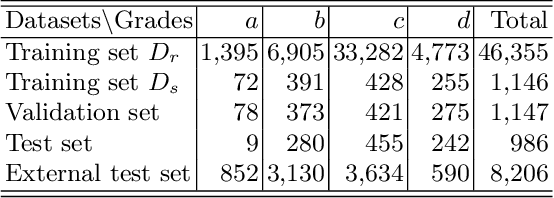
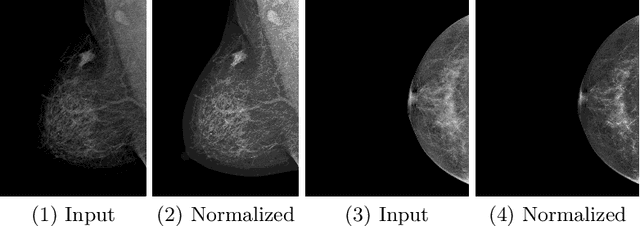
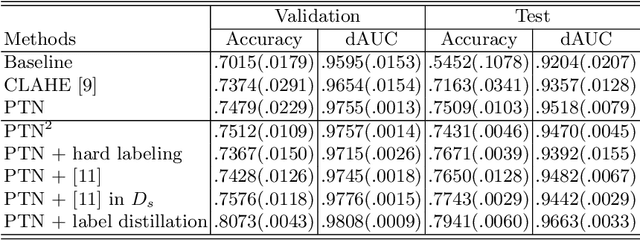
Grading breast density is highly sensitive to normalization settings of digital mammogram as the density is tightly correlated with the distribution of pixel intensity. Also, the grade varies with readers due to uncertain grading criteria. These issues are inherent in the density assessment of digital mammography. They are problematic when designing a computer-aided prediction model for breast density and become worse if the data comes from multiple sites. In this paper, we proposed two novel deep learning techniques for breast density prediction: 1) photometric transformation which adaptively normalizes the input mammograms, and 2) label distillation which adjusts the label by using its output prediction. The photometric transformer network predicts optimal parameters for photometric transformation on the fly, learned jointly with the main prediction network. The label distillation, a type of pseudo-label techniques, is intended to mitigate the grading variation. We experimentally showed that the proposed methods are beneficial in terms of breast density prediction, resulting in significant performance improvement compared to various previous approaches.
Keep and Learn: Continual Learning by Constraining the Latent Space for Knowledge Preservation in Neural Networks
May 28, 2018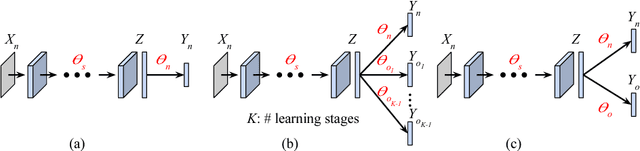


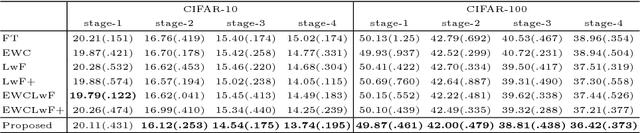
Data is one of the most important factors in machine learning. However, even if we have high-quality data, there is a situation in which access to the data is restricted. For example, access to the medical data from outside is strictly limited due to the privacy issues. In this case, we have to learn a model sequentially only with the data accessible in the corresponding stage. In this work, we propose a new method for preserving learned knowledge by modeling the high-level feature space and the output space to be mutually informative, and constraining feature vectors to lie in the modeled space during training. The proposed method is easy to implement as it can be applied by simply adding a reconstruction loss to an objective function. We evaluate the proposed method on CIFAR-10/100 and a chest X-ray dataset, and show benefits in terms of knowledge preservation compared to previous approaches.