 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Label Smoothing for Out-of-Distribution Detection
Oct 08, 2024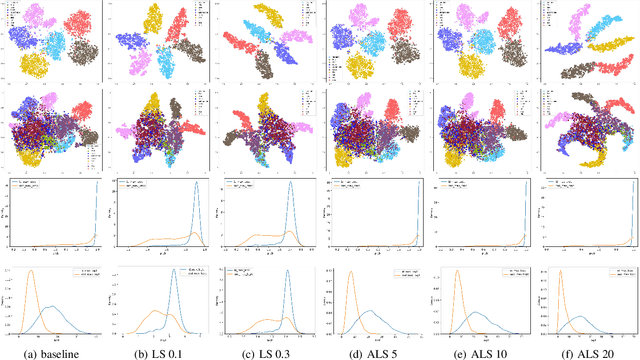
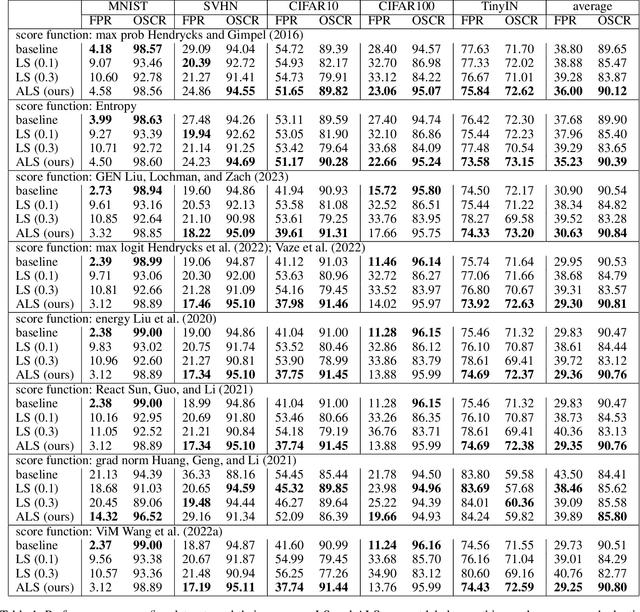
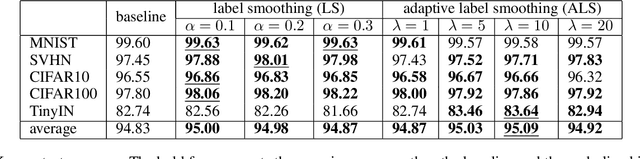
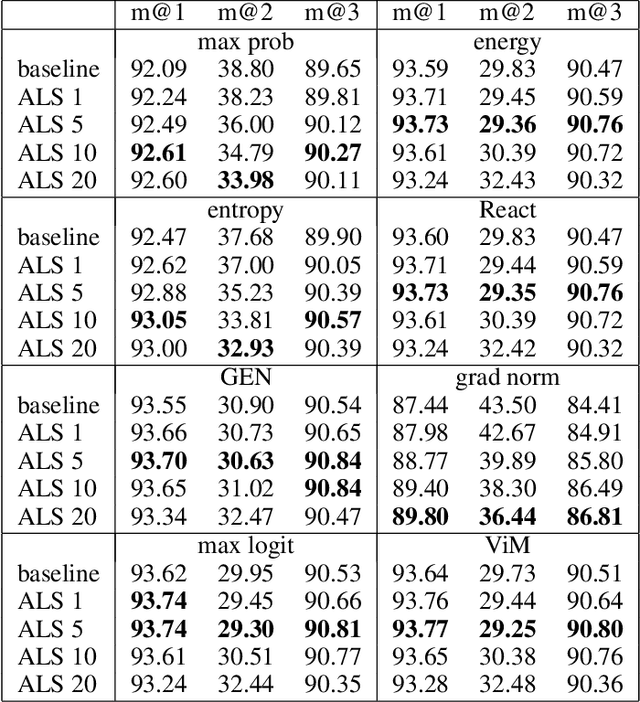
Out-of-distribution (OOD) detection, which aims to distinguish unknown classes from known classes, has received increasing attention recently. A main challenge within is the unavailable of samples from the unknown classes in the training process, and an effective strategy is to improve the performance for known classes. Using beneficial strategies such as data augmentation and longer training is thus a way to improve OOD detection. However, label smoothing, an effective method for classifying known classes, degrades the performance of OOD detection, and this phenomenon is under exploration. In this paper, we first analyze that the limited and predefined learning target in label smoothing results in the smaller maximal probability and logit, which further leads to worse OOD detection performance. To mitigate this issue, we then propose a novel regularization method, called adaptive label smoothing (ALS), and the core is to push the non-true classes to have same probabilities whereas the maximal probability is neither fixed nor limited. Extensive experimental results in six datasets with two backbones suggest that ALS contributes to classifying known samples and discerning unknown samples with clear margins. Our code will be available to the public.
Plant Disease Recognition Datasets in the Age of Deep Learning: Challenges and Opportunities
Dec 13, 2023Plant disease recognition has witnessed a significant improvement with deep learning in recent years. Although plant disease datasets are essential and many relevant datasets are public available, two fundamental questions exist. First, how to differentiate datasets and further choose suitable public datasets for specific applications? Second, what kinds of characteristics of datasets are desired to achieve promising performance in real-world applications? To address the questions, this study explicitly propose an informative taxonomy to describe potential plant disease datasets. We further provide several directions for future, such as creating challenge-oriented datasets and the ultimate objective deploying deep learning in real-world applications with satisfactory performance. In addition, existing related public RGB image datasets are summarized. We believe that this study will contributing making better datasets and that this study will contribute beyond plant disease recognition such as plant species recognition. To facilitate the community, our project is public https://github.com/xml94/PPDRD with the information of relevant public datasets.
Foundation Models in Smart Agriculture: Basics, Opportunities, and Challenges
Aug 18, 2023



The past decade has witnessed the rapid development of ML and DL methodologies in agricultural systems, showcased by great successes in variety of agricultural applications. However, these conventional ML/DL models have certain limitations: They heavily rely on large, costly-to-acquire labeled datasets for training, require specialized expertise for development and maintenance, and are mostly tailored for specific tasks, thus lacking generalizability. Recently, foundation models have demonstrated remarkable successes in language and vision tasks across various domains. These models are trained on a vast amount of data from multiple domains and modalities. Once trained, they can accomplish versatile tasks with just minor fine-tuning and minimal task-specific labeled data. Despite their proven effectiveness and huge potential, there has been little exploration of applying FMs to agriculture fields. Therefore, this study aims to explore the potential of FMs in the field of smart agriculture. In particular, we present conceptual tools and technical background to facilitate the understanding of the problem space and uncover new research directions in this field. To this end, we first review recent FMs in the general computer science domain and categorize them into four categories: language FMs, vision FMs, multimodal FMs, and reinforcement learning FMs. Subsequently, we outline the process of developing agriculture FMs and discuss their potential applications in smart agriculture. We also discuss the unique challenges associated with developing AFMs, including model training, validation, and deployment. Through this study, we contribute to the advancement of AI in agriculture by introducing AFMs as a promising paradigm that can significantly mitigate the reliance on extensive labeled datasets and enhance the efficiency, effectiveness, and generalization of agricultural AI systems.
Embracing Limited and Imperfect Data: A Review on Plant Stress Recognition Using Deep Learning
May 19, 2023Plant stress recognition has witnessed significant improvements in recent years with the advent of deep learning. A large-scale and annotated training dataset is required to achieve decent performance; however, collecting it is frequently difficult and expensive. Therefore, deploying current deep learning-based methods in real-world applications may suffer primarily from limited and imperfect data. Embracing them is a promising strategy that has not received sufficient attention. From this perspective, a systematic survey was conducted in this study, with the ultimate objective of monitoring plant growth by implementing deep learning, which frees humans and potentially reduces the resultant losses from plant stress. We believe that our paper has highlighted the importance of embracing this limited and imperfect data and enhanced its relevant understanding.
Variation-Aware Semantic Image Synthesis
Jan 25, 2023Semantic image synthesis (SIS) aims to produce photorealistic images aligning to given conditional semantic layout and has witnessed a significant improvement in recent years. Although the diversity in image-level has been discussed heavily, class-level mode collapse widely exists in current algorithms. Therefore, we declare a new requirement for SIS to achieve more photorealistic images, variation-aware, which consists of inter- and intra-class variation. The inter-class variation is the diversity between different semantic classes while the intra-class variation stresses the diversity inside one class. Through analysis, we find that current algorithms elusively embrace the inter-class variation but the intra-class variation is still not enough. Further, we introduce two simple methods to achieve variation-aware semantic image synthesis (VASIS) with a higher intra-class variation, semantic noise and position code. We combine our method with several state-of-the-art algorithms and the experimental result shows that our models generate more natural images and achieves slightly better FIDs and/or mIoUs than the counterparts. Our codes and models will be publicly available.
A Comprehensive Survey of Image Augmentation Techniques for Deep Learning
May 03, 2022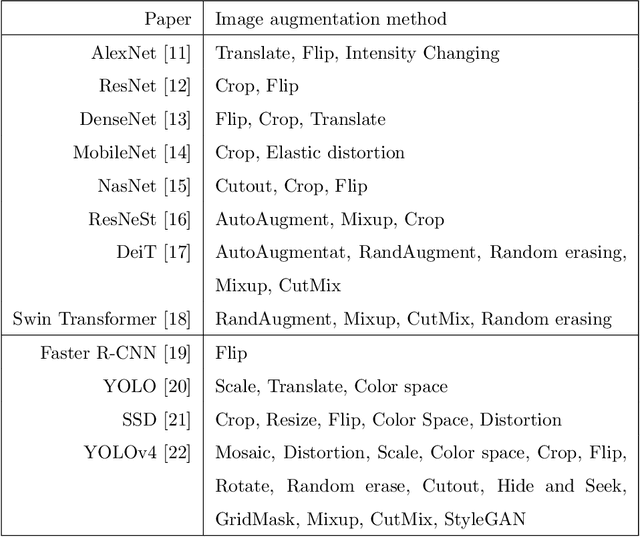
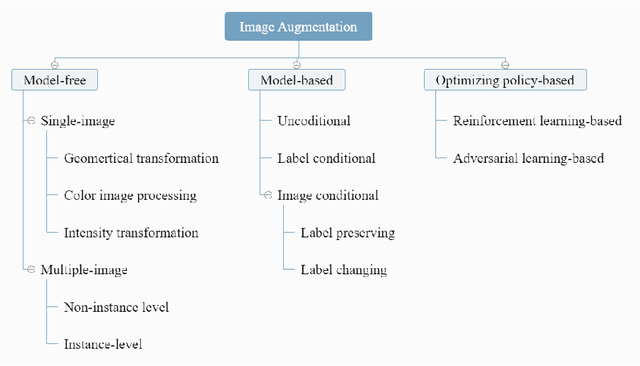
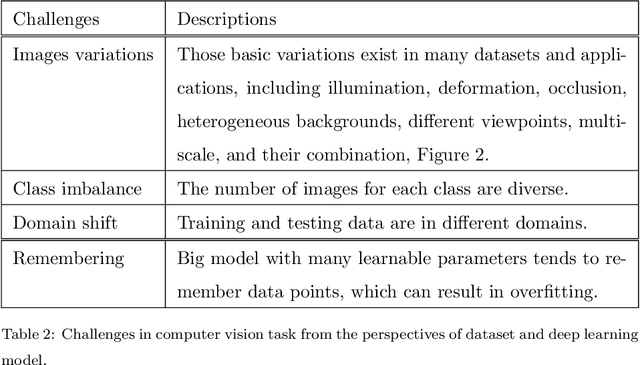

Deep learning has been achieving decent performance in computer vision requiring a large volume of images, however, collecting images is expensive and difficult in many scenarios. To alleviate this issue, many image augmentation algorithms have been proposed as effective and efficient strategies. Understanding current algorithms is essential to find suitable methods or develop novel techniques for given tasks. In this paper, we perform a comprehensive survey on image augmentation for deep learning with a novel informative taxonomy. To get the basic idea why we need image augmentation, we introduce the challenges in computer vision tasks and vicinity distribution. Then, the algorithms are split into three categories; model-free, model-based, and optimizing policy-based. The model-free category employs image processing methods while the model-based method leverages trainable image generation models. In contrast, the optimizing policy-based approach aims to find the optimal operations or their combinations. Furthermore, we discuss the current trend of common applications with two more active topics, leveraging different ways to understand image augmentation, such as group and kernel theory, and deploying image augmentation for unsupervised learning. Based on the analysis, we believe that our survey gives a better understanding helpful to choose suitable methods or design novel algorithms for practical applications.