 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Intent from Role: Adversarial Self-Play for Persona-Invariant Safety Alignment
May 03, 2026The growing capabilities of large language models (LLMs) have driven their widespread deployment across diverse domains, even in potentially high-risk scenarios. Despite advances in safety alignment techniques, current models remain vulnerable to emerging persona-based jailbreak attacks. Existing research on persona-based jailbreak has primarily focused on attack iterations, yet it lacks systemic and mechanistic constraints on the defense side. To address this challenge, we propose Persona-Invariant Alignment (PIA), an adversarial self-play framework that achieves co-evolution through Persona Lineage Evolution (PLE) on the attack side and Persona-Invariant Consistency Learning (PICL) on the defense side. Theoretically, PICL is grounded in the structural separation hypothesis, using a unilateral KL-divergence constraint to enable the structural decoupling of safety decisions from persona context, thereby maintaining safe behavior under persona-based jailbreak attacks. Experimental results demonstrate that PLE efficiently explores high-risk persona spaces by leveraging lineage-based credit propagation. Meanwhile, the PICL defense method significantly reduces the Attack Success Rate (ASR) while preserving the model's general capability, thereby validating the superiority and robustness of this alignment paradigm. Codes are available at https://github.com/JiajiaLi-1130/PIA.
SongSong: A Time Phonograph for Chinese SongCi Music from Thousand of Years Away
Feb 27, 2026Recently, there have been significant advancements in music generation. However, existing models primarily focus on creating modern pop songs, making it challenging to produce ancient music with distinct rhythms and styles, such as ancient Chinese SongCi. In this paper, we introduce SongSong, the first music generation model capable of restoring Chinese SongCi to our knowledge. Our model first predicts the melody from the input SongCi, then separately generates the singing voice and accompaniment based on that melody, and finally combines all elements to create the final piece of music. Additionally, to address the lack of ancient music datasets, we create OpenSongSong, a comprehensive dataset of ancient Chinese SongCi music, featuring 29.9 hours of compositions by various renowned SongCi music masters. To assess SongSong's proficiency in performing SongCi, we randomly select 85 SongCi sentences that were not part of the training set for evaluation against SongSong and music generation platforms such as Suno and SkyMusic. The subjective and objective outcomes indicate that our proposed model achieves leading performance in generating high-quality SongCi music.
SongSage: A Large Musical Language Model with Lyric Generative Pre-training
Jan 03, 2026Large language models have achieved significant success in various domains, yet their understanding of lyric-centric knowledge has not been fully explored. In this work, we first introduce PlaylistSense, a dataset to evaluate the playlist understanding capability of language models. PlaylistSense encompasses ten types of user queries derived from common real-world perspectives, challenging LLMs to accurately grasp playlist features and address diverse user intents. Comprehensive evaluations indicate that current general-purpose LLMs still have potential for improvement in playlist understanding. Inspired by this, we introduce SongSage, a large musical language model equipped with diverse lyric-centric intelligence through lyric generative pretraining. SongSage undergoes continual pretraining on LyricBank, a carefully curated corpus of 5.48 billion tokens focused on lyrical content, followed by fine-tuning with LyricBank-SFT, a meticulously crafted instruction set comprising 775k samples across nine core lyric-centric tasks. Experimental results demonstrate that SongSage exhibits a strong understanding of lyric-centric knowledge, excels in rewriting user queries for zero-shot playlist recommendations, generates and continues lyrics effectively, and performs proficiently across seven additional capabilities. Beyond its lyric-centric expertise, SongSage also retains general knowledge comprehension and achieves a competitive MMLU score. We will keep the datasets inaccessible due to copyright restrictions and release the SongSage and training script to ensure reproducibility and support music AI research and applications, the datasets release plan details are provided in the appendix.
Advancement and Field Evaluation of a Dual-arm Apple Harvesting Robot
Jun 06, 2025Apples are among the most widely consumed fruits worldwide. Currently, apple harvesting fully relies on manual labor, which is costly, drudging, and hazardous to workers. Hence, robotic harvesting has attracted increasing attention in recent years. However, existing systems still fall short in terms of performance, effectiveness, and reliability for complex orchard environments. In this work, we present the development and evaluation of a dual-arm harvesting robot. The system integrates a ToF camera, two 4DOF robotic arms, a centralized vacuum system, and a post-harvest handling module. During harvesting, suction force is dynamically assigned to either arm via the vacuum system, enabling efficient apple detachment while reducing power consumption and noise. Compared to our previous design, we incorporated a platform movement mechanism that enables both in-out and up-down adjustments, enhancing the robot's dexterity and adaptability to varying canopy structures. On the algorithmic side, we developed a robust apple localization pipeline that combines a foundation-model-based detector, segmentation, and clustering-based depth estimation, which improves performance in orchards. Additionally, pressure sensors were integrated into the system, and a novel dual-arm coordination strategy was introduced to respond to harvest failures based on sensor feedback, further improving picking efficiency. Field demos were conducted in two commercial orchards in MI, USA, with different canopy structures. The system achieved success rates of 0.807 and 0.797, with an average picking cycle time of 5.97s. The proposed strategy reduced harvest time by 28% compared to a single-arm baseline. The dual-arm harvesting robot enhances the reliability and efficiency of apple picking. With further advancements, the system holds strong potential for autonomous operation and commercialization for the apple industry.
A Survey on 3D Reconstruction Techniques in Plant Phenotyping: From Classical Methods to Neural Radiance Fields (NeRF), 3D Gaussian Splatting (3DGS), and Beyond
Apr 30, 2025Plant phenotyping plays a pivotal role in understanding plant traits and their interactions with the environment, making it crucial for advancing precision agriculture and crop improvement. 3D reconstruction technologies have emerged as powerful tools for capturing detailed plant morphology and structure, offering significant potential for accurate and automated phenotyping. This paper provides a comprehensive review of the 3D reconstruction techniques for plant phenotyping, covering classical reconstruction methods, emerging Neural Radiance Fields (NeRF), and the novel 3D Gaussian Splatting (3DGS) approach. Classical methods, which often rely on high-resolution sensors, are widely adopted due to their simplicity and flexibility in representing plant structures. However, they face challenges such as data density, noise, and scalability. NeRF, a recent advancement, enables high-quality, photorealistic 3D reconstructions from sparse viewpoints, but its computational cost and applicability in outdoor environments remain areas of active research. The emerging 3DGS technique introduces a new paradigm in reconstructing plant structures by representing geometry through Gaussian primitives, offering potential benefits in both efficiency and scalability. We review the methodologies, applications, and performance of these approaches in plant phenotyping and discuss their respective strengths, limitations, and future prospects (https://github.com/JiajiaLi04/3D-Reconstruction-Plants). Through this review, we aim to provide insights into how these diverse 3D reconstruction techniques can be effectively leveraged for automated and high-throughput plant phenotyping, contributing to the next generation of agricultural technology.
VLLFL: A Vision-Language Model Based Lightweight Federated Learning Framework for Smart Agriculture
Apr 17, 2025



In modern smart agriculture, object detection plays a crucial role by enabling automation, precision farming, and monitoring of resources. From identifying crop health and pest infestations to optimizing harvesting processes, accurate object detection enhances both productivity and sustainability. However, training object detection models often requires large-scale data collection and raises privacy concerns, particularly when sensitive agricultural data is distributed across farms. To address these challenges, we propose VLLFL, a vision-language model-based lightweight federated learning framework (VLLFL). It harnesses the generalization and context-aware detection capabilities of the vision-language model (VLM) and leverages the privacy-preserving nature of federated learning. By training a compact prompt generator to boost the performance of the VLM deployed across different farms, VLLFL preserves privacy while reducing communication overhead. Experimental results demonstrate that VLLFL achieves 14.53% improvement in the performance of VLM while reducing 99.3% communication overhead. Spanning tasks from identifying a wide variety of fruits to detecting harmful animals in agriculture, the proposed framework offers an efficient, scalable, and privacy-preserving solution specifically tailored to agricultural applications.
Label Drop for Multi-Aspect Relation Modeling in Universal Information Extraction
Feb 18, 2025



Universal Information Extraction (UIE) has garnered significant attention due to its ability to address model explosion problems effectively. Extractive UIE can achieve strong performance using a relatively small model, making it widely adopted. Extractive UIEs generally rely on task instructions for different tasks, including single-target instructions and multiple-target instructions. Single-target instruction UIE enables the extraction of only one type of relation at a time, limiting its ability to model correlations between relations and thus restricting its capability to extract complex relations. While multiple-target instruction UIE allows for the extraction of multiple relations simultaneously, the inclusion of irrelevant relations introduces decision complexity and impacts extraction accuracy. Therefore, for multi-relation extraction, we propose LDNet, which incorporates multi-aspect relation modeling and a label drop mechanism. By assigning different relations to different levels for understanding and decision-making, we reduce decision confusion. Additionally, the label drop mechanism effectively mitigates the impact of irrelevant relations. Experiments show that LDNet outperforms or achieves competitive performance with state-of-the-art systems on 9 tasks, 33 datasets, in both single-modal and multi-modal, few-shot and zero-shot settings.\footnote{https://github.com/Lu-Yang666/LDNet}
Foundation Model-Based Apple Ripeness and Size Estimation for Selective Harvesting
Feb 03, 2025

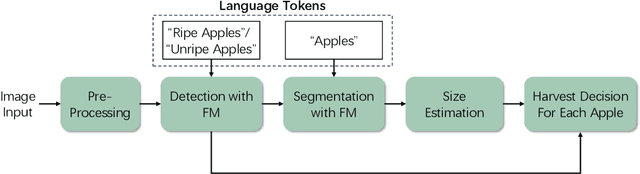
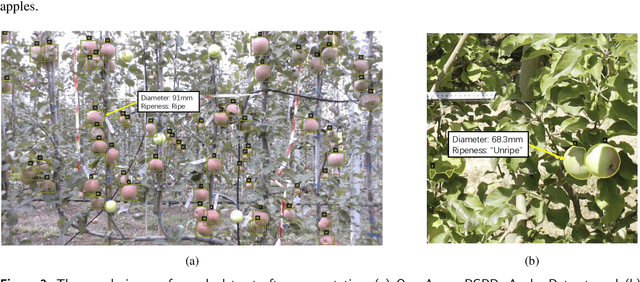
Harvesting is a critical task in the tree fruit industry, demanding extensive manual labor and substantial costs, and exposing workers to potential hazards. Recent advances in automated harvesting offer a promising solution by enabling efficient, cost-effective, and ergonomic fruit picking within tight harvesting windows. However, existing harvesting technologies often indiscriminately harvest all visible and accessible fruits, including those that are unripe or undersized. This study introduces a novel foundation model-based framework for efficient apple ripeness and size estimation. Specifically, we curated two public RGBD-based Fuji apple image datasets, integrating expanded annotations for ripeness ("Ripe" vs. "Unripe") based on fruit color and image capture dates. The resulting comprehensive dataset, Fuji-Ripeness-Size Dataset, includes 4,027 images and 16,257 annotated apples with ripeness and size labels. Using Grounding-DINO, a language-model-based object detector, we achieved robust apple detection and ripeness classification, outperforming other state-of-the-art models. Additionally, we developed and evaluated six size estimation algorithms, selecting the one with the lowest error and variation for optimal performance. The Fuji-Ripeness-Size Dataset and the apple detection and size estimation algorithms are made publicly available, which provides valuable benchmarks for future studies in automated and selective harvesting.
DeepContext: A Context-aware, Cross-platform, and Cross-framework Tool for Performance Profiling and Analysis of Deep Learning Workloads
Nov 05, 2024



Effective performance profiling and analysis are essential for optimizing training and inference of deep learning models, especially given the growing complexity of heterogeneous computing environments. However, existing tools often lack the capability to provide comprehensive program context information and performance optimization insights for sophisticated interactions between CPUs and GPUs. This paper introduces DeepContext, a novel profiler that links program contexts across high-level Python code, deep learning frameworks, underlying libraries written in C/C++, as well as device code executed on GPUs. DeepContext incorporates measurements of both coarse- and fine-grained performance metrics for major deep learning frameworks, such as PyTorch and JAX, and is compatible with GPUs from both Nvidia and AMD, as well as various CPU architectures, including x86 and ARM. In addition, DeepContext integrates a novel GUI that allows users to quickly identify hotpots and an innovative automated performance analyzer that suggests users with potential optimizations based on performance metrics and program context. Through detailed use cases, we demonstrate how DeepContext can help users identify and analyze performance issues to enable quick and effective optimization of deep learning workloads. We believe Deep Context is a valuable tool for users seeking to optimize complex deep learning workflows across multiple compute environments.
The Music Maestro or The Musically Challenged, A Massive Music Evaluation Benchmark for Large Language Models
Jun 22, 2024



Benchmark plays a pivotal role in assessing the advancements of large language models (LLMs). While numerous benchmarks have been proposed to evaluate LLMs' capabilities, there is a notable absence of a dedicated benchmark for assessing their musical abilities. To address this gap, we present ZIQI-Eval, a comprehensive and large-scale music benchmark specifically designed to evaluate the music-related capabilities of LLMs. ZIQI-Eval encompasses a wide range of questions, covering 10 major categories and 56 subcategories, resulting in over 14,000 meticulously curated data entries. By leveraging ZIQI-Eval, we conduct a comprehensive evaluation over 16 LLMs to evaluate and analyze LLMs' performance in the domain of music. Results indicate that all LLMs perform poorly on the ZIQI-Eval benchmark, suggesting significant room for improvement in their musical capabilities. With ZIQI-Eval, we aim to provide a standardized and robust evaluation framework that facilitates a comprehensive assessment of LLMs' music-related abilities. The dataset is available at GitHub\footnote{https://github.com/zcli-charlie/ZIQI-Eval} and HuggingFace\footnote{https://huggingface.co/datasets/MYTH-Lab/ZIQI-Eval}.