 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancement and Field Evaluation of a Dual-arm Apple Harvesting Robot
Jun 06, 2025Apples are among the most widely consumed fruits worldwide. Currently, apple harvesting fully relies on manual labor, which is costly, drudging, and hazardous to workers. Hence, robotic harvesting has attracted increasing attention in recent years. However, existing systems still fall short in terms of performance, effectiveness, and reliability for complex orchard environments. In this work, we present the development and evaluation of a dual-arm harvesting robot. The system integrates a ToF camera, two 4DOF robotic arms, a centralized vacuum system, and a post-harvest handling module. During harvesting, suction force is dynamically assigned to either arm via the vacuum system, enabling efficient apple detachment while reducing power consumption and noise. Compared to our previous design, we incorporated a platform movement mechanism that enables both in-out and up-down adjustments, enhancing the robot's dexterity and adaptability to varying canopy structures. On the algorithmic side, we developed a robust apple localization pipeline that combines a foundation-model-based detector, segmentation, and clustering-based depth estimation, which improves performance in orchards. Additionally, pressure sensors were integrated into the system, and a novel dual-arm coordination strategy was introduced to respond to harvest failures based on sensor feedback, further improving picking efficiency. Field demos were conducted in two commercial orchards in MI, USA, with different canopy structures. The system achieved success rates of 0.807 and 0.797, with an average picking cycle time of 5.97s. The proposed strategy reduced harvest time by 28% compared to a single-arm baseline. The dual-arm harvesting robot enhances the reliability and efficiency of apple picking. With further advancements, the system holds strong potential for autonomous operation and commercialization for the apple industry.
Foundation Model-Based Apple Ripeness and Size Estimation for Selective Harvesting
Feb 03, 2025

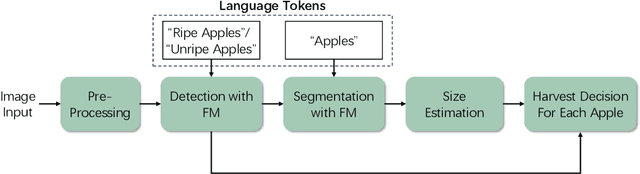
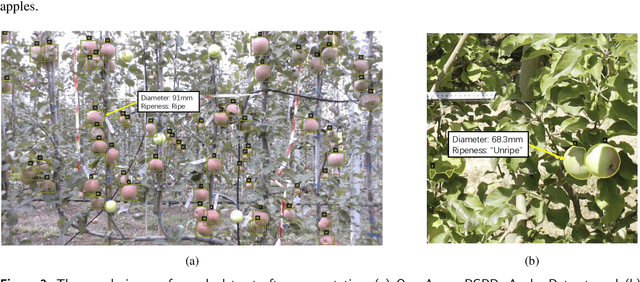
Harvesting is a critical task in the tree fruit industry, demanding extensive manual labor and substantial costs, and exposing workers to potential hazards. Recent advances in automated harvesting offer a promising solution by enabling efficient, cost-effective, and ergonomic fruit picking within tight harvesting windows. However, existing harvesting technologies often indiscriminately harvest all visible and accessible fruits, including those that are unripe or undersized. This study introduces a novel foundation model-based framework for efficient apple ripeness and size estimation. Specifically, we curated two public RGBD-based Fuji apple image datasets, integrating expanded annotations for ripeness ("Ripe" vs. "Unripe") based on fruit color and image capture dates. The resulting comprehensive dataset, Fuji-Ripeness-Size Dataset, includes 4,027 images and 16,257 annotated apples with ripeness and size labels. Using Grounding-DINO, a language-model-based object detector, we achieved robust apple detection and ripeness classification, outperforming other state-of-the-art models. Additionally, we developed and evaluated six size estimation algorithms, selecting the one with the lowest error and variation for optimal performance. The Fuji-Ripeness-Size Dataset and the apple detection and size estimation algorithms are made publicly available, which provides valuable benchmarks for future studies in automated and selective harvesting.
Enhancing AI microscopy for foodborne bacterial classification via adversarial domain adaptation across optical and biological variability
Nov 29, 2024Rapid detection of foodborne bacteria is critical for food safety and quality, yet traditional culture-based methods require extended incubation and specialized sample preparation. This study addresses these challenges by i) enhancing the generalizability of AI-enabled microscopy for bacterial classification using adversarial domain adaptation and ii) comparing the performance of single-target and multi-domain adaptation. Three Gram-positive (Bacillus coagulans, Bacillus subtilis, Listeria innocua) and three Gram-negative (E. coli, Salmonella Enteritidis, Salmonella Typhimurium) strains were classified. EfficientNetV2 served as the backbone architecture, leveraging fine-grained feature extraction for small targets. Few-shot learning enabled scalability, with domain-adversarial neural networks (DANNs) addressing single domains and multi-DANNs (MDANNs) generalizing across all target domains. The model was trained on source domain data collected under controlled conditions (phase contrast microscopy, 60x magnification, 3-h bacterial incubation) and evaluated on target domains with variations in microscopy modality (brightfield, BF), magnification (20x), and extended incubation to compensate for lower resolution (20x-5h). DANNs improved target domain classification accuracy by up to 54.45% (20x), 43.44% (20x-5h), and 31.67% (BF), with minimal source domain degradation (<4.44%). MDANNs achieved superior performance in the BF domain and substantial gains in the 20x domain. Grad-CAM and t-SNE visualizations validated the model's ability to learn domain-invariant features across diverse conditions. This study presents a scalable and adaptable framework for bacterial classification, reducing reliance on extensive sample preparation and enabling application in decentralized and resource-limited environments.
Impact of Network Topology on Byzantine Resilience in Decentralized Federated Learning
Jul 06, 2024



Federated learning (FL) enables a collaborative environment for training machine learning models without sharing training data between users. This is typically achieved by aggregating model gradients on a central server. Decentralized federated learning is a rising paradigm that enables users to collaboratively train machine learning models in a peer-to-peer manner, without the need for a central aggregation server. However, before applying decentralized FL in real-world use training environments, nodes that deviate from the FL process (Byzantine nodes) must be considered when selecting an aggregation function. Recent research has focused on Byzantine-robust aggregation for client-server or fully connected networks, but has not yet evaluated such aggregation schemes for complex topologies possible with decentralized FL. Thus, the need for empirical evidence of Byzantine robustness in differing network topologies is evident. This work investigates the effects of state-of-the-art Byzantine-robust aggregation methods in complex, large-scale network structures. We find that state-of-the-art Byzantine robust aggregation strategies are not resilient within large non-fully connected networks. As such, our findings point the field towards the development of topology-aware aggregation schemes, especially necessary within the context of large scale real-world deployment.