 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepContext: A Context-aware, Cross-platform, and Cross-framework Tool for Performance Profiling and Analysis of Deep Learning Workloads
Nov 05, 2024



Effective performance profiling and analysis are essential for optimizing training and inference of deep learning models, especially given the growing complexity of heterogeneous computing environments. However, existing tools often lack the capability to provide comprehensive program context information and performance optimization insights for sophisticated interactions between CPUs and GPUs. This paper introduces DeepContext, a novel profiler that links program contexts across high-level Python code, deep learning frameworks, underlying libraries written in C/C++, as well as device code executed on GPUs. DeepContext incorporates measurements of both coarse- and fine-grained performance metrics for major deep learning frameworks, such as PyTorch and JAX, and is compatible with GPUs from both Nvidia and AMD, as well as various CPU architectures, including x86 and ARM. In addition, DeepContext integrates a novel GUI that allows users to quickly identify hotpots and an innovative automated performance analyzer that suggests users with potential optimizations based on performance metrics and program context. Through detailed use cases, we demonstrate how DeepContext can help users identify and analyze performance issues to enable quick and effective optimization of deep learning workloads. We believe Deep Context is a valuable tool for users seeking to optimize complex deep learning workflows across multiple compute environments.
AutoST: Training-free Neural Architecture Search for Spiking Transformers
Jul 01, 2023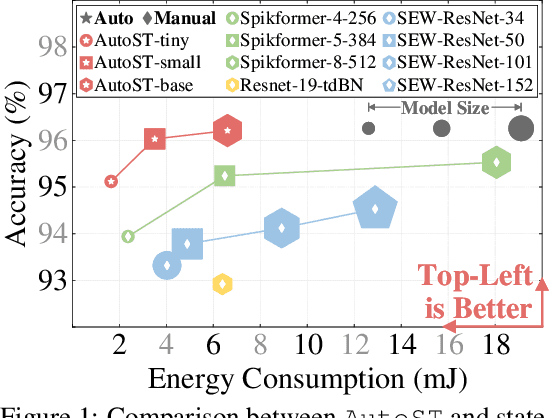
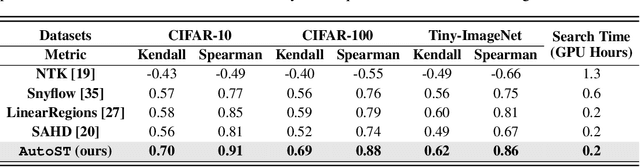
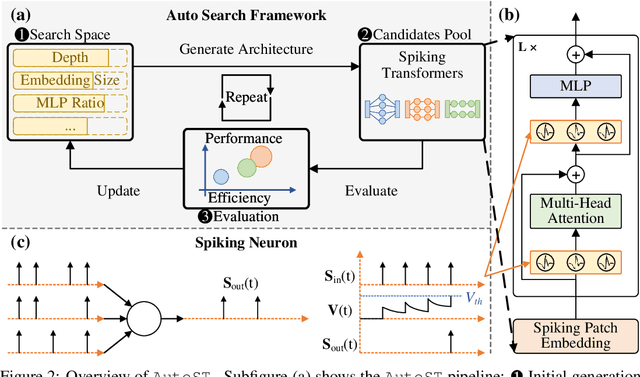
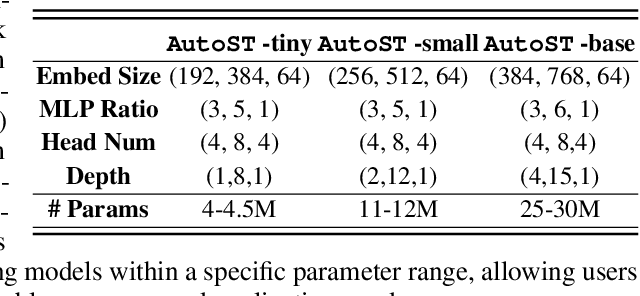
Spiking Transformers have gained considerable attention because they achieve both the energy efficiency of Spiking Neural Networks (SNNs) and the high capacity of Transformers. However, the existing Spiking Transformer architectures, derived from ANNs, exhibit a notable architectural gap, resulting in suboptimal performance compared to their ANN counterparts. Traditional approaches to discovering optimal architectures primarily rely on either manual procedures, which are time-consuming, or Neural Architecture Search (NAS) methods, which are usually expensive in terms of memory footprints and computation time. To address these limitations, we introduce AutoST, a training-free NAS method for Spiking Transformers, to rapidly identify high-performance and energy-efficient Spiking Transformer architectures. Unlike existing training-free NAS methods, which struggle with the non-differentiability and high sparsity inherent in SNNs, we propose to utilize Floating-Point Operations (FLOPs) as a performance metric, which is independent of model computations and training dynamics, leading to a stronger correlation with performance. Moreover, to enable the search for energy-efficient architectures, we leverage activation patterns during initialization to estimate the energy consumption of Spiking Transformers. Our extensive experiments show that AutoST models outperform state-of-the-art manually or automatically designed SNN architectures on static and neuromorphic datasets, while significantly reducing energy consumption.