 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepContext: A Context-aware, Cross-platform, and Cross-framework Tool for Performance Profiling and Analysis of Deep Learning Workloads
Nov 05, 2024



Effective performance profiling and analysis are essential for optimizing training and inference of deep learning models, especially given the growing complexity of heterogeneous computing environments. However, existing tools often lack the capability to provide comprehensive program context information and performance optimization insights for sophisticated interactions between CPUs and GPUs. This paper introduces DeepContext, a novel profiler that links program contexts across high-level Python code, deep learning frameworks, underlying libraries written in C/C++, as well as device code executed on GPUs. DeepContext incorporates measurements of both coarse- and fine-grained performance metrics for major deep learning frameworks, such as PyTorch and JAX, and is compatible with GPUs from both Nvidia and AMD, as well as various CPU architectures, including x86 and ARM. In addition, DeepContext integrates a novel GUI that allows users to quickly identify hotpots and an innovative automated performance analyzer that suggests users with potential optimizations based on performance metrics and program context. Through detailed use cases, we demonstrate how DeepContext can help users identify and analyze performance issues to enable quick and effective optimization of deep learning workloads. We believe Deep Context is a valuable tool for users seeking to optimize complex deep learning workflows across multiple compute environments.
HybridFlow: A Flexible and Efficient RLHF Framework
Sep 28, 2024



Reinforcement Learning from Human Feedback (RLHF) is widely used in Large Language Model (LLM) alignment. Traditional RL can be modeled as a dataflow, where each node represents computation of a neural network (NN) and each edge denotes data dependencies between the NNs. RLHF complicates the dataflow by expanding each node into a distributed LLM training or generation program, and each edge into a many-to-many multicast. Traditional RL frameworks execute the dataflow using a single controller to instruct both intra-node computation and inter-node communication, which can be inefficient in RLHF due to large control dispatch overhead for distributed intra-node computation. Existing RLHF systems adopt a multi-controller paradigm, which can be inflexible due to nesting distributed computation and data communication. We propose HybridFlow, which combines single-controller and multi-controller paradigms in a hybrid manner to enable flexible representation and efficient execution of the RLHF dataflow. We carefully design a set of hierarchical APIs that decouple and encapsulate computation and data dependencies in the complex RLHF dataflow, allowing efficient operation orchestration to implement RLHF algorithms and flexible mapping of the computation onto various devices. We further design a 3D-HybridEngine for efficient actor model resharding between training and generation phases, with zero memory redundancy and significantly reduced communication overhead. Our experimental results demonstrate 1.53$\times$~20.57$\times$ throughput improvement when running various RLHF algorithms using HybridFlow, as compared with state-of-the-art baselines. HybridFlow source code is available at https://github.com/volcengine/verl.
End-to-end Adaptive Distributed Training on PaddlePaddle
Dec 06, 2021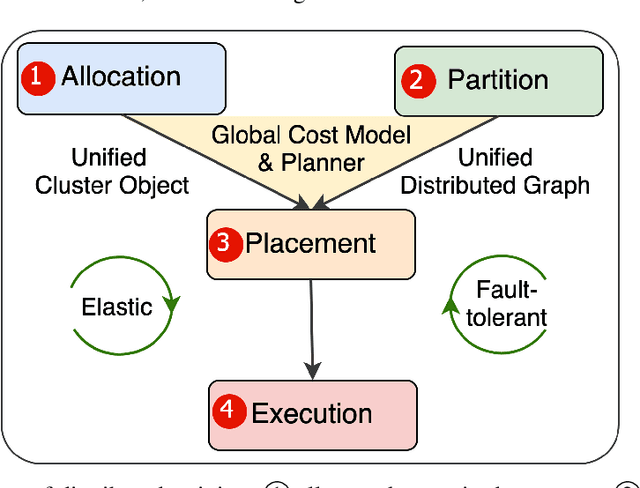
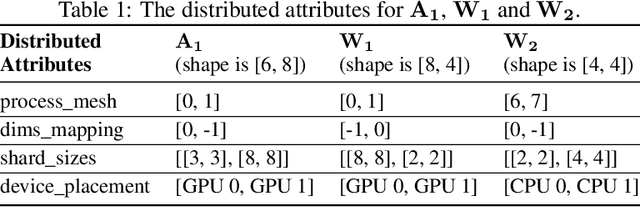
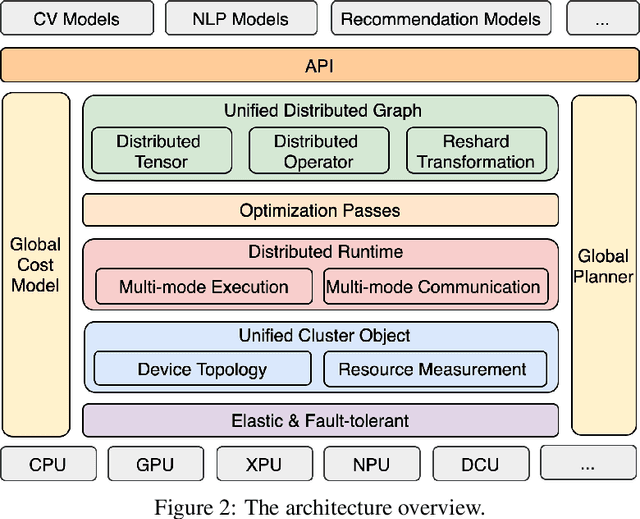
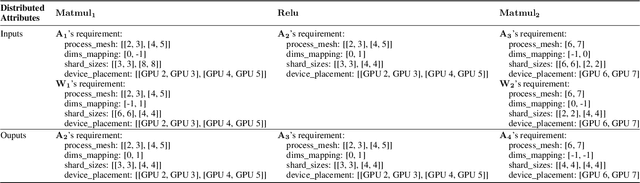
Distributed training has become a pervasive and effective approach for training a large neural network (NN) model with processing massive data. However, it is very challenging to satisfy requirements from various NN models, diverse computing resources, and their dynamic changes during a training job. In this study, we design our distributed training framework in a systematic end-to-end view to provide the built-in adaptive ability for different scenarios, especially for industrial applications and production environments, by fully considering resource allocation, model partition, task placement, and distributed execution. Based on the unified distributed graph and the unified cluster object, our adaptive framework is equipped with a global cost model and a global planner, which can enable arbitrary parallelism, resource-aware placement, multi-mode execution, fault-tolerant, and elastic distributed training. The experiments demonstrate that our framework can satisfy various requirements from the diversity of applications and the heterogeneity of resources with highly competitive performance. The ERNIE language model with 260 billion parameters is efficiently trained on thousands of AI processors with 91.7% weak scalability. The throughput of the model from the recommender system by employing the heterogeneous pipeline asynchronous execution can be increased up to 2.1 times and 3.3 times that of the GPU-only and CPU-only training respectively. Moreover, the fault-tolerant and elastic distributed training have been successfully applied to the online industrial applications, which give a reduction of 34.49% in the number of failed long-term training jobs and an increase of 33.91% for the global scheduling efficiency in the production environment.