 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboBrain 2.5: Depth in Sight, Time in Mind
Jan 20, 2026We introduce RoboBrain 2.5, a next-generation embodied AI foundation model that advances general perception, spatial reasoning, and temporal modeling through extensive training on high-quality spatiotemporal supervision. Building upon its predecessor, RoboBrain 2.5 introduces two major capability upgrades. Specifically, it unlocks Precise 3D Spatial Reasoning by shifting from 2D pixel-relative grounding to depth-aware coordinate prediction and absolute metric constraint comprehension, generating complete 3D manipulation traces as ordered keypoint sequences under physical constraints. Complementing this spatial precision, the model establishes Dense Temporal Value Estimation that provides dense, step-aware progress prediction and execution state understanding across varying viewpoints, producing stable feedback signals for downstream learning. Together, these upgrades extend the framework toward more physically grounded and execution-aware embodied intelligence for complex, fine-grained manipulation. The code and checkpoints are available at project website: https://superrobobrain.github.io
TrimTokenator-LC: Towards Adaptive Visual Token Pruning for Large Multimodal Models with Long Contexts
Dec 31, 2025Large Multimodal Models (LMMs) have proven effective on various tasks. They typically encode visual inputs into Original Model sequences of tokens, which are then concatenated with textual tokens and jointly processed by the language model. However, the growing number of visual tokens greatly increases inference cost. Visual token pruning has emerged as a promising solution. However, existing methods often overlook scenarios involving long context inputs with multiple images. In this paper, we analyze the challenges of visual token pruning in long context, multi-image settings and introduce an adaptive pruning method tailored for such scenarios. We decompose redundancy into intra-image and inter-image components and quantify them through intra-image diversity and inter-image variation, which jointly guide dynamic budget allocation. Our approach consists of two stages. The intra-image stage allocates each image a content-aware token budget and greedily selects its most representative tokens. The inter-image stage performs global diversity filtering to form a candidate pool and then applies a Pareto selection procedure that balances diversity with text alignment. Extensive experiments show that our approach can reduce up to 80% of visual tokens while maintaining performance in long context settings.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
RoboOS-NeXT: A Unified Memory-based Framework for Lifelong, Scalable, and Robust Multi-Robot Collaboration
Oct 30, 2025The proliferation of collaborative robots across diverse tasks and embodiments presents a central challenge: achieving lifelong adaptability, scalable coordination, and robust scheduling in multi-agent systems. Existing approaches, from vision-language-action (VLA) models to hierarchical frameworks, fall short due to their reliance on limited or dividual-agent memory. This fundamentally constrains their ability to learn over long horizons, scale to heterogeneous teams, or recover from failures, highlighting the need for a unified memory representation. To address these limitations, we introduce RoboOS-NeXT, a unified memory-based framework for lifelong, scalable, and robust multi-robot collaboration. At the core of RoboOS-NeXT is the novel Spatio-Temporal-Embodiment Memory (STEM), which integrates spatial scene geometry, temporal event history, and embodiment profiles into a shared representation. This memory-centric design is integrated into a brain-cerebellum framework, where a high-level brain model performs global planning by retrieving and updating STEM, while low-level controllers execute actions locally. This closed loop between cognition, memory, and execution enables dynamic task allocation, fault-tolerant collaboration, and consistent state synchronization. We conduct extensive experiments spanning complex coordination tasks in restaurants, supermarkets, and households. Our results demonstrate that RoboOS-NeXT achieves superior performance across heterogeneous embodiments, validating its effectiveness in enabling lifelong, scalable, and robust multi-robot collaboration. Project website: https://flagopen.github.io/RoboOS/
RoboBrain 2.0 Technical Report
Jul 02, 2025We introduce RoboBrain 2.0, our latest generation of embodied vision-language foundation models, designed to unify perception, reasoning, and planning for complex embodied tasks in physical environments. It comes in two variants: a lightweight 7B model and a full-scale 32B model, featuring a heterogeneous architecture with a vision encoder and a language model. Despite its compact size, RoboBrain 2.0 achieves strong performance across a wide spectrum of embodied reasoning tasks. On both spatial and temporal benchmarks, the 32B variant achieves leading results, surpassing prior open-source and proprietary models. In particular, it supports key real-world embodied AI capabilities, including spatial understanding (e.g., affordance prediction, spatial referring, trajectory forecasting) and temporal decision-making (e.g., closed-loop interaction, multi-agent long-horizon planning, and scene graph updating). This report details the model architecture, data construction, multi-stage training strategies, infrastructure and practical applications. We hope RoboBrain 2.0 advances embodied AI research and serves as a practical step toward building generalist embodied agents. The code, checkpoint and benchmark are available at https://superrobobrain.github.io.
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024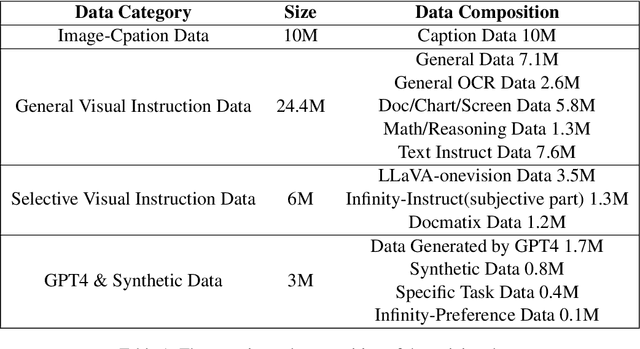
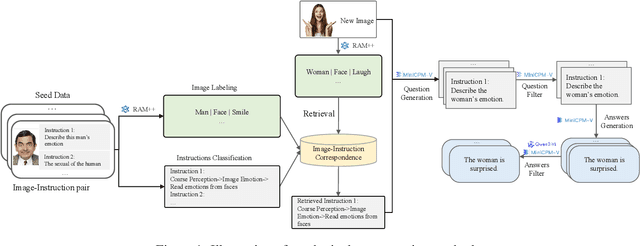
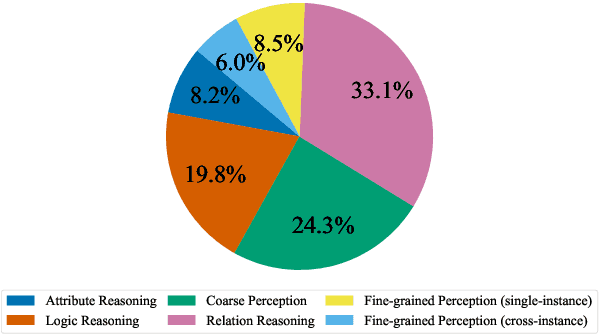
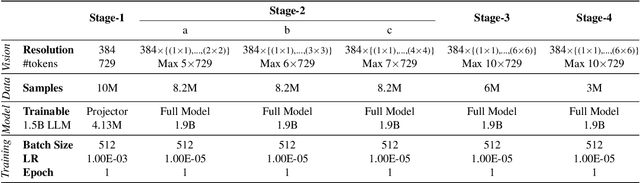
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
Emu3: Next-Token Prediction is All You Need
Sep 27, 2024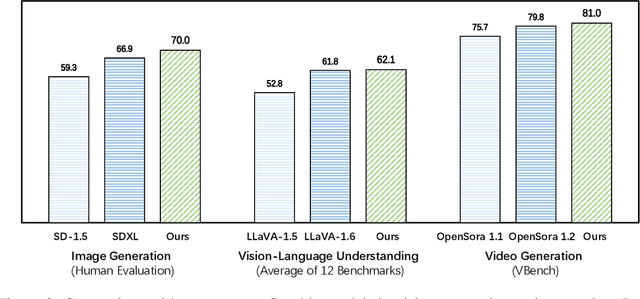


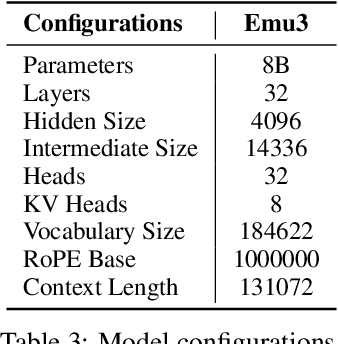
While next-token prediction is considered a promising path towards artificial general intelligence, it has struggled to excel in multimodal tasks, which are still dominated by diffusion models (e.g., Stable Diffusion) and compositional approaches (e.g., CLIP combined with LLMs). In this paper, we introduce Emu3, a new suite of state-of-the-art multimodal models trained solely with next-token prediction. By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures. Emu3 is also capable of generating high-fidelity video via predicting the next token in a video sequence. We simplify complex multimodal model designs by converging on a singular focus: tokens, unlocking great potential for scaling both during training and inference. Our results demonstrate that next-token prediction is a promising path towards building general multimodal intelligence beyond language. We open-source key techniques and models to support further research in this direction.
Aquila2 Technical Report
Aug 14, 2024This paper introduces the Aquila2 series, which comprises a wide range of bilingual models with parameter sizes of 7, 34, and 70 billion. These models are trained based on an innovative framework named HeuriMentor (HM), which offers real-time insights into model convergence and enhances the training process and data management. The HM System, comprising the Adaptive Training Engine (ATE), Training State Monitor (TSM), and Data Management Unit (DMU), allows for precise monitoring of the model's training progress and enables efficient optimization of data distribution, thereby enhancing training effectiveness. Extensive evaluations show that the Aquila2 model series performs comparably well on both English and Chinese benchmarks. Specifically, Aquila2-34B demonstrates only a slight decrease in performance when quantized to Int4. Furthermore, we have made our training code (https://github.com/FlagOpen/FlagScale) and model weights (https://github.com/FlagAI-Open/Aquila2) publicly available to support ongoing research and the development of applications.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
End-to-end Adaptive Distributed Training on PaddlePaddle
Dec 06, 2021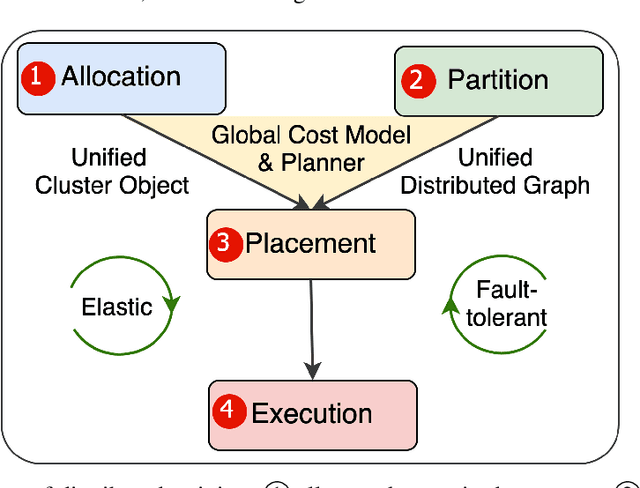
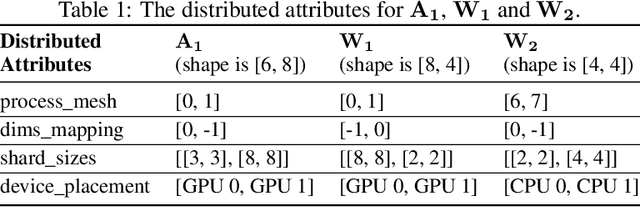
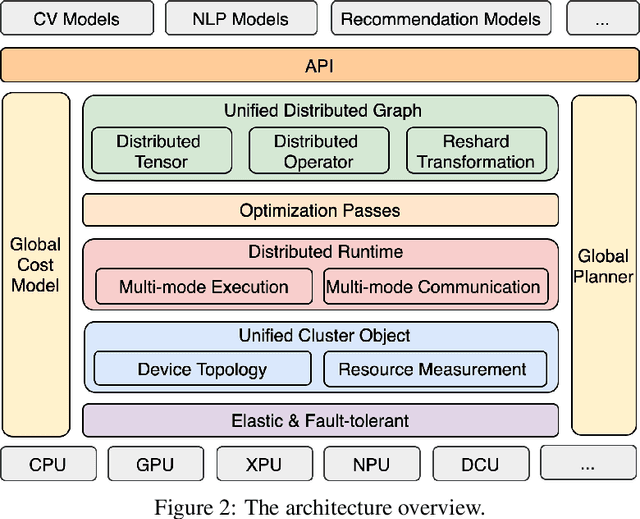
Distributed training has become a pervasive and effective approach for training a large neural network (NN) model with processing massive data. However, it is very challenging to satisfy requirements from various NN models, diverse computing resources, and their dynamic changes during a training job. In this study, we design our distributed training framework in a systematic end-to-end view to provide the built-in adaptive ability for different scenarios, especially for industrial applications and production environments, by fully considering resource allocation, model partition, task placement, and distributed execution. Based on the unified distributed graph and the unified cluster object, our adaptive framework is equipped with a global cost model and a global planner, which can enable arbitrary parallelism, resource-aware placement, multi-mode execution, fault-tolerant, and elastic distributed training. The experiments demonstrate that our framework can satisfy various requirements from the diversity of applications and the heterogeneity of resources with highly competitive performance. The ERNIE language model with 260 billion parameters is efficiently trained on thousands of AI processors with 91.7% weak scalability. The throughput of the model from the recommender system by employing the heterogeneous pipeline asynchronous execution can be increased up to 2.1 times and 3.3 times that of the GPU-only and CPU-only training respectively. Moreover, the fault-tolerant and elastic distributed training have been successfully applied to the online industrial applications, which give a reduction of 34.49% in the number of failed long-term training jobs and an increase of 33.91% for the global scheduling efficiency in the production environment.