 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
PaddleOCR-VL-1.5: Towards a Multi-Task 0.9B VLM for Robust In-the-Wild Document Parsing
Jan 29, 2026We introduce PaddleOCR-VL-1.5, an upgraded model achieving a new state-of-the-art (SOTA) accuracy of 94.5% on OmniDocBench v1.5. To rigorously evaluate robustness against real-world physical distortions, including scanning, skew, warping, screen-photography, and illumination, we propose the Real5-OmniDocBench benchmark. Experimental results demonstrate that this enhanced model attains SOTA performance on the newly curated benchmark. Furthermore, we extend the model's capabilities by incorporating seal recognition and text spotting tasks, while remaining a 0.9B ultra-compact VLM with high efficiency. Code: https://github.com/PaddlePaddle/PaddleOCR
PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
Oct 16, 2025In this report, we propose PaddleOCR-VL, a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios.
SDWPF: A Dataset for Spatial Dynamic Wind Power Forecasting Challenge at KDD Cup 2022
Aug 08, 2022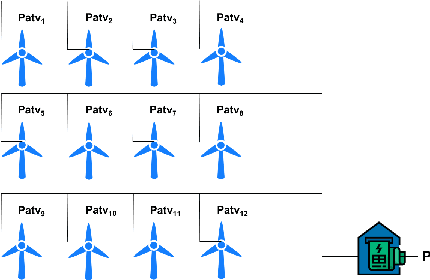


The variability of wind power supply can present substantial challenges to incorporating wind power into a grid system. Thus, Wind Power Forecasting (WPF) has been widely recognized as one of the most critical issues in wind power integration and operation. There has been an explosion of studies on wind power forecasting problems in the past decades. Nevertheless, how to well handle the WPF problem is still challenging, since high prediction accuracy is always demanded to ensure grid stability and security of supply. We present a unique Spatial Dynamic Wind Power Forecasting dataset: SDWPF, which includes the spatial distribution of wind turbines, as well as the dynamic context factors. Whereas, most of the existing datasets have only a small number of wind turbines without knowing the locations and context information of wind turbines at a fine-grained time scale. By contrast, SDWPF provides the wind power data of 134 wind turbines from a wind farm over half a year with their relative positions and internal statuses. We use this dataset to launch the Baidu KDD Cup 2022 to examine the limit of current WPF solutions. The dataset is released at https://aistudio.baidu.com/aistudio/competition/detail/152/0/datasets.
HelixFold: An Efficient Implementation of AlphaFold2 using PaddlePaddle
Jul 13, 2022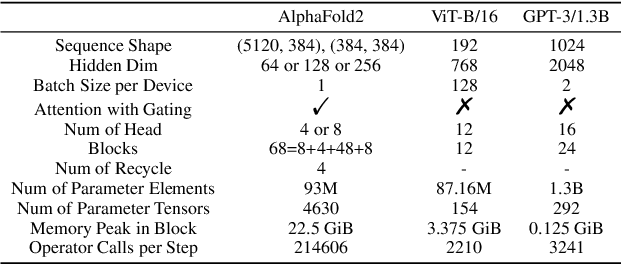
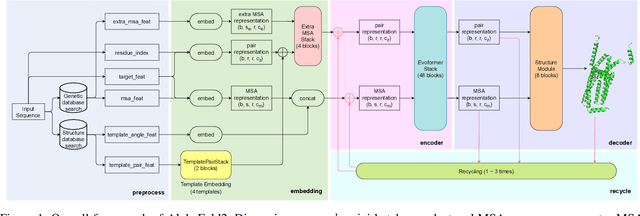

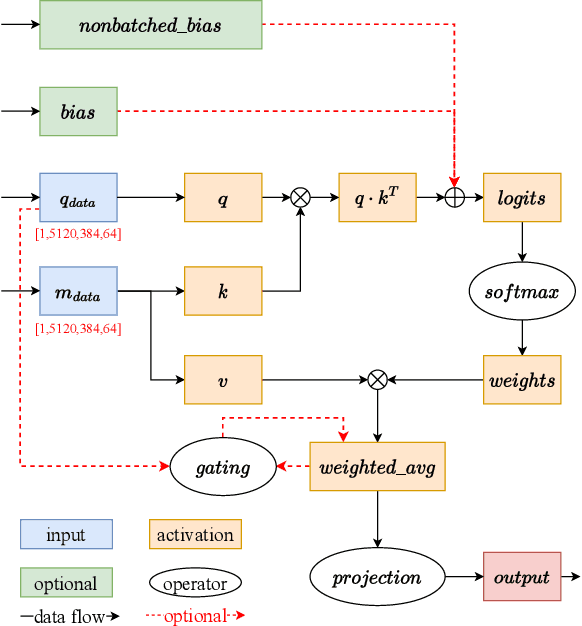
Accurate protein structure prediction can significantly accelerate the development of life science. The accuracy of AlphaFold2, a frontier end-to-end structure prediction system, is already close to that of the experimental determination techniques. Due to the complex model architecture and large memory consumption, it requires lots of computational resources and time to implement the training and inference of AlphaFold2 from scratch. The cost of running the original AlphaFold2 is expensive for most individuals and institutions. Therefore, reducing this cost could accelerate the development of life science. We implement AlphaFold2 using PaddlePaddle, namely HelixFold, to improve training and inference speed and reduce memory consumption. The performance is improved by operator fusion, tensor fusion, and hybrid parallelism computation, while the memory is optimized through Recompute, BFloat16, and memory read/write in-place. Compared with the original AlphaFold2 (implemented with Jax) and OpenFold (implemented with PyTorch), HelixFold needs only 7.5 days to complete the full end-to-end training and only 5.3 days when using hybrid parallelism, while both AlphaFold2 and OpenFold take about 11 days. HelixFold saves 1x training time. We verified that HelixFold's accuracy could be on par with AlphaFold2 on the CASP14 and CAMEO datasets. HelixFold's code is available on GitHub for free download: https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold, and we also provide stable web services on https://paddlehelix.baidu.com/app/drug/protein/forecast.
PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System
Jun 07, 2022

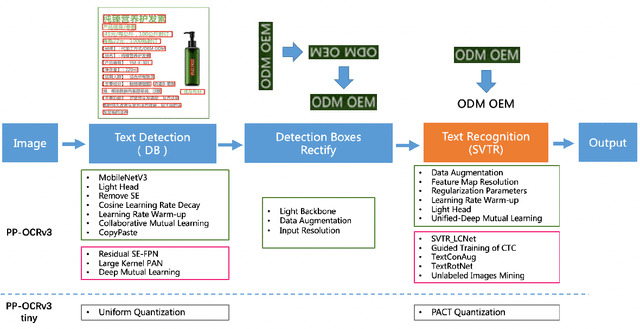
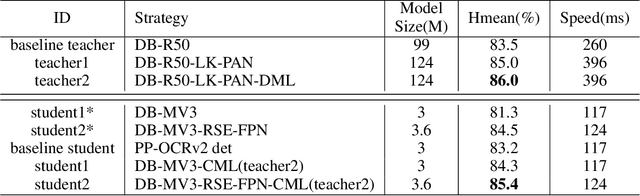
Optical character recognition (OCR) technology has been widely used in various scenes, as shown in Figure 1. Designing a practical OCR system is still a meaningful but challenging task. In previous work, considering the efficiency and accuracy, we proposed a practical ultra lightweight OCR system (PP-OCR), and an optimized version PP-OCRv2. In order to further improve the performance of PP-OCRv2, a more robust OCR system PP-OCRv3 is proposed in this paper. PP-OCRv3 upgrades the text detection model and text recognition model in 9 aspects based on PP-OCRv2. For text detector, we introduce a PAN module with large receptive field named LK-PAN, a FPN module with residual attention mechanism named RSE-FPN, and DML distillation strategy. For text recognizer, the base model is replaced from CRNN to SVTR, and we introduce lightweight text recognition network SVTR LCNet, guided training of CTC by attention, data augmentation strategy TextConAug, better pre-trained model by self-supervised TextRotNet, UDML, and UIM to accelerate the model and improve the effect. Experiments on real data show that the hmean of PP-OCRv3 is 5% higher than PP-OCRv2 under comparable inference speed. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.
PaddleSpeech: An Easy-to-Use All-in-One Speech Toolkit
May 20, 2022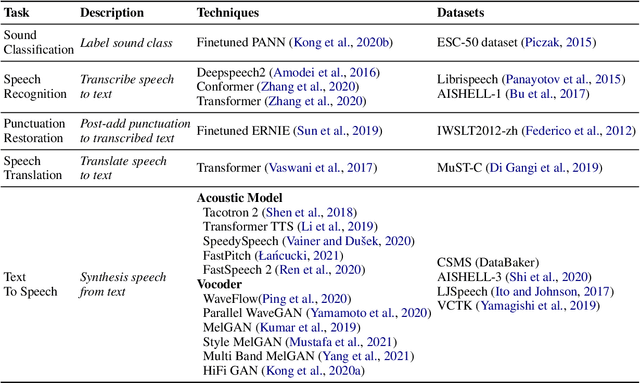
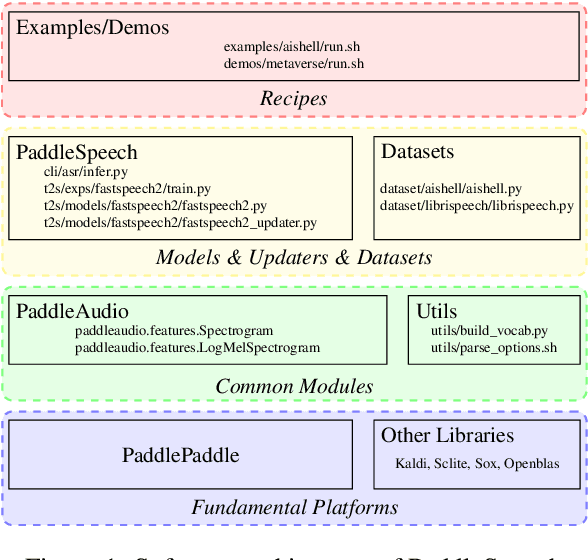
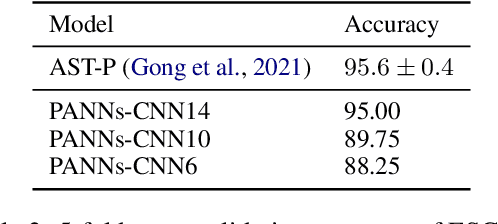
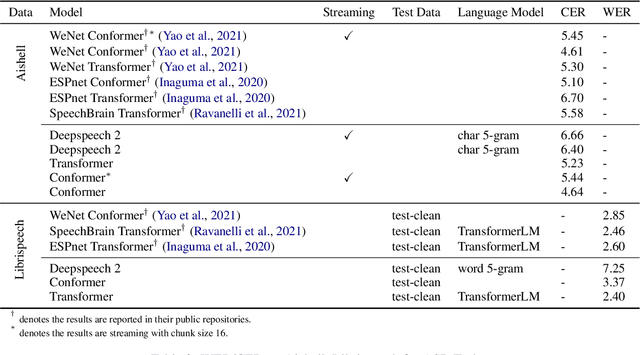
PaddleSpeech is an open-source all-in-one speech toolkit. It aims at facilitating the development and research of speech processing technologies by providing an easy-to-use command-line interface and a simple code structure. This paper describes the design philosophy and core architecture of PaddleSpeech to support several essential speech-to-text and text-to-speech tasks. PaddleSpeech achieves competitive or state-of-the-art performance on various speech datasets and implements the most popular methods. It also provides recipes and pretrained models to quickly reproduce the experimental results in this paper. PaddleSpeech is publicly avaiable at https://github.com/PaddlePaddle/PaddleSpeech.
SE-MoE: A Scalable and Efficient Mixture-of-Experts Distributed Training and Inference System
May 20, 2022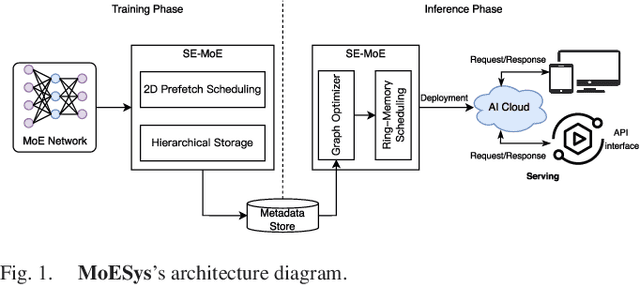
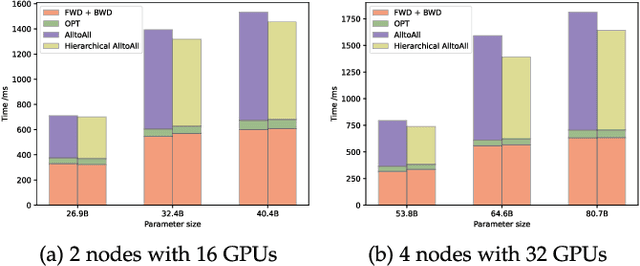
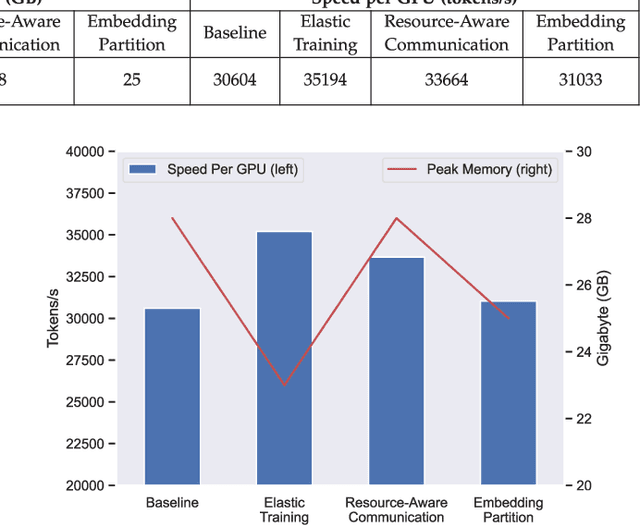
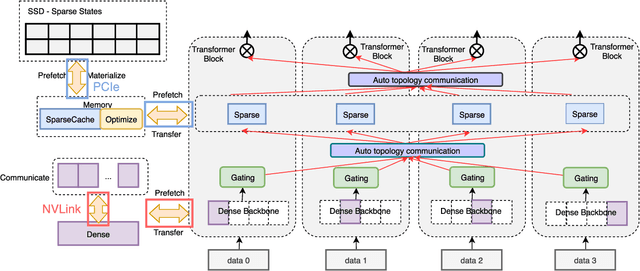
With the increasing diversity of ML infrastructures nowadays, distributed training over heterogeneous computing systems is desired to facilitate the production of big models. Mixture-of-Experts (MoE) models have been proposed to lower the cost of training subject to the overall size of models/data through gating and parallelism in a divide-and-conquer fashion. While DeepSpeed has made efforts in carrying out large-scale MoE training over heterogeneous infrastructures, the efficiency of training and inference could be further improved from several system aspects, including load balancing, communication/computation efficiency, and memory footprint limits. In this work, we present SE-MoE that proposes Elastic MoE training with 2D prefetch and Fusion communication over Hierarchical storage, so as to enjoy efficient parallelisms in various types. For scalable inference in a single node, especially when the model size is larger than GPU memory, SE-MoE forms the CPU-GPU memory jointly into a ring of sections to load the model, and executes the computation tasks across the memory sections in a round-robin manner for efficient inference. We carried out extensive experiments to evaluate SE-MoE, where SE-MoE successfully trains a Unified Feature Optimization (UFO) model with a Sparsely-Gated Mixture-of-Experts model of 12B parameters in 8 days on 48 A100 GPU cards. The comparison against the state-of-the-art shows that SE-MoE outperformed DeepSpeed with 33% higher throughput (tokens per second) in training and 13% higher throughput in inference in general. Particularly, under unbalanced MoE Tasks, e.g., UFO, SE-MoE achieved 64% higher throughput with 18% lower memory footprints. The code of the framework will be released on: https://github.com/PaddlePaddle/Paddle.
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022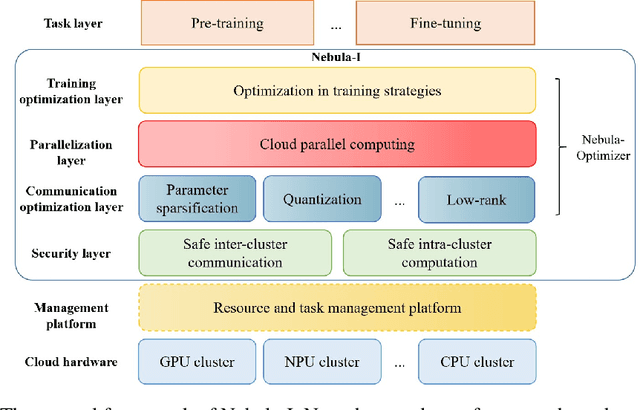
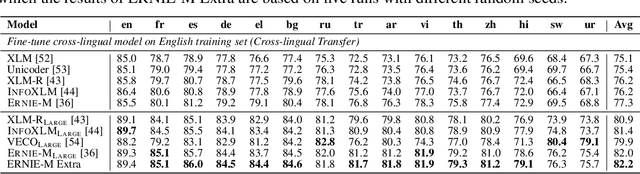
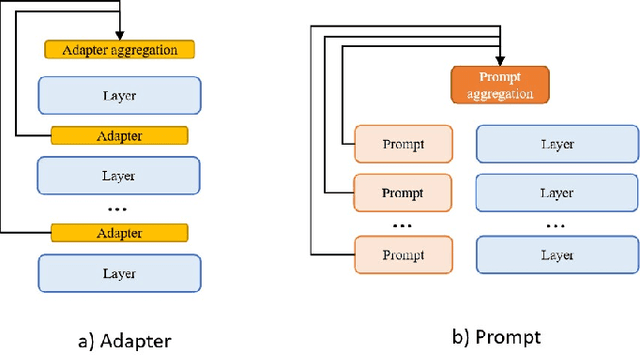
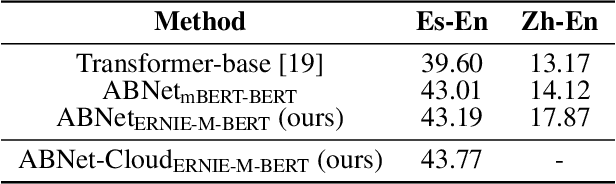
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
Apr 06, 2022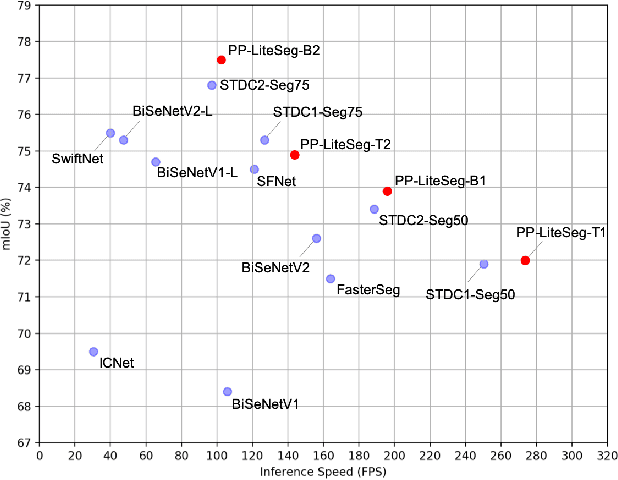

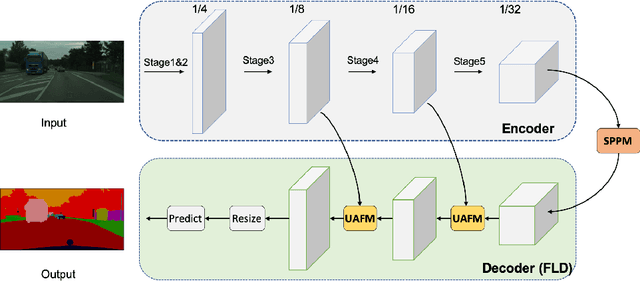
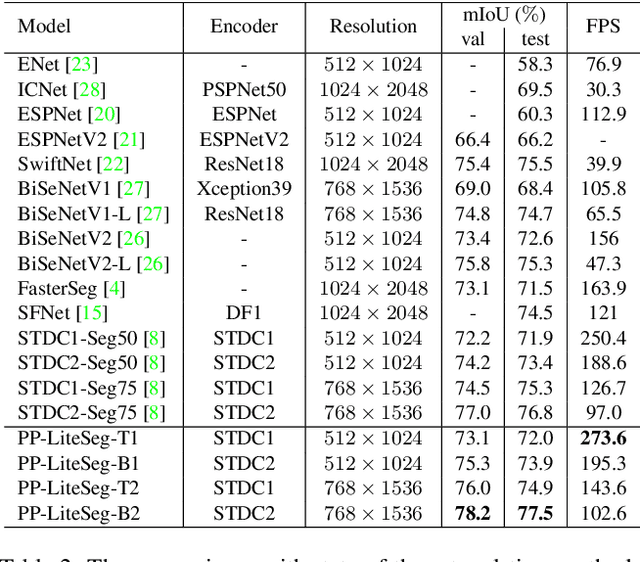
Real-world applications have high demands for semantic segmentation methods. Although semantic segmentation has made remarkable leap-forwards with deep learning, the performance of real-time methods is not satisfactory. In this work, we propose PP-LiteSeg, a novel lightweight model for the real-time semantic segmentation task. Specifically, we present a Flexible and Lightweight Decoder (FLD) to reduce computation overhead of previous decoder. To strengthen feature representations, we propose a Unified Attention Fusion Module (UAFM), which takes advantage of spatial and channel attention to produce a weight and then fuses the input features with the weight. Moreover, a Simple Pyramid Pooling Module (SPPM) is proposed to aggregate global context with low computation cost. Extensive evaluations demonstrate that PP-LiteSeg achieves a superior trade-off between accuracy and speed compared to other methods. On the Cityscapes test set, PP-LiteSeg achieves 72.0% mIoU/273.6 FPS and 77.5% mIoU/102.6 FPS on NVIDIA GTX 1080Ti. Source code and models are available at PaddleSeg: https://github.com/PaddlePaddle/PaddleSeg.