 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Collaboration in Multi-Agent Flow Networks
May 13, 2026Multi-agent systems provide a powerful way to extend large language models (LLMs) by decomposing a complex task into specialized subtasks handled by different agents. However, their performance is often hindered by error propagation, arising from suboptimal workflow design or inaccurate agent outputs, which can propagate through the agent collaboration process and degrade final results. To address the challenges, we present MANGO (Multi-Agent Network Gradient Optimization), a data-driven framework that organizes and refines agent collaboration via a flow network constructed from past successful workflows. MANGO integrates reinforcement learning and textual gradients to jointly optimize workflow paths and agent behaviors, while a skipping mechanism prevents redundant updates to well-optimized agents for improving efficiency. Extensive experiments on seven benchmarks show that MANGO achieves up to 12.8% performance improvement over state-of-the-art baselines, enhances efficiency by 47.4%, and generalizes effectively to unseen domains. Our code and datasets are publicly available at https://github.com/openJiuwen-ai/agent-store/tree/main/community/mango.
ERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Nested-TNT: Hierarchical Vision Transformers with Multi-Scale Feature Processing
Apr 20, 2024


Transformer has been applied in the field of computer vision due to its excellent performance in natural language processing, surpassing traditional convolutional neural networks and achieving new state-of-the-art. ViT divides an image into several local patches, known as "visual sentences". However, the information contained in the image is vast and complex, and focusing only on the features at the "visual sentence" level is not enough. The features between local patches should also be taken into consideration. In order to achieve further improvement, the TNT model is proposed, whose algorithm further divides the image into smaller patches, namely "visual words," achieving more accurate results. The core of Transformer is the Multi-Head Attention mechanism, and traditional attention mechanisms ignore interactions across different attention heads. In order to reduce redundancy and improve utilization, we introduce the nested algorithm and apply the Nested-TNT to image classification tasks. The experiment confirms that the proposed model has achieved better classification performance over ViT and TNT, exceeding 2.25%, 1.1% on dataset CIFAR10 and 2.78%, 0.25% on dataset FLOWERS102 respectively.
DMT: Comprehensive Distillation with Multiple Self-supervised Teachers
Dec 19, 2023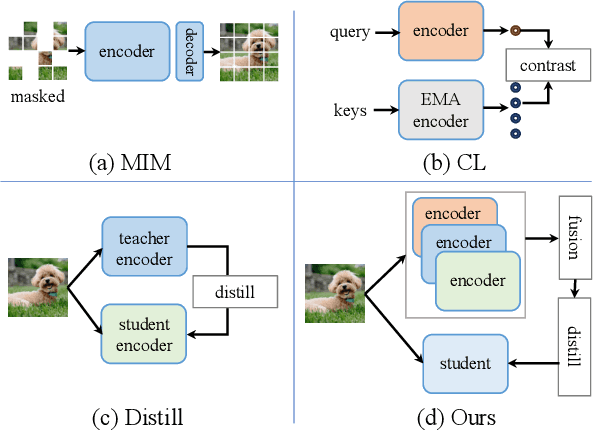
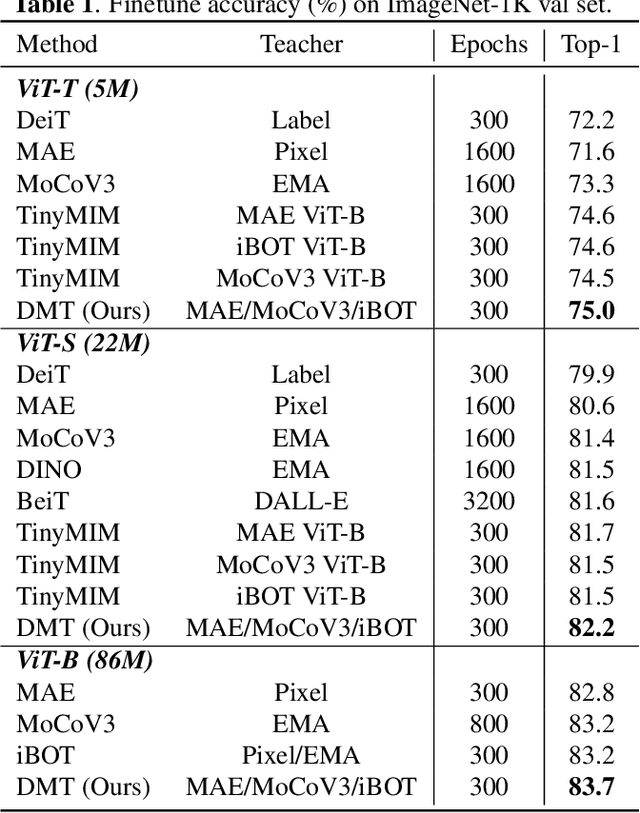
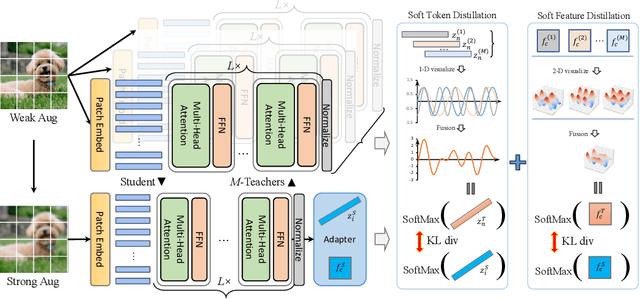
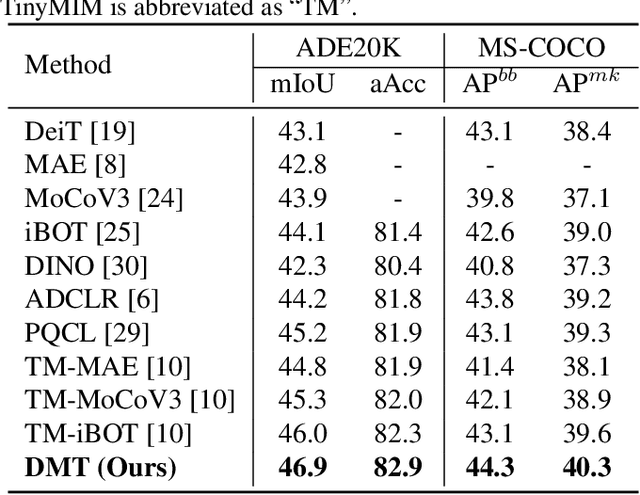
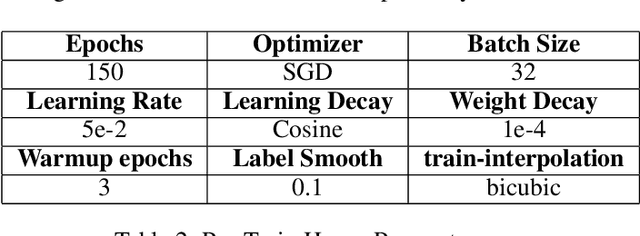
Numerous self-supervised learning paradigms, such as contrastive learning and masked image modeling, have been proposed to acquire powerful and general representations from unlabeled data. However, these models are commonly pretrained within their specific framework alone, failing to consider the complementary nature of visual representations. To tackle this issue, we introduce Comprehensive Distillation with Multiple Self-supervised Teachers (DMT) for pretrained model compression, which leverages the strengths of multiple off-the-shelf self-supervised models. Our experimental results on prominent benchmark datasets exhibit that the proposed method significantly surpasses state-of-the-art competitors while retaining favorable efficiency metrics. On classification tasks, our DMT framework utilizing three different self-supervised ViT-Base teachers enhances the performance of both small/tiny models and the base model itself. For dense tasks, DMT elevates the AP/mIoU of standard SSL models on MS-COCO and ADE20K datasets by 4.0%.
Language-guided Few-shot Semantic Segmentation
Nov 23, 2023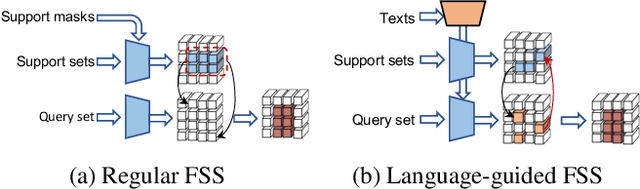
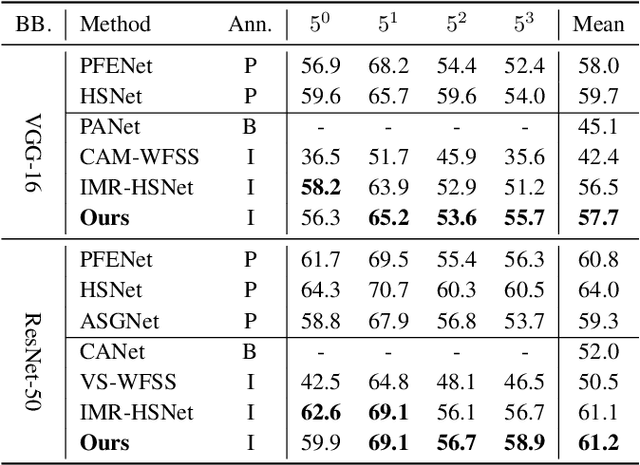
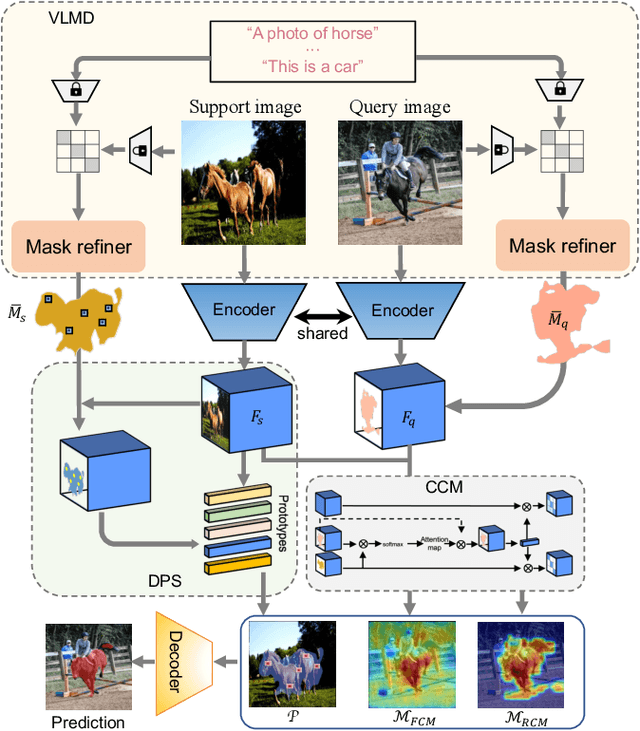
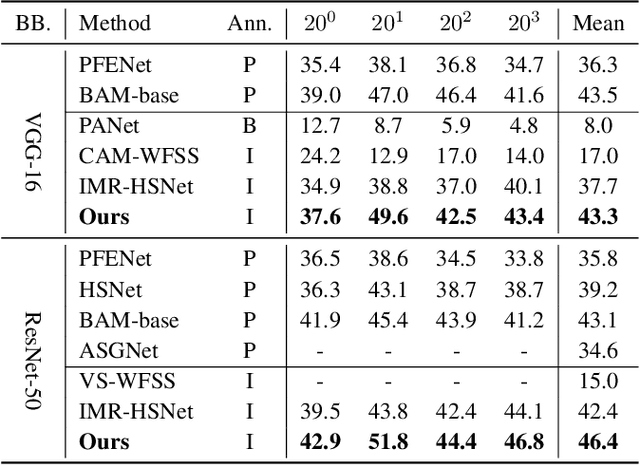
Few-shot learning is a promising way for reducing the label cost in new categories adaptation with the guidance of a small, well labeled support set. But for few-shot semantic segmentation, the pixel-level annotations of support images are still expensive. In this paper, we propose an innovative solution to tackle the challenge of few-shot semantic segmentation using only language information, i.e.image-level text labels. Our approach involves a vision-language-driven mask distillation scheme, which contains a vision-language pretraining (VLP) model and a mask refiner, to generate high quality pseudo-semantic masks from text prompts. We additionally introduce a distributed prototype supervision method and complementary correlation matching module to guide the model in digging precise semantic relations among support and query images. The experiments on two benchmark datasets demonstrate that our method establishes a new baseline for language-guided few-shot semantic segmentation and achieves competitive results to recent vision-guided methods.
ES-MVSNet: Efficient Framework for End-to-end Self-supervised Multi-View Stereo
Aug 04, 2023



Compared to the multi-stage self-supervised multi-view stereo (MVS) method, the end-to-end (E2E) approach has received more attention due to its concise and efficient training pipeline. Recent E2E self-supervised MVS approaches have integrated third-party models (such as optical flow models, semantic segmentation models, NeRF models, etc.) to provide additional consistency constraints, which grows GPU memory consumption and complicates the model's structure and training pipeline. In this work, we propose an efficient framework for end-to-end self-supervised MVS, dubbed ES-MVSNet. To alleviate the high memory consumption of current E2E self-supervised MVS frameworks, we present a memory-efficient architecture that reduces memory usage by 43% without compromising model performance. Furthermore, with the novel design of asymmetric view selection policy and region-aware depth consistency, we achieve state-of-the-art performance among E2E self-supervised MVS methods, without relying on third-party models for additional consistency signals. Extensive experiments on DTU and Tanks&Temples benchmarks demonstrate that the proposed ES-MVSNet approach achieves state-of-the-art performance among E2E self-supervised MVS methods and competitive performance to many supervised and multi-stage self-supervised methods.
Dynamic Token-Pass Transformers for Semantic Segmentation
Aug 03, 2023
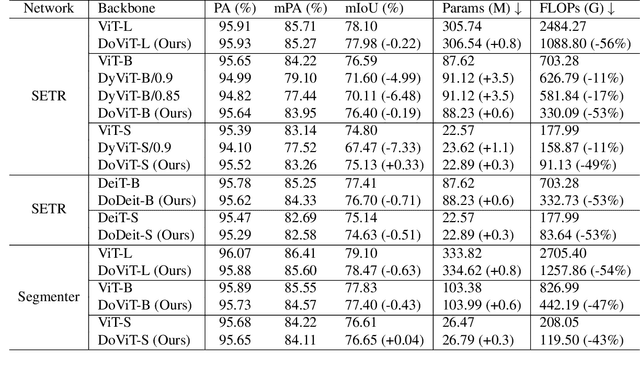
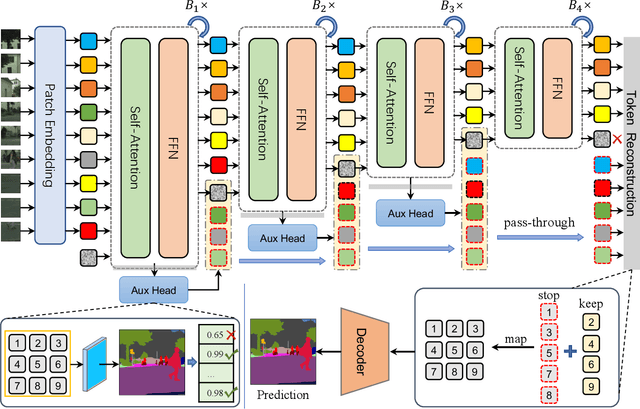
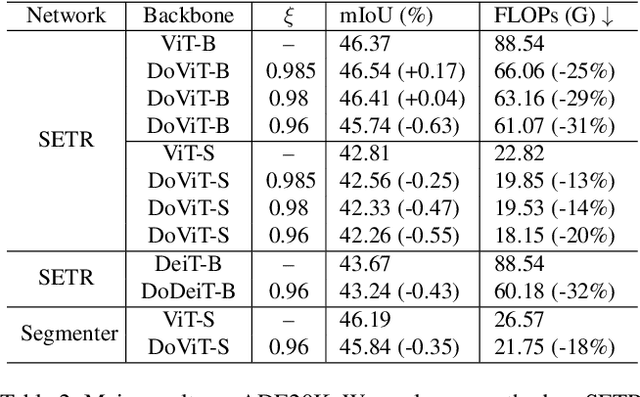
Vision transformers (ViT) usually extract features via forwarding all the tokens in the self-attention layers from top to toe. In this paper, we introduce dynamic token-pass vision transformers (DoViT) for semantic segmentation, which can adaptively reduce the inference cost for images with different complexity. DoViT gradually stops partial easy tokens from self-attention calculation and keeps the hard tokens forwarding until meeting the stopping criteria. We employ lightweight auxiliary heads to make the token-pass decision and divide the tokens into keeping/stopping parts. With a token separate calculation, the self-attention layers are speeded up with sparse tokens and still work friendly with hardware. A token reconstruction module is built to collect and reset the grouped tokens to their original position in the sequence, which is necessary to predict correct semantic masks. We conduct extensive experiments on two common semantic segmentation tasks, and demonstrate that our method greatly reduces about 40% $\sim$ 60% FLOPs and the drop of mIoU is within 0.8% for various segmentation transformers. The throughput and inference speed of ViT-L/B are increased to more than 2$\times$ on Cityscapes.
LMSeg: Language-guided Multi-dataset Segmentation
Feb 27, 2023



It's a meaningful and attractive topic to build a general and inclusive segmentation model that can recognize more categories in various scenarios. A straightforward way is to combine the existing fragmented segmentation datasets and train a multi-dataset network. However, there are two major issues with multi-dataset segmentation: (1) the inconsistent taxonomy demands manual reconciliation to construct a unified taxonomy; (2) the inflexible one-hot common taxonomy causes time-consuming model retraining and defective supervision of unlabeled categories. In this paper, we investigate the multi-dataset segmentation and propose a scalable Language-guided Multi-dataset Segmentation framework, dubbed LMSeg, which supports both semantic and panoptic segmentation. Specifically, we introduce a pre-trained text encoder to map the category names to a text embedding space as a unified taxonomy, instead of using inflexible one-hot label. The model dynamically aligns the segment queries with the category embeddings. Instead of relabeling each dataset with the unified taxonomy, a category-guided decoding module is designed to dynamically guide predictions to each datasets taxonomy. Furthermore, we adopt a dataset-aware augmentation strategy that assigns each dataset a specific image augmentation pipeline, which can suit the properties of images from different datasets. Extensive experiments demonstrate that our method achieves significant improvements on four semantic and three panoptic segmentation datasets, and the ablation study evaluates the effectiveness of each component.
Nebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022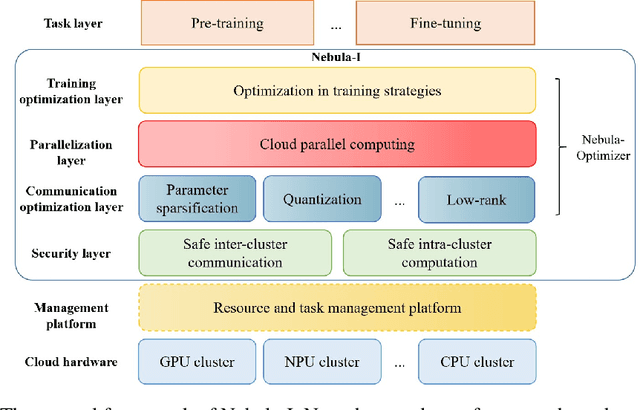
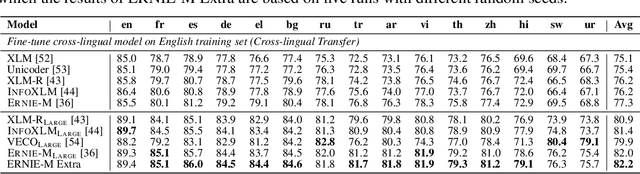
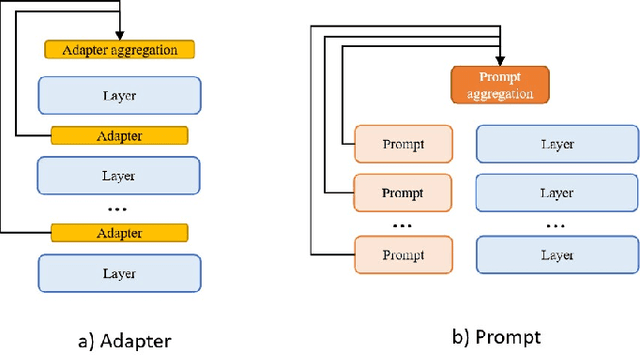
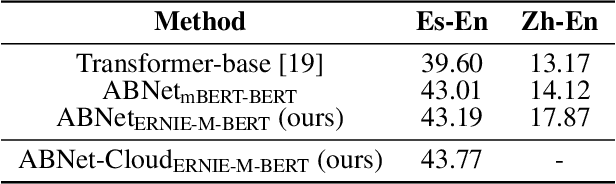
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
Data-Free Knowledge Transfer: A Survey
Dec 31, 2021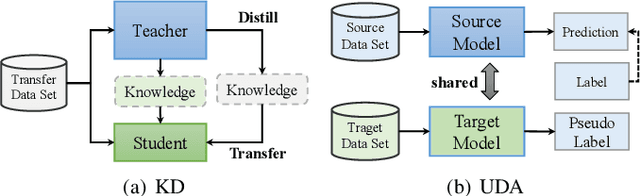

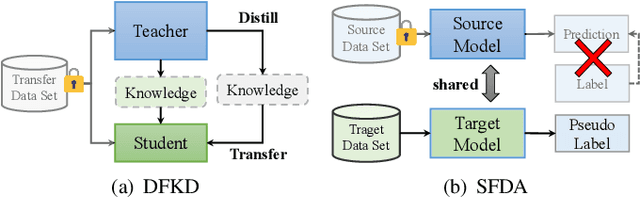
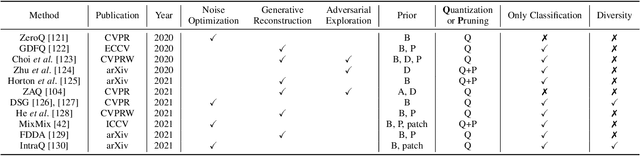
In the last decade, many deep learning models have been well trained and made a great success in various fields of machine intelligence, especially for computer vision and natural language processing. To better leverage the potential of these well-trained models in intra-domain or cross-domain transfer learning situations, knowledge distillation (KD) and domain adaptation (DA) are proposed and become research highlights. They both aim to transfer useful information from a well-trained model with original training data. However, the original data is not always available in many cases due to privacy, copyright or confidentiality. Recently, the data-free knowledge transfer paradigm has attracted appealing attention as it deals with distilling valuable knowledge from well-trained models without requiring to access to the training data. In particular, it mainly consists of the data-free knowledge distillation (DFKD) and source data-free domain adaptation (SFDA). On the one hand, DFKD aims to transfer the intra-domain knowledge of original data from a cumbersome teacher network to a compact student network for model compression and efficient inference. On the other hand, the goal of SFDA is to reuse the cross-domain knowledge stored in a well-trained source model and adapt it to a target domain. In this paper, we provide a comprehensive survey on data-free knowledge transfer from the perspectives of knowledge distillation and unsupervised domain adaptation, to help readers have a better understanding of the current research status and ideas. Applications and challenges of the two areas are briefly reviewed, respectively. Furthermore, we provide some insights to the subject of future research.