 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Free Knowledge Transfer: A Survey
Paper and Code
Dec 31, 2021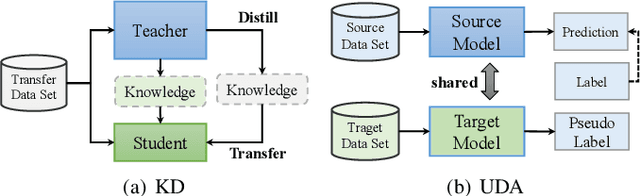

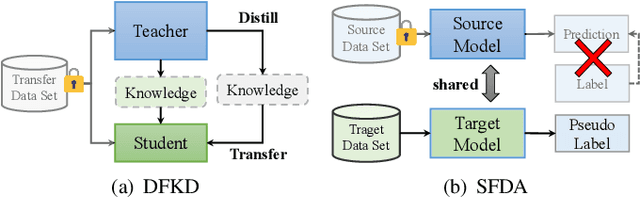
In the last decade, many deep learning models have been well trained and made a great success in various fields of machine intelligence, especially for computer vision and natural language processing. To better leverage the potential of these well-trained models in intra-domain or cross-domain transfer learning situations, knowledge distillation (KD) and domain adaptation (DA) are proposed and become research highlights. They both aim to transfer useful information from a well-trained model with original training data. However, the original data is not always available in many cases due to privacy, copyright or confidentiality. Recently, the data-free knowledge transfer paradigm has attracted appealing attention as it deals with distilling valuable knowledge from well-trained models without requiring to access to the training data. In particular, it mainly consists of the data-free knowledge distillation (DFKD) and source data-free domain adaptation (SFDA). On the one hand, DFKD aims to transfer the intra-domain knowledge of original data from a cumbersome teacher network to a compact student network for model compression and efficient inference. On the other hand, the goal of SFDA is to reuse the cross-domain knowledge stored in a well-trained source model and adapt it to a target domain. In this paper, we provide a comprehensive survey on data-free knowledge transfer from the perspectives of knowledge distillation and unsupervised domain adaptation, to help readers have a better understanding of the current research status and ideas. Applications and challenges of the two areas are briefly reviewed, respectively. Furthermore, we provide some insights to the subject of future research.