 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNebula-I: A General Framework for Collaboratively Training Deep Learning Models on Low-Bandwidth Cloud Clusters
May 19, 2022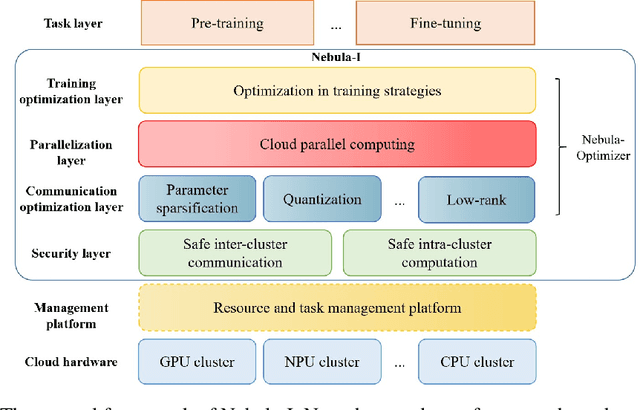
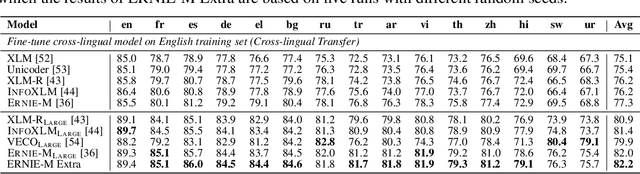
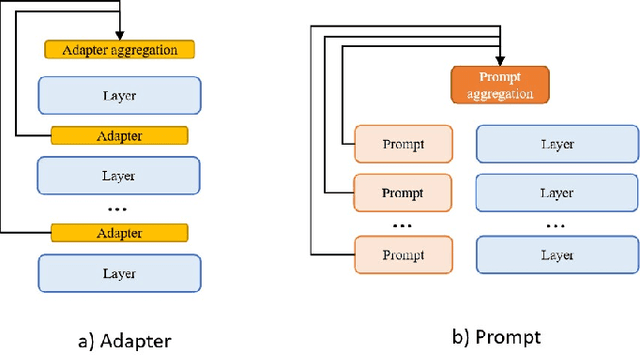
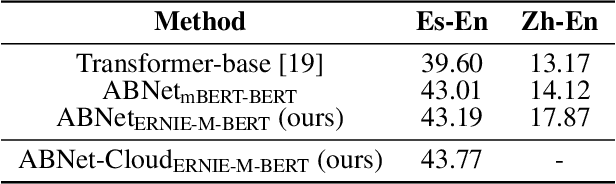
The ever-growing model size and scale of compute have attracted increasing interests in training deep learning models over multiple nodes. However, when it comes to training on cloud clusters, especially across remote clusters, huge challenges are faced. In this work, we introduce a general framework, Nebula-I, for collaboratively training deep learning models over remote heterogeneous clusters, the connections between which are low-bandwidth wide area networks (WANs). We took natural language processing (NLP) as an example to show how Nebula-I works in different training phases that include: a) pre-training a multilingual language model using two remote clusters; and b) fine-tuning a machine translation model using knowledge distilled from pre-trained models, which run through the most popular paradigm of recent deep learning. To balance the accuracy and communication efficiency, in Nebula-I, parameter-efficient training strategies, hybrid parallel computing methods and adaptive communication acceleration techniques are jointly applied. Meanwhile, security strategies are employed to guarantee the safety, reliability and privacy in intra-cluster computation and inter-cluster communication. Nebula-I is implemented with the PaddlePaddle deep learning framework, which can support collaborative training over heterogeneous hardware, e.g. GPU and NPU. Experiments demonstrate that the proposed framework could substantially maximize the training efficiency while preserving satisfactory NLP performance. By using Nebula-I, users can run large-scale training tasks over cloud clusters with minimum developments, and the utility of existed large pre-trained models could be further promoted. We also introduced new state-of-the-art results on cross-lingual natural language inference tasks, which are generated based upon a novel learning framework and Nebula-I.
Cross-X Learning for Fine-Grained Visual Categorization
Sep 10, 2019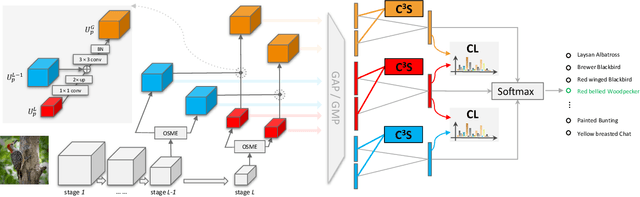
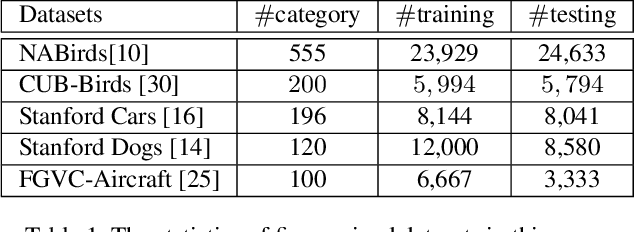
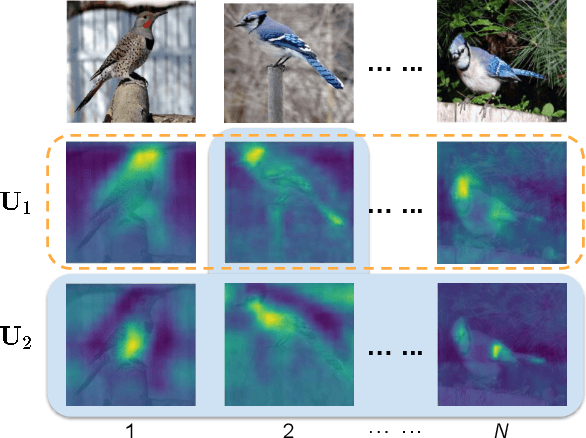
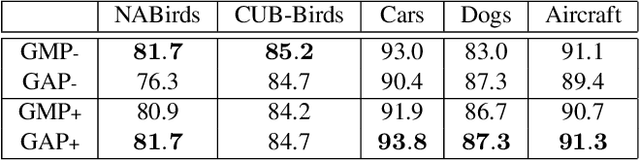
Recognizing objects from subcategories with very subtle differences remains a challenging task due to the large intra-class and small inter-class variation. Recent work tackles this problem in a weakly-supervised manner: object parts are first detected and the corresponding part-specific features are extracted for fine-grained classification. However, these methods typically treat the part-specific features of each image in isolation while neglecting their relationships between different images. In this paper, we propose Cross-X learning, a simple yet effective approach that exploits the relationships between different images and between different network layers for robust multi-scale feature learning. Our approach involves two novel components: (i) a cross-category cross-semantic regularizer that guides the extracted features to represent semantic parts and, (ii) a cross-layer regularizer that improves the robustness of multi-scale features by matching the prediction distribution across multiple layers. Our approach can be easily trained end-to-end and is scalable to large datasets like NABirds. We empirically analyze the contributions of different components of our approach and demonstrate its robustness, effectiveness and state-of-the-art performance on five benchmark datasets. Code is available at \url{https://github.com/cswluo/CrossX}.