 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Binary Neural Network
Jan 07, 2025



Binary Neural Network (BNN) converts full-precision weights and activations into their extreme 1-bit counterparts, making it particularly suitable for deployment on lightweight mobile devices. While binary neural networks are typically formulated as a constrained optimization problem and optimized in the binarized space, general neural networks are formulated as an unconstrained optimization problem and optimized in the continuous space. This paper introduces the Hyperbolic Binary Neural Network (HBNN) by leveraging the framework of hyperbolic geometry to optimize the constrained problem. Specifically, we transform the constrained problem in hyperbolic space into an unconstrained one in Euclidean space using the Riemannian exponential map. On the other hand, we also propose the Exponential Parametrization Cluster (EPC) method, which, compared to the Riemannian exponential map, shrinks the segment domain based on a diffeomorphism. This approach increases the probability of weight flips, thereby maximizing the information gain in BNNs. Experimental results on CIFAR10, CIFAR100, and ImageNet classification datasets with VGGsmall, ResNet18, and ResNet34 models illustrate the superior performance of our HBNN over state-of-the-art methods.
Learnable Chamfer Distance for Point Cloud Reconstruction
Dec 27, 2023



As point clouds are 3D signals with permutation invariance, most existing works train their reconstruction networks by measuring shape differences with the average point-to-point distance between point clouds matched with predefined rules. However, the static matching rules may deviate from actual shape differences. Although some works propose dynamically-updated learnable structures to replace matching rules, they need more iterations to converge well. In this work, we propose a simple but effective reconstruction loss, named Learnable Chamfer Distance (LCD) by dynamically paying attention to matching distances with different weight distributions controlled with a group of learnable networks. By training with adversarial strategy, LCD learns to search defects in reconstructed results and overcomes the weaknesses of static matching rules, while the performances at low iterations can also be guaranteed by the basic matching algorithm. Experiments on multiple reconstruction networks confirm that LCD can help achieve better reconstruction performances and extract more representative representations with faster convergence and comparable training efficiency. The source codes are provided in https://github.com/Tianxinhuang/LCDNet.git.
Camera-based 3D Semantic Scene Completion with Sparse Guidance Network
Dec 10, 2023



Semantic scene completion (SSC) aims to predict the semantic occupancy of each voxel in the entire 3D scene from limited observations, which is an emerging and critical task for autonomous driving. Recently, many studies have turned to camera-based SSC solutions due to the richer visual cues and cost-effectiveness of cameras. However, existing methods usually rely on sophisticated and heavy 3D models to directly process the lifted 3D features that are not discriminative enough for clear segmentation boundaries. In this paper, we adopt the dense-sparse-dense design and propose an end-to-end camera-based SSC framework, termed SGN, to diffuse semantics from the semantic- and occupancy-aware seed voxels to the whole scene based on geometry prior and occupancy information. By designing hybrid guidance (sparse semantic and geometry guidance) and effective voxel aggregation for spatial occupancy and geometry priors, we enhance the feature separation between different categories and expedite the convergence of semantic diffusion. Extensive experimental results on the SemanticKITTI dataset demonstrate the superiority of our SGN over existing state-of-the-art methods.
OverlapNetVLAD: A Coarse-to-Fine Framework for LiDAR-based Place Recognition
Mar 13, 2023Place recognition is a challenging yet crucial task in robotics. Existing 3D LiDAR place recognition methods suffer from limited feature representation capability and long search times. To address these challenges, we propose a novel coarse-to-fine framework for 3D LiDAR place recognition that combines Birds' Eye View (BEV) feature extraction, coarse-grained matching, and fine-grained verification. In the coarse stage, our framework leverages the rich contextual information contained in BEV features to produce global descriptors. Then the top-\textit{K} most similar candidates are identified via descriptor matching, which is fast but coarse-grained. In the fine stage, our overlap estimation network reuses the corresponding BEV features to predict the overlap region, enabling meticulous and precise matching. Experimental results on the KITTI odometry benchmark demonstrate that our framework achieves leading performance compared to state-of-the-art methods. Our code is available at: \url{https://github.com/fcchit/OverlapNetVLAD}.
SuperLine3D: Self-supervised Line Segmentation and Description for LiDAR Point Cloud
Aug 03, 2022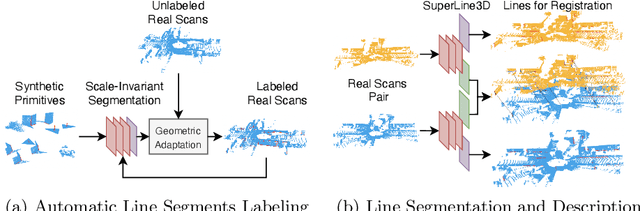
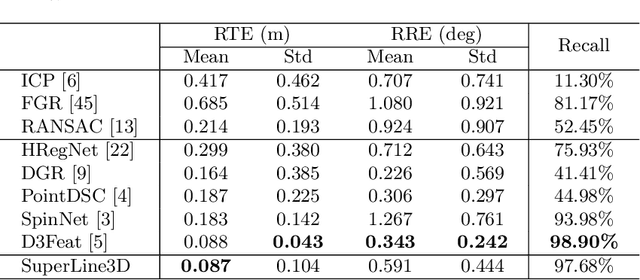
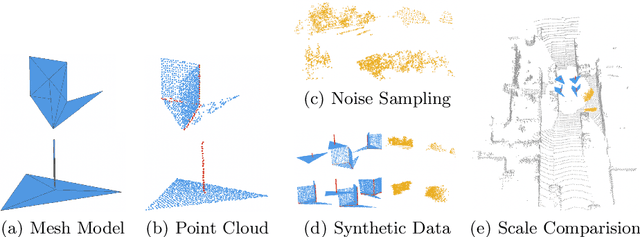

Poles and building edges are frequently observable objects on urban roads, conveying reliable hints for various computer vision tasks. To repetitively extract them as features and perform association between discrete LiDAR frames for registration, we propose the first learning-based feature segmentation and description model for 3D lines in LiDAR point cloud. To train our model without the time consuming and tedious data labeling process, we first generate synthetic primitives for the basic appearance of target lines, and build an iterative line auto-labeling process to gradually refine line labels on real LiDAR scans. Our segmentation model can extract lines under arbitrary scale perturbations, and we use shared EdgeConv encoder layers to train the two segmentation and descriptor heads jointly. Base on the model, we can build a highly-available global registration module for point cloud registration, in conditions without initial transformation hints. Experiments have demonstrated that our line-based registration method is highly competitive to state-of-the-art point-based approaches. Our code is available at https://github.com/zxrzju/SuperLine3D.git.
Dynamically Stable Poincaré Embeddings for Neural Manifolds
Dec 21, 2021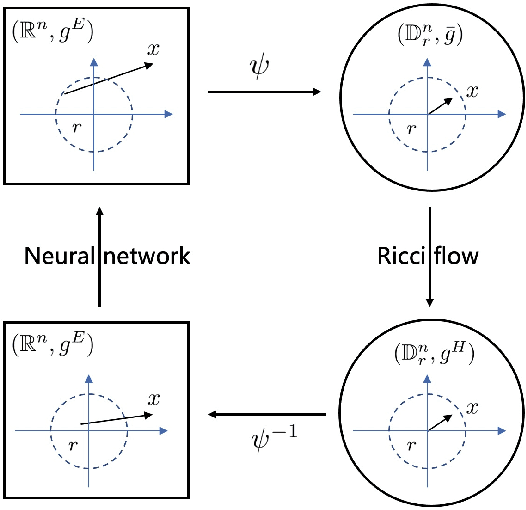
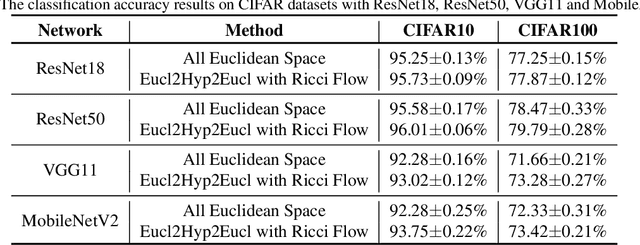
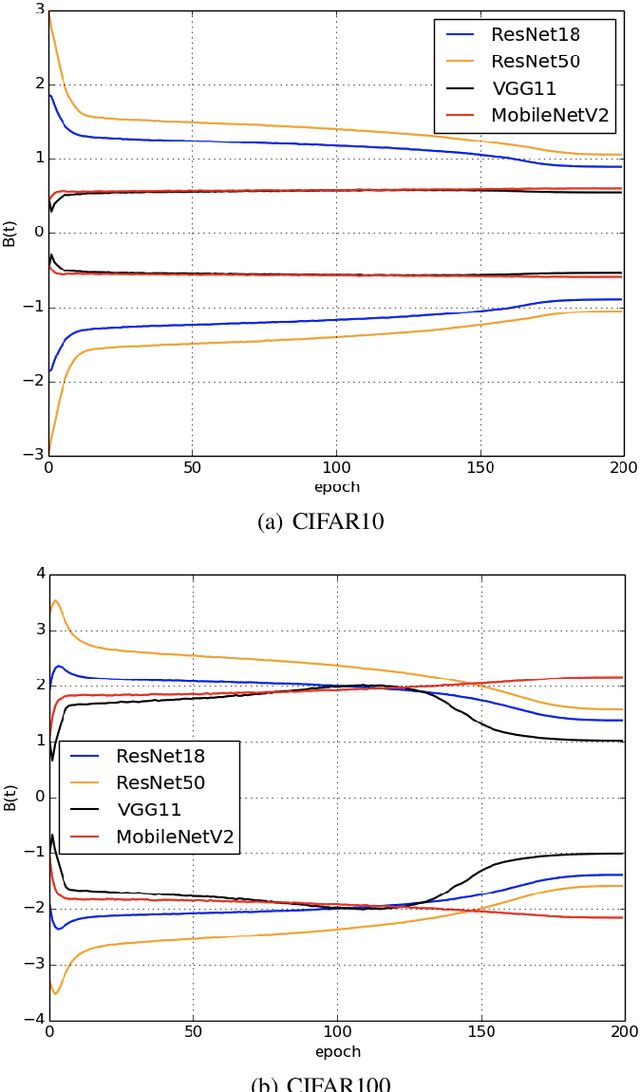
In a Riemannian manifold, the Ricci flow is a partial differential equation for evolving the metric to become more regular. We hope that topological structures from such metrics may be used to assist in the tasks of machine learning. However, this part of the work is still missing. In this paper, we bridge this gap between the Ricci flow and deep neural networks by dynamically stable Poincar\'e embeddings for neural manifolds. As a result, we prove that, if initial metrics have an $L^2$-norm perturbation which deviates from the Hyperbolic metric on the Poincar\'e ball, the scaled Ricci-DeTurck flow of such metrics smoothly and exponentially converges to the Hyperbolic metric. Specifically, the role of the Ricci flow is to serve as naturally evolving to the stable Poincar\'e ball that will then be mapped back to the Euclidean space. For such dynamically stable neural manifolds under the Ricci flow, the convergence of neural networks embedded with such manifolds is not susceptible to perturbations. And we show that such Ricci flow assisted neural networks outperform with their all Euclidean versions on image classification tasks (CIFAR datasets).
SSC: Semantic Scan Context for Large-Scale Place Recognition
Jul 10, 2021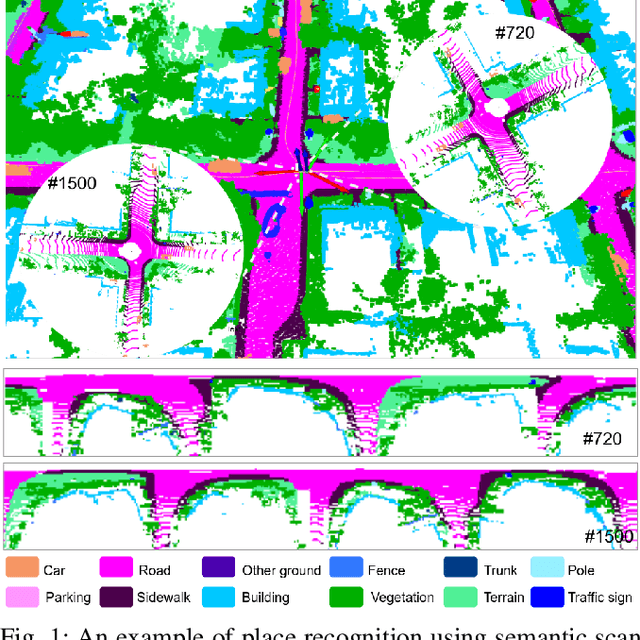

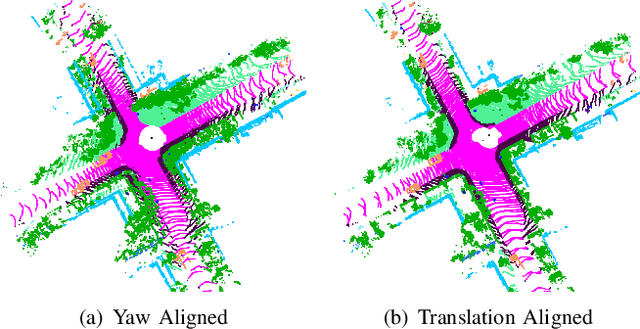
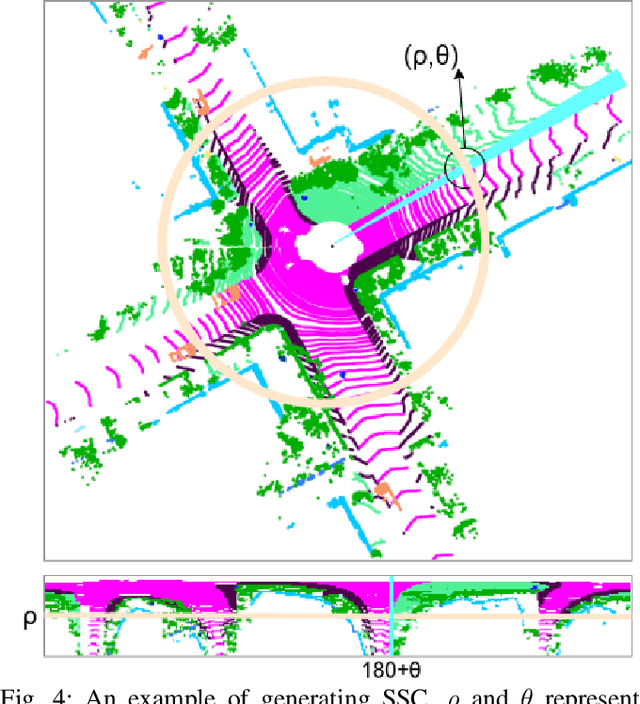
Place recognition gives a SLAM system the ability to correct cumulative errors. Unlike images that contain rich texture features, point clouds are almost pure geometric information which makes place recognition based on point clouds challenging. Existing works usually encode low-level features such as coordinate, normal, reflection intensity, etc., as local or global descriptors to represent scenes. Besides, they often ignore the translation between point clouds when matching descriptors. Different from most existing methods, we explore the use of high-level features, namely semantics, to improve the descriptor's representation ability. Also, when matching descriptors, we try to correct the translation between point clouds to improve accuracy. Concretely, we propose a novel global descriptor, Semantic Scan Context, which explores semantic information to represent scenes more effectively. We also present a two-step global semantic ICP to obtain the 3D pose (x, y, yaw) used to align the point cloud to improve matching performance. Our experiments on the KITTI dataset show that our approach outperforms the state-of-the-art methods with a large margin. Our code is available at: https://github.com/lilin-hitcrt/SSC.
SA-LOAM: Semantic-aided LiDAR SLAM with Loop Closure
Jul 01, 2021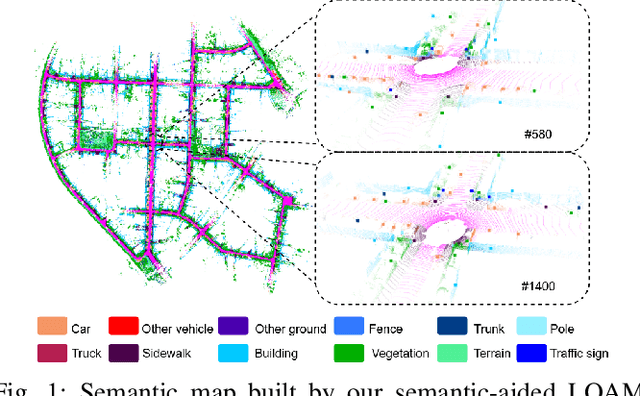
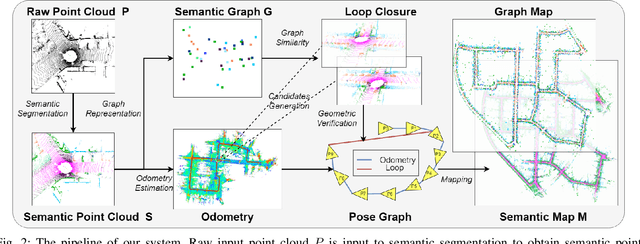

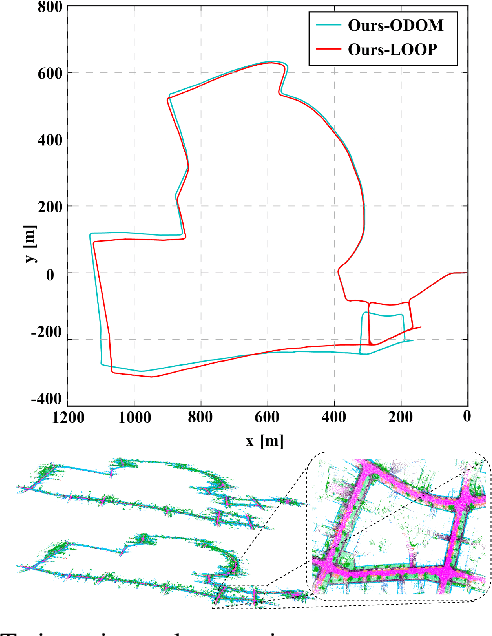
LiDAR-based SLAM system is admittedly more accurate and stable than others, while its loop closure detection is still an open issue. With the development of 3D semantic segmentation for point cloud, semantic information can be obtained conveniently and steadily, essential for high-level intelligence and conductive to SLAM. In this paper, we present a novel semantic-aided LiDAR SLAM with loop closure based on LOAM, named SA-LOAM, which leverages semantics in odometry as well as loop closure detection. Specifically, we propose a semantic-assisted ICP, including semantically matching, downsampling and plane constraint, and integrates a semantic graph-based place recognition method in our loop closure detection module. Benefitting from semantics, we can improve the localization accuracy, detect loop closures effectively, and construct a global consistent semantic map even in large-scale scenes. Extensive experiments on KITTI and Ford Campus dataset show that our system significantly improves baseline performance, has generalization ability to unseen data and achieves competitive results compared with state-of-the-art methods.
CL-MAPF: Multi-Agent Path Finding for Car-Like Robots with Kinematic and Spatiotemporal Constraints
Nov 01, 2020

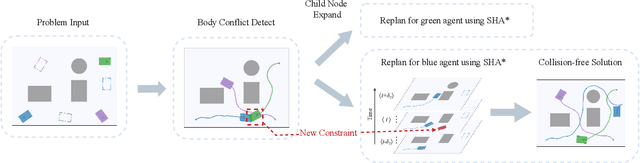
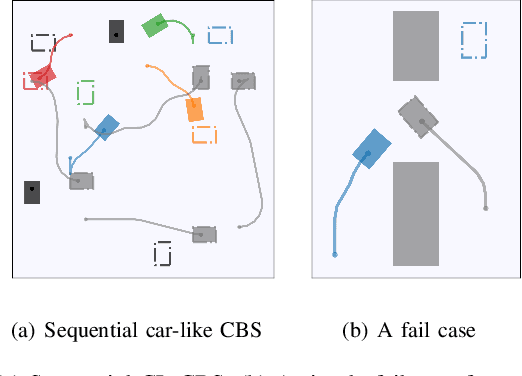
Multi-Agent Path Finding has been widely studied in the past few years due to its broad application in the field of robotics and AI. However, previous solvers rely on several simplifying assumptions. They limit their applicability in numerous real-world domains that adopt nonholonomic car-like agents rather than holonomic ones. In this paper, we give a mathematical formalization of Multi-Agent Path Finding for Car-Like robots (CL-MAPF) problem. For the first time, we propose a novel hierarchical search-based solver called Car-like Conflict-Based Search to address this problem. It applies a body conflict tree to address collisions considering shapes of the agents. We introduce a new algorithm called Spatiotemporal Hybrid-State A* as the single-agent path planner to generate path satisfying both kinematic and spatiotemporal constraints. We also present a sequential planning version of our method for the sake of efficiency. We compare our method with two baseline algorithms on a dedicated benchmark containing 3000 instances and validate it in real-world scenarios. The experiment results give clear evidence that our algorithm scales well to a large number of agents and is able to produce solutions that can be directly applied to car-like robots in the real world. The benchmark and source code are released in https://github.com/APRIL-ZJU/CL-CBS.
Semantic Graph Based Place Recognition for 3D Point Clouds
Aug 26, 2020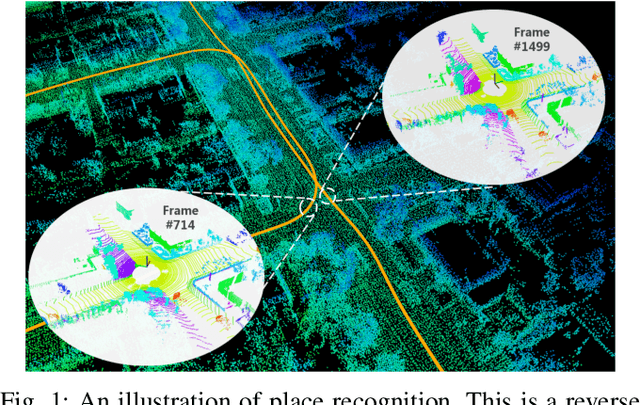
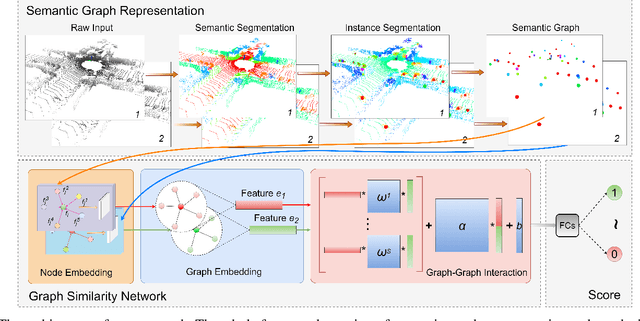
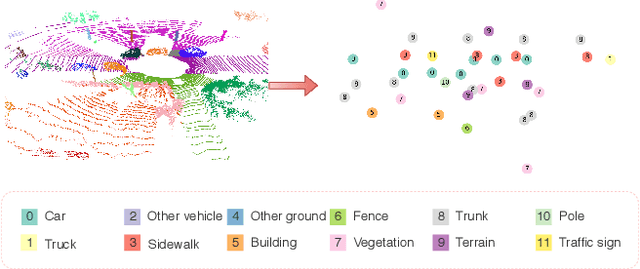
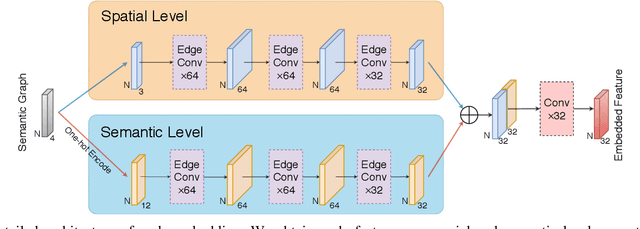
Due to the difficulty in generating the effective descriptors which are robust to occlusion and viewpoint changes, place recognition for 3D point cloud remains an open issue. Unlike most of the existing methods that focus on extracting local, global, and statistical features of raw point clouds, our method aims at the semantic level that can be superior in terms of robustness to environmental changes. Inspired by the perspective of humans, who recognize scenes through identifying semantic objects and capturing their relations, this paper presents a novel semantic graph based approach for place recognition. First, we propose a novel semantic graph representation for the point cloud scenes by reserving the semantic and topological information of the raw point cloud. Thus, place recognition is modeled as a graph matching problem. Then we design a fast and effective graph similarity network to compute the similarity. Exhaustive evaluations on the KITTI dataset show that our approach is robust to the occlusion as well as viewpoint changes and outperforms the state-of-the-art methods with a large margin. Our code is available at: \url{https://github.com/kxhit/SG_PR}.