 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Binary Neural Network
Jan 07, 2025



Binary Neural Network (BNN) converts full-precision weights and activations into their extreme 1-bit counterparts, making it particularly suitable for deployment on lightweight mobile devices. While binary neural networks are typically formulated as a constrained optimization problem and optimized in the binarized space, general neural networks are formulated as an unconstrained optimization problem and optimized in the continuous space. This paper introduces the Hyperbolic Binary Neural Network (HBNN) by leveraging the framework of hyperbolic geometry to optimize the constrained problem. Specifically, we transform the constrained problem in hyperbolic space into an unconstrained one in Euclidean space using the Riemannian exponential map. On the other hand, we also propose the Exponential Parametrization Cluster (EPC) method, which, compared to the Riemannian exponential map, shrinks the segment domain based on a diffeomorphism. This approach increases the probability of weight flips, thereby maximizing the information gain in BNNs. Experimental results on CIFAR10, CIFAR100, and ImageNet classification datasets with VGGsmall, ResNet18, and ResNet34 models illustrate the superior performance of our HBNN over state-of-the-art methods.
DFRot: Achieving Outlier-Free and Massive Activation-Free for Rotated LLMs with Refined Rotation
Dec 03, 2024



Rotating the activation and weight matrices to reduce the influence of outliers in large language models (LLMs) has recently attracted significant attention, particularly in the context of model quantization. Prior studies have shown that in low-precision quantization scenarios, such as 4-bit weights and 4-bit activations (W4A4), randomized Hadamard transforms can achieve significantly higher accuracy than randomized orthogonal transforms. Notably, the reason behind this phenomena remains unknown. In this paper, we find that these transformations show substantial improvement in eliminating outliers for common tokens and achieve similar quantization error. The primary reason for the accuracy difference lies in the fact that randomized Hadamard transforms can slightly reduce the quantization error for tokens with massive activations while randomized orthogonal transforms increase the quantization error. Due to the extreme rarity of these tokens and their critical impact on model accuracy, we consider this a long-tail optimization problem, and therefore construct a simple yet effective method: a weighted loss function. Additionally, we propose an optimization strategy for the rotation matrix that involves alternating optimization of quantization parameters while employing orthogonal Procrustes transforms to refine the rotation matrix. This makes the distribution of the rotated activation values more conducive to quantization, especially for tokens with massive activations. Our method enhances the Rotated LLMs by achieving dual free, Outlier-Free and Massive Activation-Free, dubbed as DFRot. Extensive experiments demonstrate the effectiveness and efficiency of DFRot. By tuning the rotation matrix using just a single sample, DFRot achieves a perplexity improvement of 0.25 and 0.21 on W4A4KV4 and W4A4KV16, respectively, for LLaMA3-8B, a model known for its quantization challenges.
OvSW: Overcoming Silent Weights for Accurate Binary Neural Networks
Jul 07, 2024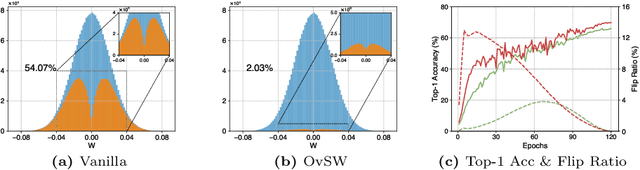

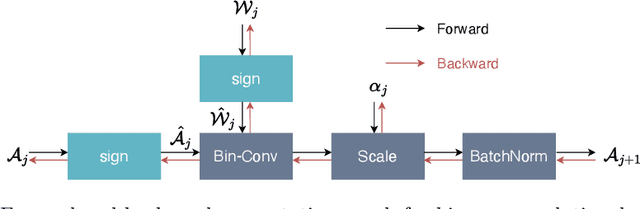

Binary Neural Networks~(BNNs) have been proven to be highly effective for deploying deep neural networks on mobile and embedded platforms. Most existing works focus on minimizing quantization errors, improving representation ability, or designing gradient approximations to alleviate gradient mismatch in BNNs, while leaving the weight sign flipping, a critical factor for achieving powerful BNNs, untouched. In this paper, we investigate the efficiency of weight sign updates in BNNs. We observe that, for vanilla BNNs, over 50\% of the weights remain their signs unchanged during training, and these weights are not only distributed at the tails of the weight distribution but also universally present in the vicinity of zero. We refer to these weights as ``silent weights'', which slow down convergence and lead to a significant accuracy degradation. Theoretically, we reveal this is due to the independence of the BNNs gradient from the latent weight distribution. To address the issue, we propose Overcome Silent Weights~(OvSW). OvSW first employs Adaptive Gradient Scaling~(AGS) to establish a relationship between the gradient and the latent weight distribution, thereby improving the overall efficiency of weight sign updates. Additionally, we design Silence Awareness Decaying~(SAD) to automatically identify ``silent weights'' by tracking weight flipping state, and apply an additional penalty to ``silent weights'' to facilitate their flipping. By efficiently updating weight signs, our method achieves faster convergence and state-of-the-art performance on CIFAR10 and ImageNet1K dataset with various architectures. For example, OvSW obtains 61.6\% and 65.5\% top-1 accuracy on the ImageNet1K using binarized ResNet18 and ResNet34 architecture respectively. Codes are available at \url{https://github.com/JingyangXiang/OvSW}.
QQQ: Quality Quattuor-Bit Quantization for Large Language Models
Jun 14, 2024



Quantization is a proven effective method for compressing large language models. Although popular techniques like W8A8 and W4A16 effectively maintain model performance, they often fail to concurrently speed up the prefill and decoding stages of inference. W4A8 is a promising strategy to accelerate both of them while usually leads to a significant performance degradation. To address these issues, we present QQQ, a Quality Quattuor-bit Quantization method with 4-bit weights and 8-bit activations. QQQ employs adaptive smoothing and Hessian-based compensation, significantly enhancing the performance of quantized models without extensive training. Furthermore, we meticulously engineer W4A8 GEMM kernels to increase inference speed. Our specialized per-channel W4A8 GEMM and per-group W4A8 GEMM achieve impressive speed increases of 3.67$\times$ and 3.29 $\times$ over FP16 GEMM. Our extensive experiments show that QQQ achieves performance on par with existing state-of-the-art LLM quantization methods while significantly accelerating inference, achieving speed boosts up to 2.24 $\times$, 2.10$\times$, and 1.25$\times$ compared to FP16, W8A8, and W4A16, respectively.
AutoDFP: Automatic Data-Free Pruning via Channel Similarity Reconstruction
Mar 13, 2024



Structured pruning methods are developed to bridge the gap between the massive scale of neural networks and the limited hardware resources. Most current structured pruning methods rely on training datasets to fine-tune the compressed model, resulting in high computational burdens and being inapplicable for scenarios with stringent requirements on privacy and security. As an alternative, some data-free methods have been proposed, however, these methods often require handcraft parameter tuning and can only achieve inflexible reconstruction. In this paper, we propose the Automatic Data-Free Pruning (AutoDFP) method that achieves automatic pruning and reconstruction without fine-tuning. Our approach is based on the assumption that the loss of information can be partially compensated by retaining focused information from similar channels. Specifically, We formulate data-free pruning as an optimization problem, which can be effectively addressed through reinforcement learning. AutoDFP assesses the similarity of channels for each layer and provides this information to the reinforcement learning agent, guiding the pruning and reconstruction process of the network. We evaluate AutoDFP with multiple networks on multiple datasets, achieving impressive compression results. For instance, on the CIFAR-10 dataset, AutoDFP demonstrates a 2.87\% reduction in accuracy loss compared to the recently proposed data-free pruning method DFPC with fewer FLOPs on VGG-16. Furthermore, on the ImageNet dataset, AutoDFP achieves 43.17\% higher accuracy than the SOTA method with the same 80\% preserved ratio on MobileNet-V1.
CR-SFP: Learning Consistent Representation for Soft Filter Pruning
Dec 17, 2023Soft filter pruning~(SFP) has emerged as an effective pruning technique for allowing pruned filters to update and the opportunity for them to regrow to the network. However, this pruning strategy applies training and pruning in an alternative manner, which inevitably causes inconsistent representations between the reconstructed network~(R-NN) at the training and the pruned network~(P-NN) at the inference, resulting in performance degradation. In this paper, we propose to mitigate this gap by learning consistent representation for soft filter pruning, dubbed as CR-SFP. Specifically, for each training step, CR-SFP optimizes the R-NN and P-NN simultaneously with different distorted versions of the same training data, while forcing them to be consistent by minimizing their posterior distribution via the bidirectional KL-divergence loss. Meanwhile, the R-NN and P-NN share backbone parameters thus only additional classifier parameters are introduced. After training, we can export the P-NN for inference. CR-SFP is a simple yet effective training framework to improve the accuracy of P-NN without introducing any additional inference cost. It can also be combined with a variety of pruning criteria and loss functions. Extensive experiments demonstrate our CR-SFP achieves consistent improvements across various CNN architectures. Notably, on ImageNet, our CR-SFP reduces more than 41.8\% FLOPs on ResNet18 with 69.2\% top-1 accuracy, improving SFP by 2.1\% under the same training settings. The code will be publicly available on GitHub.
MaxQ: Multi-Axis Query for N:M Sparsity Network
Dec 12, 2023N:M sparsity has received increasing attention due to its remarkable performance and latency trade-off compared with structured and unstructured sparsity. However, existing N:M sparsity methods do not differentiate the relative importance of weights among blocks and leave important weights underappreciated. Besides, they directly apply N:M sparsity to the whole network, which will cause severe information loss. Thus, they are still sub-optimal. In this paper, we propose an efficient and effective Multi-Axis Query methodology, dubbed as MaxQ, to rectify these problems. During the training, MaxQ employs a dynamic approach to generate soft N:M masks, considering the weight importance across multiple axes. This method enhances the weights with more importance and ensures more effective updates. Meanwhile, a sparsity strategy that gradually increases the percentage of N:M weight blocks is applied, which allows the network to heal from the pruning-induced damage progressively. During the runtime, the N:M soft masks can be precomputed as constants and folded into weights without causing any distortion to the sparse pattern and incurring additional computational overhead. Comprehensive experiments demonstrate that MaxQ achieves consistent improvements across diverse CNN architectures in various computer vision tasks, including image classification, object detection and instance segmentation. For ResNet50 with 1:16 sparse pattern, MaxQ can achieve 74.6\% top-1 accuracy on ImageNet and improve by over 2.8\% over the state-of-the-art.
SUBP: Soft Uniform Block Pruning for 1xN Sparse CNNs Multithreading Acceleration
Oct 10, 2023



The study of sparsity in Convolutional Neural Networks (CNNs) has become widespread to compress and accelerate models in environments with limited resources. By constraining N consecutive weights along the output channel to be group-wise non-zero, the recent network with 1$\times$N sparsity has received tremendous popularity for its three outstanding advantages: 1) A large amount of storage space saving by a \emph{Block Sparse Row} matrix. 2) Excellent performance at a high sparsity. 3) Significant speedups on CPUs with Advanced Vector Extensions. Recent work requires selecting and fine-tuning 1$\times$N sparse weights based on dense pre-trained weights, leading to the problems such as expensive training cost and memory access, sub-optimal model quality, as well as unbalanced workload across threads (different sparsity across output channels). To overcome them, this paper proposes a novel \emph{\textbf{S}oft \textbf{U}niform \textbf{B}lock \textbf{P}runing} (SUBP) approach to train a uniform 1$\times$N sparse structured network from scratch. Specifically, our approach tends to repeatedly allow pruned blocks to regrow to the network based on block angular redundancy and importance sampling in a uniform manner throughout the training process. It not only makes the model less dependent on pre-training, reduces the model redundancy and the risk of pruning the important blocks permanently but also achieves balanced workload. Empirically, on ImageNet, comprehensive experiments across various CNN architectures show that our SUBP consistently outperforms existing 1$\times$N and structured sparsity methods based on pre-trained models or training from scratch. Source codes and models are available at \url{https://github.com/JingyangXiang/SUBP}.
RGP: Neural Network Pruning through Its Regular Graph Structure
Nov 18, 2021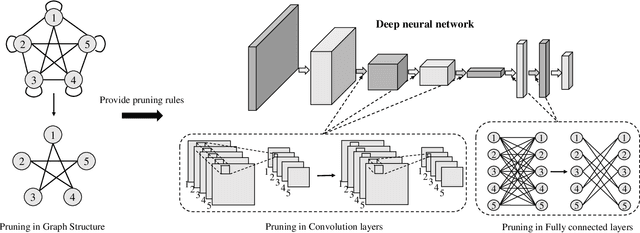
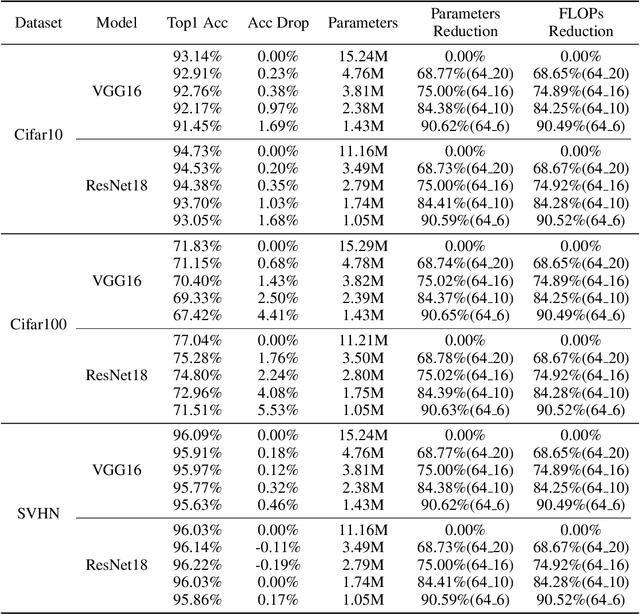
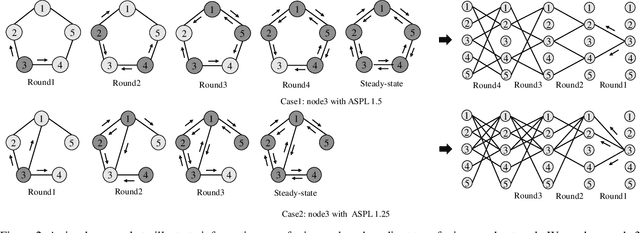
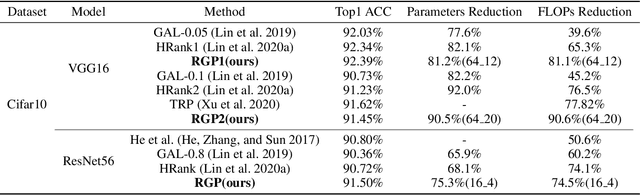
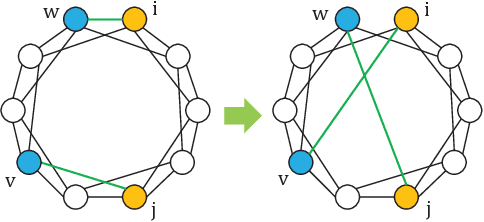
Lightweight model design has become an important direction in the application of deep learning technology, pruning is an effective mean to achieve a large reduction in model parameters and FLOPs. The existing neural network pruning methods mostly start from the importance of parameters, and design parameter evaluation metrics to perform parameter pruning iteratively. These methods are not studied from the perspective of model topology, may be effective but not efficient, and requires completely different pruning for different datasets. In this paper, we study the graph structure of the neural network, and propose regular graph based pruning (RGP) to perform a one-shot neural network pruning. We generate a regular graph, set the node degree value of the graph to meet the pruning ratio, and reduce the average shortest path length of the graph by swapping the edges to obtain the optimal edge distribution. Finally, the obtained graph is mapped into a neural network structure to realize pruning. Experiments show that the average shortest path length of the graph is negatively correlated with the classification accuracy of the corresponding neural network, and the proposed RGP shows a strong precision retention capability with extremely high parameter reduction (more than 90%) and FLOPs reduction (more than 90%).
GGT: Graph-Guided Testing for Adversarial Sample Detection of Deep Neural Network
Jul 09, 2021
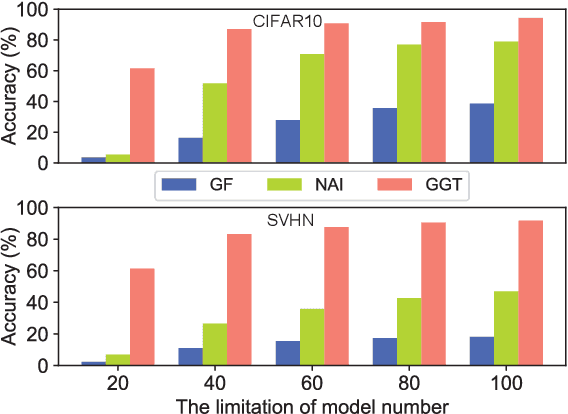
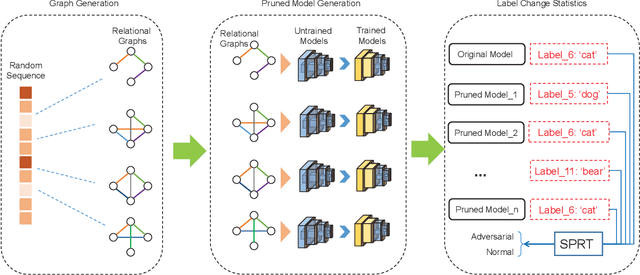
Deep Neural Networks (DNN) are known to be vulnerable to adversarial samples, the detection of which is crucial for the wide application of these DNN models. Recently, a number of deep testing methods in software engineering were proposed to find the vulnerability of DNN systems, and one of them, i.e., Model Mutation Testing (MMT), was used to successfully detect various adversarial samples generated by different kinds of adversarial attacks. However, the mutated models in MMT are always huge in number (e.g., over 100 models) and lack diversity (e.g., can be easily circumvented by high-confidence adversarial samples), which makes it less efficient in real applications and less effective in detecting high-confidence adversarial samples. In this study, we propose Graph-Guided Testing (GGT) for adversarial sample detection to overcome these aforementioned challenges. GGT generates pruned models with the guide of graph characteristics, each of them has only about 5% parameters of the mutated model in MMT, and graph guided models have higher diversity. The experiments on CIFAR10 and SVHN validate that GGT performs much better than MMT with respect to both effectiveness and efficiency.