 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUSE: A Data Expansion Framework for Low-resource Automatic Modulation Recognition based on Active Learning
Jul 16, 2025Although deep neural networks have made remarkable achievements in the field of automatic modulation recognition (AMR), these models often require a large amount of labeled data for training. However, in many practical scenarios, the available target domain data is scarce and difficult to meet the needs of model training. The most direct way is to collect data manually and perform expert annotation, but the high time and labor costs are unbearable. Another common method is data augmentation. Although it can enrich training samples to a certain extent, it does not introduce new data and therefore cannot fundamentally solve the problem of data scarcity. To address these challenges, we introduce a data expansion framework called Dynamic Uncertainty-driven Sample Expansion (DUSE). Specifically, DUSE uses an uncertainty scoring function to filter out useful samples from relevant AMR datasets and employs an active learning strategy to continuously refine the scorer. Extensive experiments demonstrate that DUSE consistently outperforms 8 coreset selection baselines in both class-balance and class-imbalance settings. Besides, DUSE exhibits strong cross-architecture generalization for unseen models.
FCOS: A Two-Stage Recoverable Model Pruning Framework for Automatic Modulation Recognition
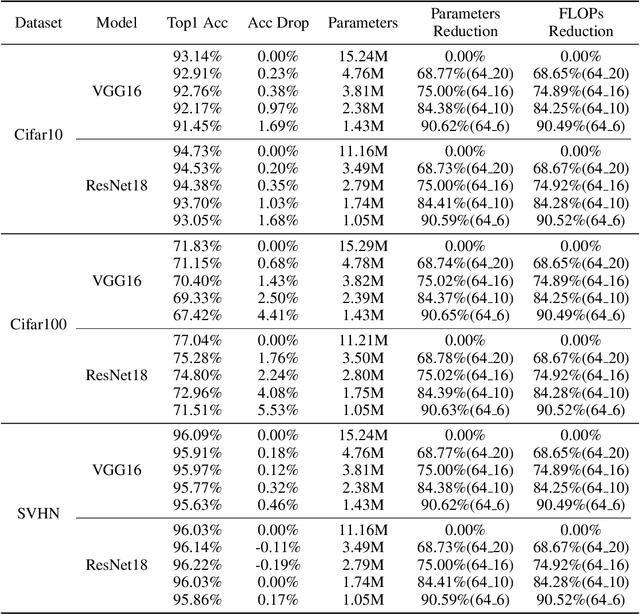
May 27, 2025With the rapid development of wireless communications and the growing complexity of digital modulation schemes, traditional manual modulation recognition methods struggle to extract reliable signal features and meet real-time requirements in modern scenarios. Recently, deep learning based Automatic Modulation Recognition (AMR) approaches have greatly improved classification accuracy. However, their large model sizes and high computational demands hinder deployment on resource-constrained devices. Model pruning provides a general approach to reduce model complexity, but existing weight, channel, and layer pruning techniques each present a trade-off between compression rate, hardware acceleration, and accuracy preservation. To this end, in this paper, we introduce FCOS, a novel Fine-to-COarse two-Stage pruning framework that combines channel-level pruning with layer-level collapse diagnosis to achieve extreme compression, high performance and efficient inference. In the first stage of FCOS, hierarchical clustering and parameter fusion are applied to channel weights to achieve channel-level pruning. Then a Layer Collapse Diagnosis (LaCD) module uses linear probing to identify layer collapse and removes the collapsed layers due to high channel compression ratio. Experiments on multiple AMR benchmarks demonstrate that FCOS outperforms existing channel and layer pruning methods. Specifically, FCOS achieves 95.51% FLOPs reduction and 95.31% parameter reduction while still maintaining performance close to the original ResNet56, with only a 0.46% drop in accuracy on Sig2019-12. Code is available at https://github.com/yaolu-zjut/FCOS.
CR-SFP: Learning Consistent Representation for Soft Filter Pruning
Dec 17, 2023Soft filter pruning~(SFP) has emerged as an effective pruning technique for allowing pruned filters to update and the opportunity for them to regrow to the network. However, this pruning strategy applies training and pruning in an alternative manner, which inevitably causes inconsistent representations between the reconstructed network~(R-NN) at the training and the pruned network~(P-NN) at the inference, resulting in performance degradation. In this paper, we propose to mitigate this gap by learning consistent representation for soft filter pruning, dubbed as CR-SFP. Specifically, for each training step, CR-SFP optimizes the R-NN and P-NN simultaneously with different distorted versions of the same training data, while forcing them to be consistent by minimizing their posterior distribution via the bidirectional KL-divergence loss. Meanwhile, the R-NN and P-NN share backbone parameters thus only additional classifier parameters are introduced. After training, we can export the P-NN for inference. CR-SFP is a simple yet effective training framework to improve the accuracy of P-NN without introducing any additional inference cost. It can also be combined with a variety of pruning criteria and loss functions. Extensive experiments demonstrate our CR-SFP achieves consistent improvements across various CNN architectures. Notably, on ImageNet, our CR-SFP reduces more than 41.8\% FLOPs on ResNet18 with 69.2\% top-1 accuracy, improving SFP by 2.1\% under the same training settings. The code will be publicly available on GitHub.
MaxQ: Multi-Axis Query for N:M Sparsity Network
Dec 12, 2023N:M sparsity has received increasing attention due to its remarkable performance and latency trade-off compared with structured and unstructured sparsity. However, existing N:M sparsity methods do not differentiate the relative importance of weights among blocks and leave important weights underappreciated. Besides, they directly apply N:M sparsity to the whole network, which will cause severe information loss. Thus, they are still sub-optimal. In this paper, we propose an efficient and effective Multi-Axis Query methodology, dubbed as MaxQ, to rectify these problems. During the training, MaxQ employs a dynamic approach to generate soft N:M masks, considering the weight importance across multiple axes. This method enhances the weights with more importance and ensures more effective updates. Meanwhile, a sparsity strategy that gradually increases the percentage of N:M weight blocks is applied, which allows the network to heal from the pruning-induced damage progressively. During the runtime, the N:M soft masks can be precomputed as constants and folded into weights without causing any distortion to the sparse pattern and incurring additional computational overhead. Comprehensive experiments demonstrate that MaxQ achieves consistent improvements across diverse CNN architectures in various computer vision tasks, including image classification, object detection and instance segmentation. For ResNet50 with 1:16 sparse pattern, MaxQ can achieve 74.6\% top-1 accuracy on ImageNet and improve by over 2.8\% over the state-of-the-art.
Mixing Signals: Data Augmentation Approach for Deep Learning Based Modulation Recognition
Apr 05, 2022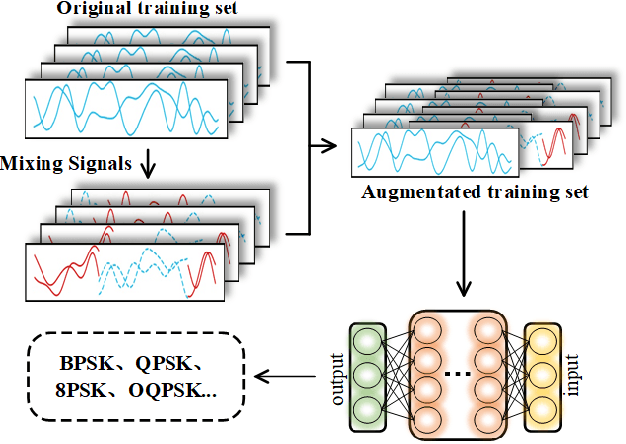
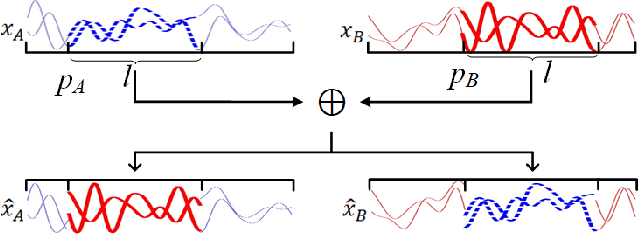
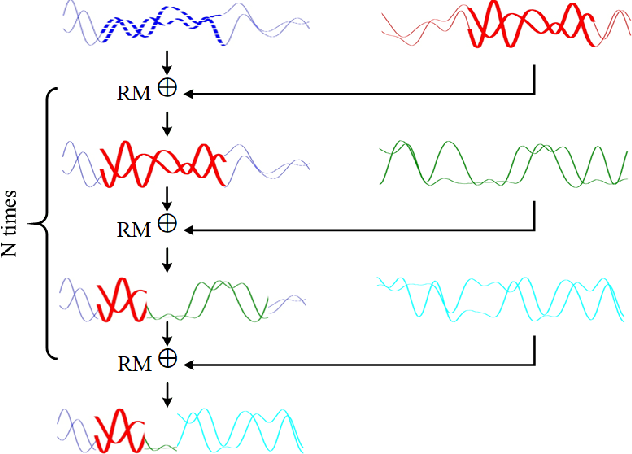

With the rapid development of deep learning, automatic modulation recognition (AMR), as an important task in cognitive radio, has gradually transformed from traditional feature extraction and classification to automatic classification by deep learning technology. However, deep learning models are data-driven methods, which often require a large amount of data as the training support. Data augmentation, as the strategy of expanding dataset, can improve the generalization of the deep learning models and thus improve the accuracy of the models to a certain extent. In this paper, for AMR of radio signals, we propose a data augmentation strategy based on mixing signals and consider four specific methods (Random Mixing, Maximum-Similarity-Mixing, $\theta-$Similarity Mixing and n-times Random Mixing) to achieve data augmentation. Experiments show that our proposed method can improve the classification accuracy of deep learning based AMR models in the full public dataset RML2016.10a. In particular, for the case of a single signal-to-noise ratio signal set, the classification accuracy can be significantly improved, which verifies the effectiveness of the methods.
Graph Modularity: Towards Understanding the Cross-Layer Transition of Feature Representations in Deep Neural Networks
Nov 24, 2021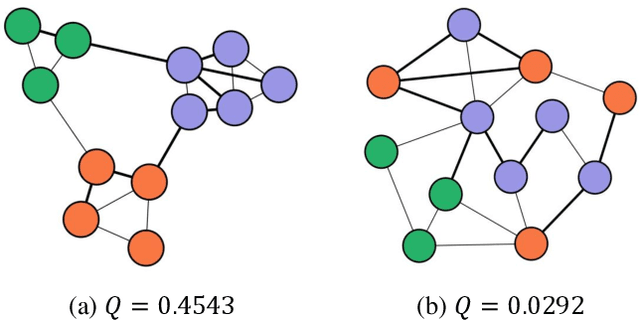
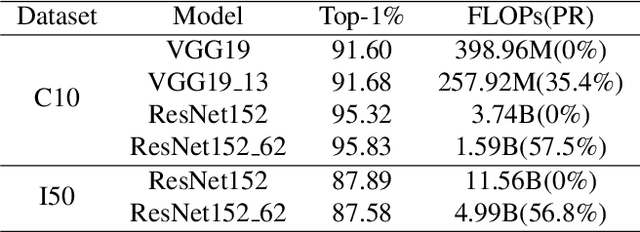
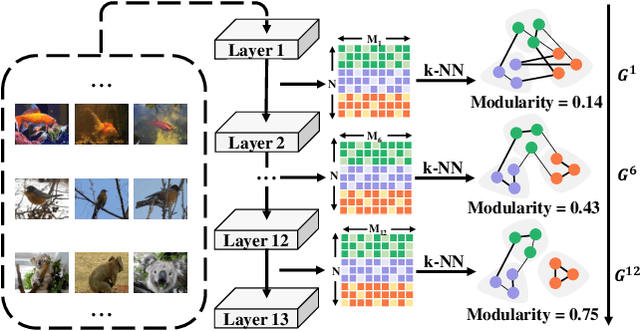
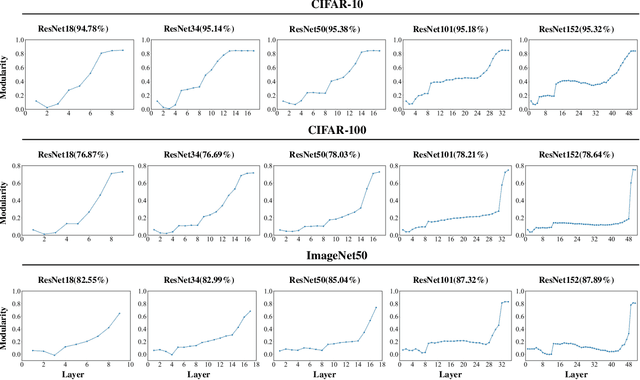
There are good arguments to support the claim that feature representations eventually transition from general to specific in deep neural networks (DNNs), but this transition remains relatively underexplored. In this work, we move a tiny step towards understanding the transition of feature representations. We first characterize this transition by analyzing the class separation in intermediate layers, and next model the process of class separation as community evolution in dynamic graphs. Then, we introduce modularity, a common metric in graph theory, to quantify the evolution of communities. We find that modularity tends to rise as the layer goes deeper, but descends or reaches a plateau at particular layers. Through an asymptotic analysis, we show that modularity can provide quantitative analysis of the transition of the feature representations. With the insight on feature representations, we demonstrate that modularity can also be used to identify and locate redundant layers in DNNs, which provides theoretical guidance for layer pruning. Based on this inspiring finding, we propose a layer-wise pruning method based on modularity. Further experiments show that our method can prune redundant layers with minimal impact on performance. The codes are available at https://github.com/yaolu-zjut/Dynamic-Graphs-Construction.
RGP: Neural Network Pruning through Its Regular Graph Structure
Nov 18, 2021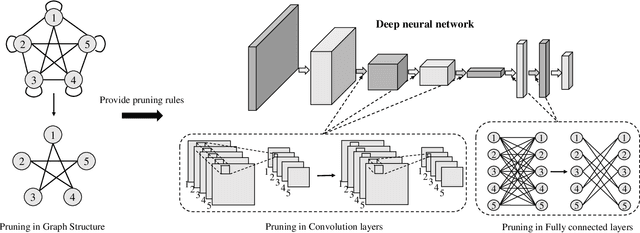
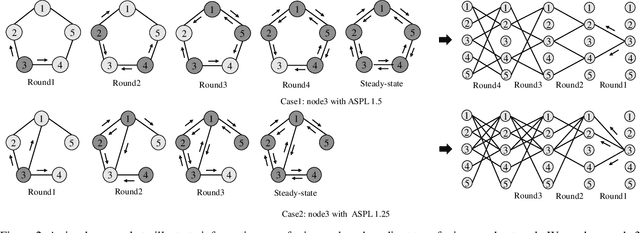
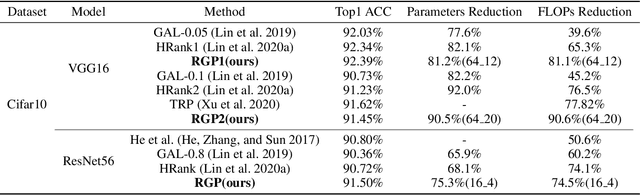
Lightweight model design has become an important direction in the application of deep learning technology, pruning is an effective mean to achieve a large reduction in model parameters and FLOPs. The existing neural network pruning methods mostly start from the importance of parameters, and design parameter evaluation metrics to perform parameter pruning iteratively. These methods are not studied from the perspective of model topology, may be effective but not efficient, and requires completely different pruning for different datasets. In this paper, we study the graph structure of the neural network, and propose regular graph based pruning (RGP) to perform a one-shot neural network pruning. We generate a regular graph, set the node degree value of the graph to meet the pruning ratio, and reduce the average shortest path length of the graph by swapping the edges to obtain the optimal edge distribution. Finally, the obtained graph is mapped into a neural network structure to realize pruning. Experiments show that the average shortest path length of the graph is negatively correlated with the classification accuracy of the corresponding neural network, and the proposed RGP shows a strong precision retention capability with extremely high parameter reduction (more than 90%) and FLOPs reduction (more than 90%).
Deep Transfer Clustering of Radio Signals
Jul 26, 2021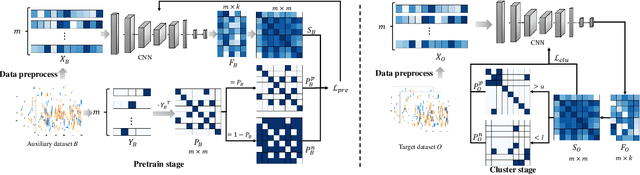
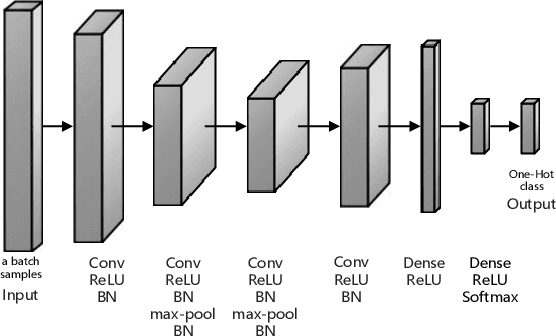

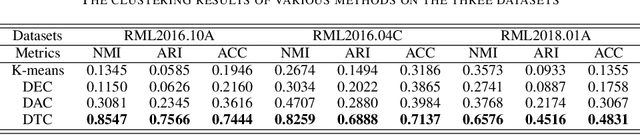
Modulation recognition is an important task in radio signal processing. Most of the current researches focus on supervised learning. However, in many real scenarios, it is difficult and cost to obtain the labels of signals. In this letter, we turn to the more challenging problem: can we cluster the modulation types just based on a large number of unlabeled radio signals? If this problem can be solved, we then can also recognize modulation types by manually labeling a very small number of samples. To answer this problem, we propose a deep transfer clustering (DTC) model. DTC naturally integrates feature learning and deep clustering, and further adopts a transfer learning mechanism to improve the feature extraction ability of an embedded convolutional neural network (CNN) model. The experiments validate that our DTC significantly outperforms a number of baselines, achieving the state-of-the-art performance in clustering radio signals for modulation recognition.
Adaptive Visibility Graph Neural Network and its Application in Modulation Classification
Jun 16, 2021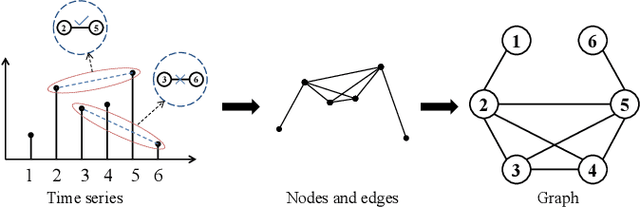
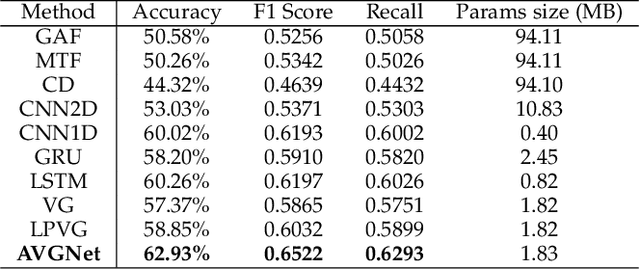
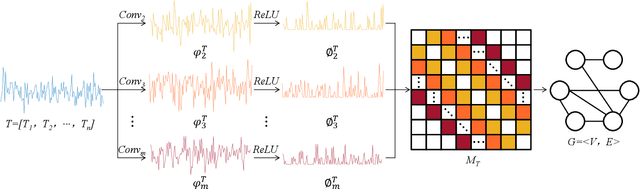
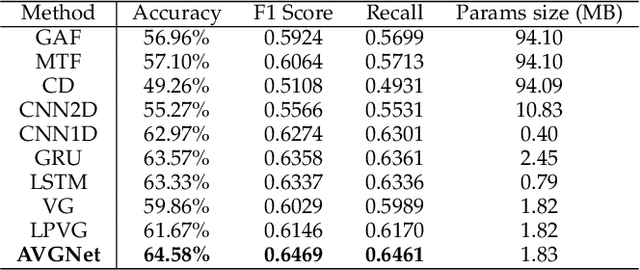
Our digital world is full of time series and graphs which capture the various aspects of many complex systems. Traditionally, there are respective methods in processing these two different types of data, e.g., Recurrent Neural Network (RNN) and Graph Neural Network (GNN), while in recent years, time series could be mapped to graphs by using the techniques such as Visibility Graph (VG), so that researchers can use graph algorithms to mine the knowledge in time series. Such mapping methods establish a bridge between time series and graphs, and have high potential to facilitate the analysis of various real-world time series. However, the VG method and its variants are just based on fixed rules and thus lack of flexibility, largely limiting their application in reality. In this paper, we propose an Adaptive Visibility Graph (AVG) algorithm that can adaptively map time series into graphs, based on which we further establish an end-to-end classification framework AVGNet, by utilizing GNN model DiffPool as the classifier. We then adopt AVGNet for radio signal modulation classification which is an important task in the field of wireless communication. The simulations validate that AVGNet outperforms a series of advanced deep learning methods, achieving the state-of-the-art performance in this task.
HVAQ: A High-Resolution Vision-Based Air Quality Dataset
Feb 18, 2021



Air pollutants, such as particulate matter, strongly impact human health. Most existing pollution monitoring techniques use stationary sensors, which are typically sparsely deployed. However, real-world pollution distributions vary rapidly in space and the visual effects of air pollutant can be used to estimate concentration, potentially at high spatial resolution. Accurate pollution monitoring requires either densely deployed conventional point sensors, at-a-distance vision-based pollution monitoring, or a combination of both. This paper makes the following contributions: (1) we present a high temporal and spatial resolution air quality dataset consisting of PM2.5, PM10, temperature, and humidity data; (2) we simultaneously take images covering the locations of the particle counters; and (3) we evaluate several vision-based state-of-art PM concentration prediction algorithms on our dataset and demonstrate that prediction accuracy increases with sensor density and image. It is our intent and belief that this dataset can enable advances by other research teams working on air quality estimation.