 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperspectral Imaging for cherry tomato
Mar 10, 2022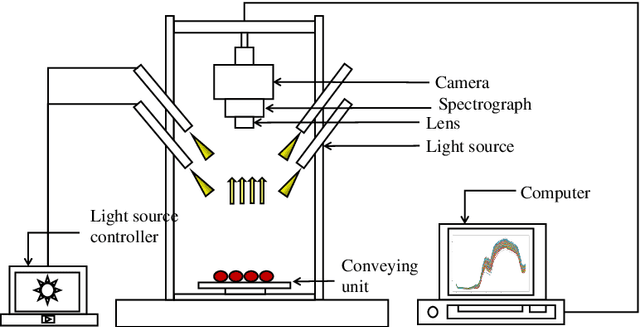
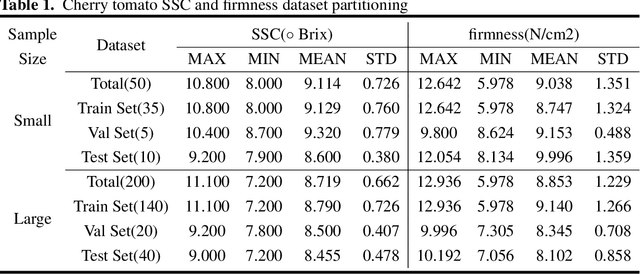
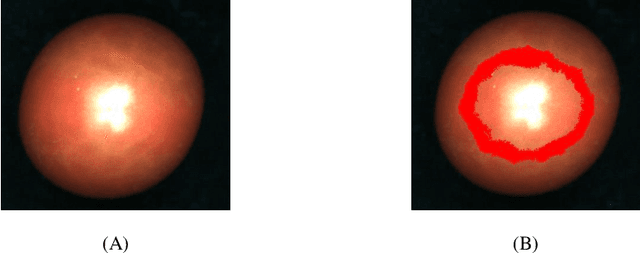
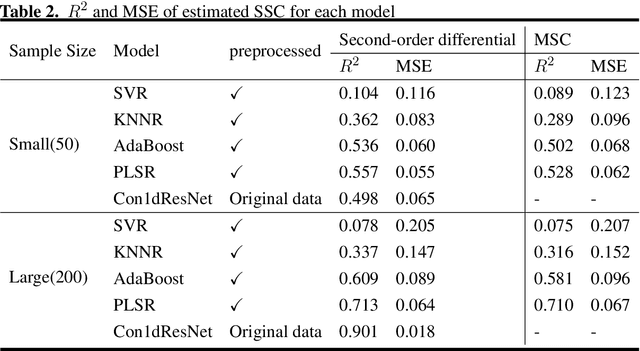
Cherry tomato (Solanum Lycopersicum) is popular with consumers over the world due to its special flavor. Soluble solids content (SSC) and firmness are two key metrics for evaluating the product qualities. In this work, we develop non-destructive testing techniques for SSC and fruit firmness based on hyperspectral images and a corresponding deep learning regression model. Hyperspectral reflectance images of over 200 tomato fruits are derived with spectrum ranging from 400 to 1000 nm. The acquired hyperspectral images are corrected and the spectral information is extracted. A novel one-dimensional(1D) convolutional ResNet (Con1dResNet) based regression model is prosed and compared with the state of art techniques. Experimental results show that, with a relatively large number of samples our technique is 26.4\% better than state of art technique for SSC and 33.7\% for firmness. The results of this study indicate the application potential of hyperspectral imaging technique in the SSC and firmness detection, which provides a new option for non-destructive testing of cherry tomato fruit quality in the future.
Graphfool: Targeted Label Adversarial Attack on Graph Embedding
Feb 24, 2021
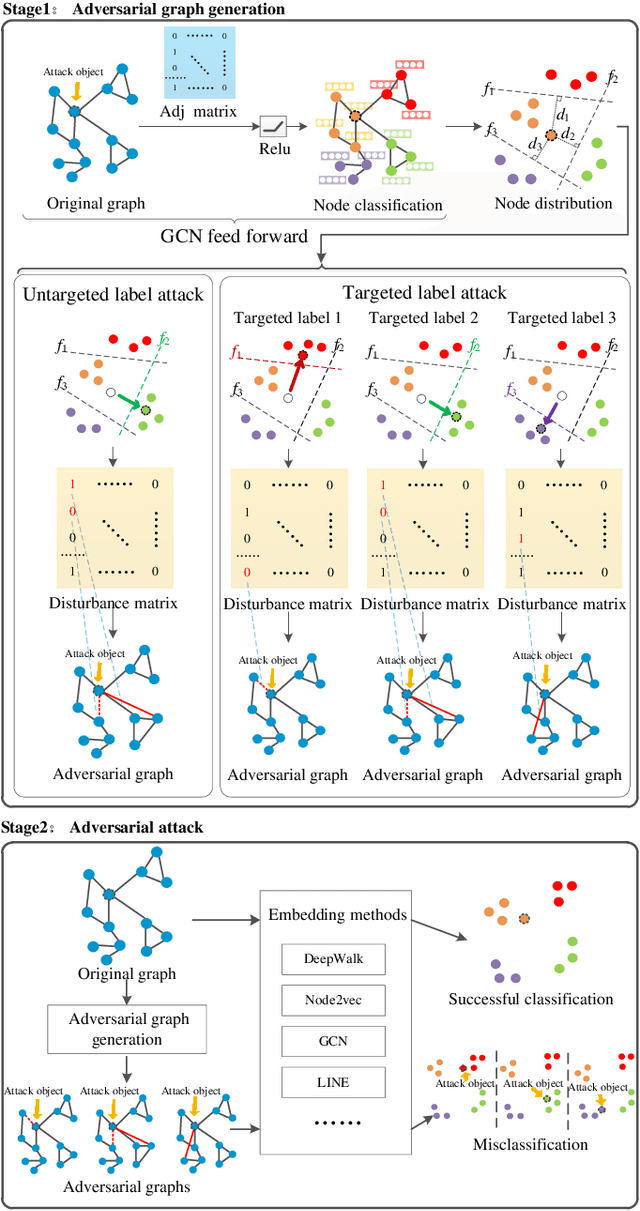
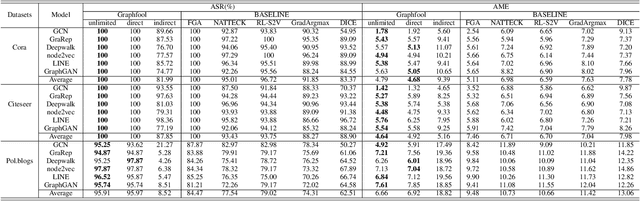
Deep learning is effective in graph analysis. It is widely applied in many related areas, such as link prediction, node classification, community detection, and graph classification etc. Graph embedding, which learns low-dimensional representations for vertices or edges in the graph, usually employs deep models to derive the embedding vector. However, these models are vulnerable. We envision that graph embedding methods based on deep models can be easily attacked using adversarial examples. Thus, in this paper, we propose Graphfool, a novel targeted label adversarial attack on graph embedding. It can generate adversarial graph to attack graph embedding methods via classifying boundary and gradient information in graph convolutional network (GCN). Specifically, we perform the following steps: 1),We first estimate the classification boundaries of different classes. 2), We calculate the minimal perturbation matrix to misclassify the attacked vertex according to the target classification boundary. 3), We modify the adjacency matrix according to the maximal absolute value of the disturbance matrix. This process is implemented iteratively. To the best of our knowledge, this is the first targeted label attack technique. The experiments on real-world graph networks demonstrate that Graphfool can derive better performance than state-of-art techniques. Compared with the second best algorithm, Graphfool can achieve an average improvement of 11.44% in attack success rate.
HVAQ: A High-Resolution Vision-Based Air Quality Dataset
Feb 18, 2021



Air pollutants, such as particulate matter, strongly impact human health. Most existing pollution monitoring techniques use stationary sensors, which are typically sparsely deployed. However, real-world pollution distributions vary rapidly in space and the visual effects of air pollutant can be used to estimate concentration, potentially at high spatial resolution. Accurate pollution monitoring requires either densely deployed conventional point sensors, at-a-distance vision-based pollution monitoring, or a combination of both. This paper makes the following contributions: (1) we present a high temporal and spatial resolution air quality dataset consisting of PM2.5, PM10, temperature, and humidity data; (2) we simultaneously take images covering the locations of the particle counters; and (3) we evaluate several vision-based state-of-art PM concentration prediction algorithms on our dataset and demonstrate that prediction accuracy increases with sensor density and image. It is our intent and belief that this dataset can enable advances by other research teams working on air quality estimation.
MITNet: GAN Enhanced Magnetic Induction Tomography Based on Complex CNN
Feb 16, 2021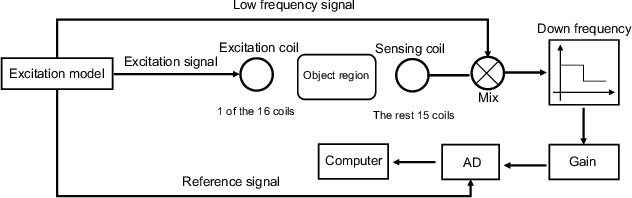
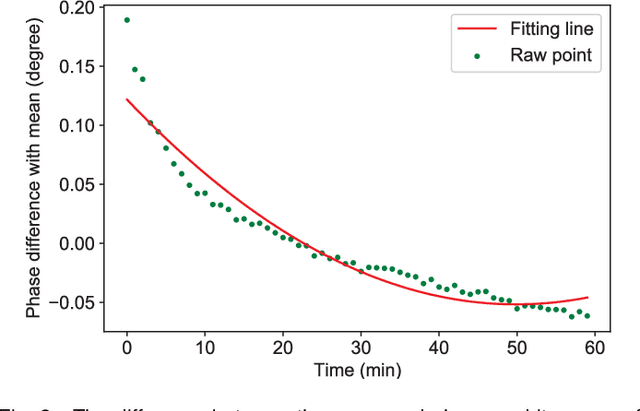
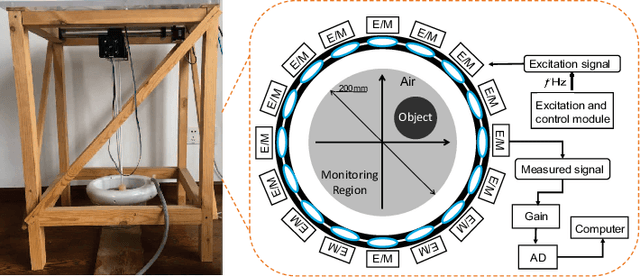
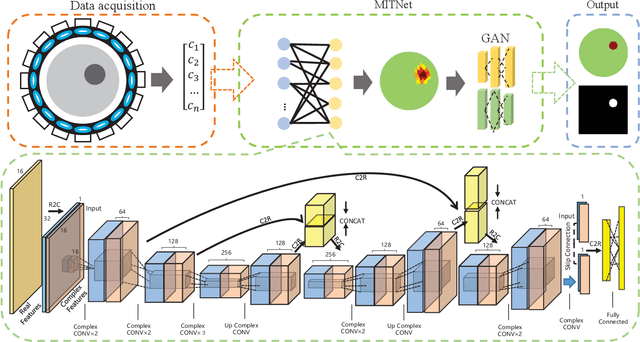
Magnetic induction tomography (MIT) is an efficient solution for long-term brain disease monitoring, which focuses on reconstructing bio-impedance distribution inside the human brain using non-intrusive electromagnetic fields. However, high-quality brain image reconstruction remains challenging since reconstructing images from the measured weak signals is a highly non-linear and ill-conditioned problem. In this work, we propose a generative adversarial network (GAN) enhanced MIT technique, named MITNet, based on a complex convolutional neural network (CNN). The experimental results on the real-world dataset validate the performance of our technique, which outperforms the state-of-art method by 25.27%.
Open DNN Box by Power Side-Channel Attack
Jul 21, 2019
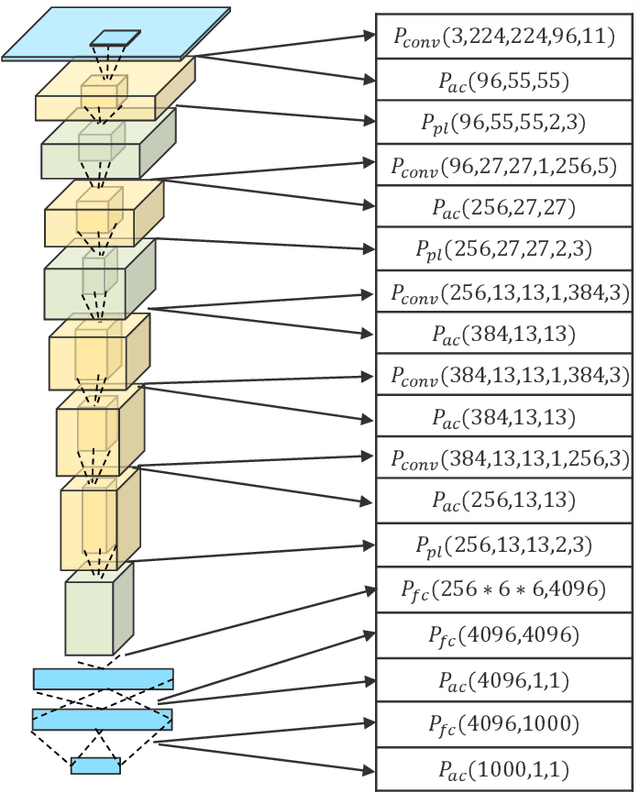
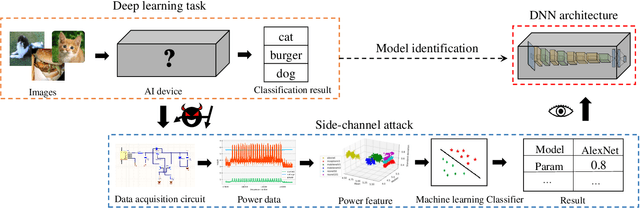
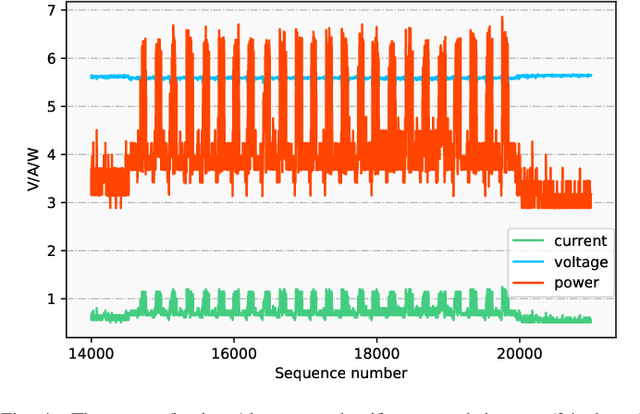
Deep neural networks are becoming popular and important assets of many AI companies. However, recent studies indicate that they are also vulnerable to adversarial attacks. Adversarial attacks can be either white-box or black-box. The white-box attacks assume full knowledge of the models while the black-box ones assume none. In general, revealing more internal information can enable much more powerful and efficient attacks. However, in most real-world applications, the internal information of embedded AI devices is unavailable, i.e., they are black-box. Therefore, in this work, we propose a side-channel information based technique to reveal the internal information of black-box models. Specifically, we have made the following contributions: (1) we are the first to use side-channel information to reveal internal network architecture in embedded devices; (2) we are the first to construct models for internal parameter estimation; and (3) we validate our methods on real-world devices and applications. The experimental results show that our method can achieve 96.50\% accuracy on average. Such results suggest that we should pay strong attention to the security problem of many AI applications, and further propose corresponding defensive strategies in the future.
MV-C3D: A Spatial Correlated Multi-View 3D Convolutional Neural Networks
Jun 15, 2019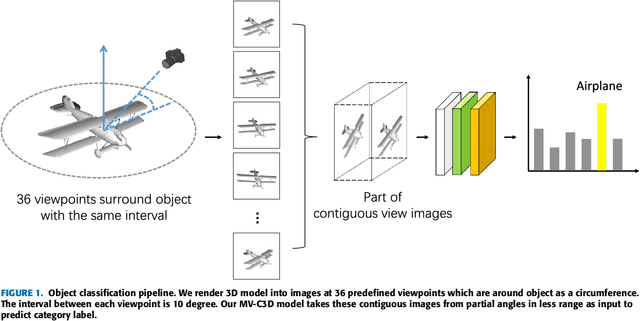
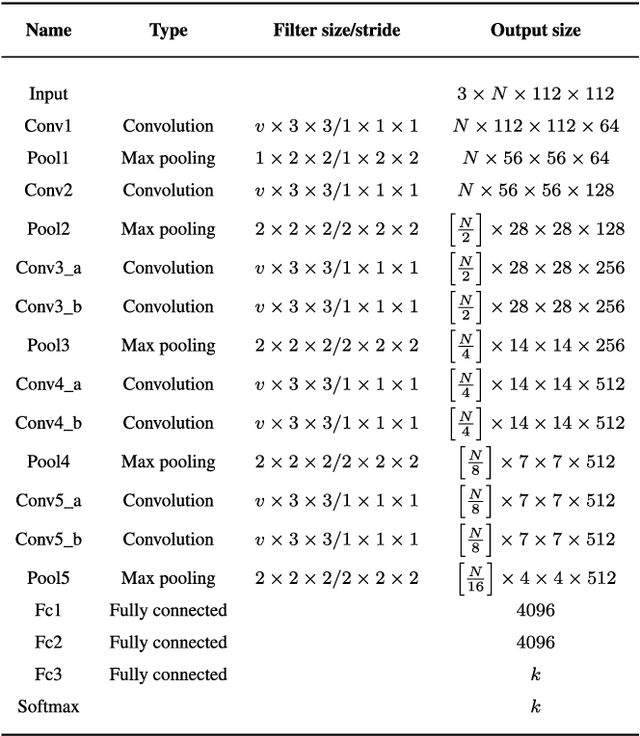
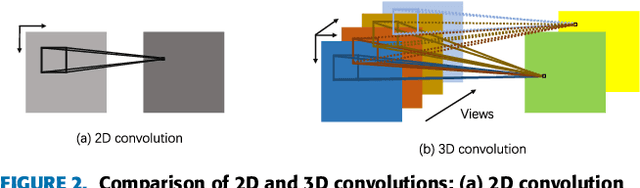
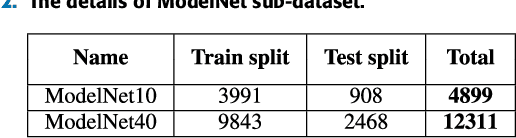
As the development of deep neural networks, 3D object recognition is becoming increasingly popular in computer vision community. Many multi-view based methods are proposed to improve the category recognition accuracy. These approaches mainly rely on multi-view images which are rendered with the whole circumference. In real-world applications, however, 3D objects are mostly observed from partial viewpoints in a less range. Therefore, we propose a multi-view based 3D convolutional neural network, which takes only part of contiguous multi-view images as input and can still maintain high accuracy. Moreover, our model takes these view images as a joint variable to better learn spatially correlated features using 3D convolution and 3D max-pooling layers. Experimental results on ModelNet10 and ModelNet40 datasets show that our MV-C3D technique can achieve outstanding performance with multi-view images which are captured from partial angles with less range. The results on 3D rotated real image dataset MIRO further demonstrate that MV-C3D is more adaptable in real-world scenarios. The classification accuracy can be further improved with the increasing number of view images.