 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Fraudster: Adversarial Attacks on Graph Neural Network Based Vertical Federated Learning
Oct 13, 2021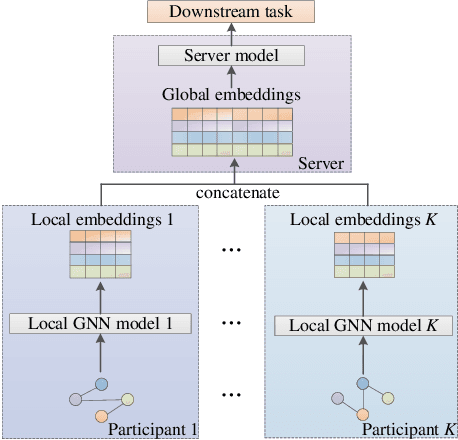
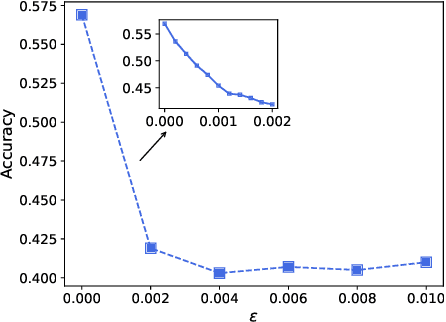
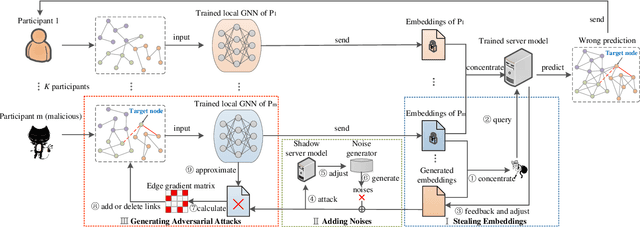
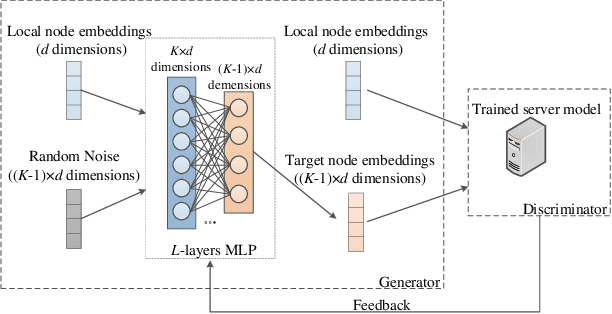
Graph neural network (GNN) models have achieved great success on graph representation learning. Challenged by large scale private data collection from user-side, GNN models may not be able to reflect the excellent performance, without rich features and complete adjacent relationships. Addressing to the problem, vertical federated learning (VFL) is proposed to implement local data protection through training a global model collaboratively. Consequently, for graph-structured data, it is natural idea to construct VFL framework with GNN models. However, GNN models are proven to be vulnerable to adversarial attacks. Whether the vulnerability will be brought into the VFL has not been studied. In this paper, we devote to study the security issues of GNN based VFL (GVFL), i.e., robustness against adversarial attacks. Further, we propose an adversarial attack method, named Graph-Fraudster. It generates adversarial perturbations based on the noise-added global node embeddings via GVFL's privacy leakage, and the gradient of pairwise node. First, it steals the global node embeddings and sets up a shadow server model for attack generator. Second, noises are added into node embeddings to confuse the shadow server model. At last, the gradient of pairwise node is used to generate attacks with the guidance of noise-added node embeddings. To the best of our knowledge, this is the first study of adversarial attacks on GVFL. The extensive experiments on five benchmark datasets demonstrate that Graph-Fraudster performs better than three possible baselines in GVFL. Furthermore, Graph-Fraudster can remain a threat to GVFL even if two possible defense mechanisms are applied. This paper reveals that GVFL is vulnerable to adversarial attack similar to centralized GNN models.
Salient Feature Extractor for Adversarial Defense on Deep Neural Networks
May 14, 2021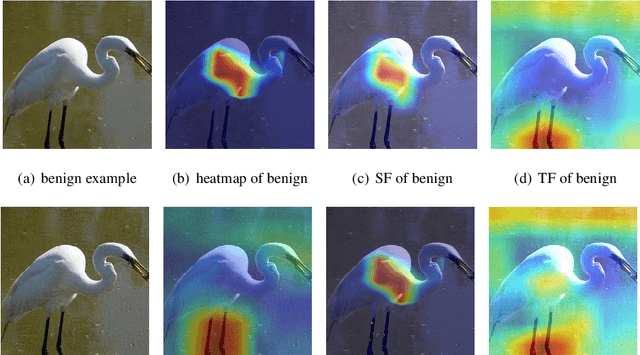

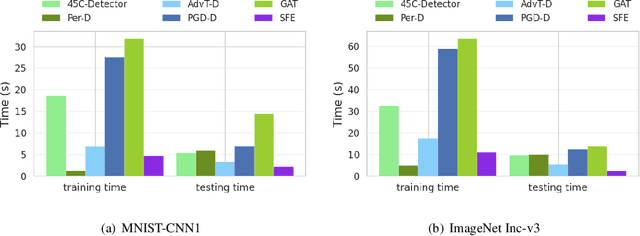
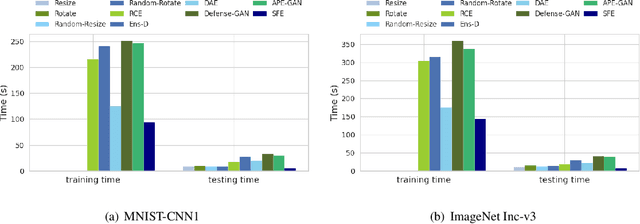
Recent years have witnessed unprecedented success achieved by deep learning models in the field of computer vision. However, their vulnerability towards carefully crafted adversarial examples has also attracted the increasing attention of researchers. Motivated by the observation that adversarial examples are due to the non-robust feature learned from the original dataset by models, we propose the concepts of salient feature(SF) and trivial feature(TF). The former represents the class-related feature, while the latter is usually adopted to mislead the model. We extract these two features with coupled generative adversarial network model and put forward a novel detection and defense method named salient feature extractor (SFE) to defend against adversarial attacks. Concretely, detection is realized by separating and comparing the difference between SF and TF of the input. At the same time, correct labels are obtained by re-identifying SF to reach the purpose of defense. Extensive experiments are carried out on MNIST, CIFAR-10, and ImageNet datasets where SFE shows state-of-the-art results in effectiveness and efficiency compared with baselines. Furthermore, we provide an interpretable understanding of the defense and detection process.
Graphfool: Targeted Label Adversarial Attack on Graph Embedding
Feb 24, 2021
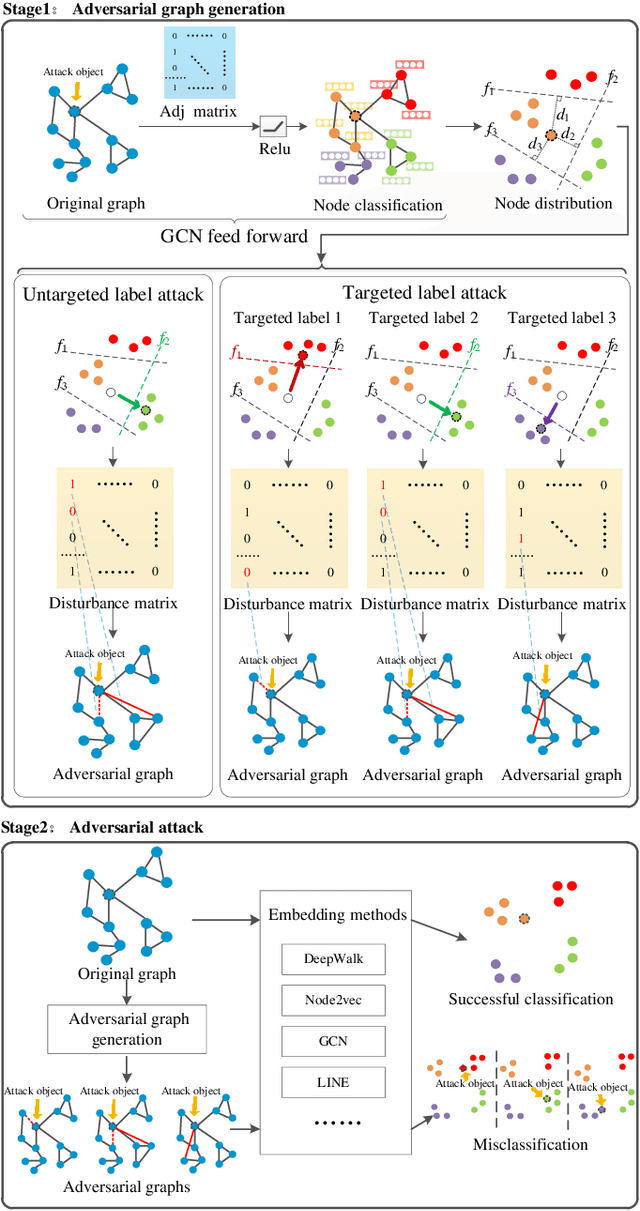
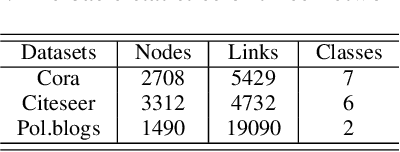
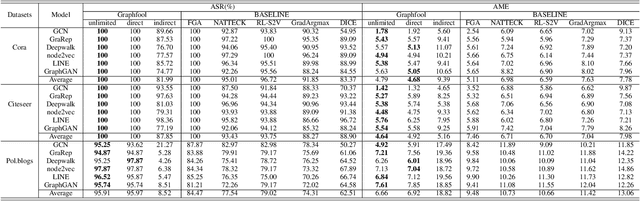
Deep learning is effective in graph analysis. It is widely applied in many related areas, such as link prediction, node classification, community detection, and graph classification etc. Graph embedding, which learns low-dimensional representations for vertices or edges in the graph, usually employs deep models to derive the embedding vector. However, these models are vulnerable. We envision that graph embedding methods based on deep models can be easily attacked using adversarial examples. Thus, in this paper, we propose Graphfool, a novel targeted label adversarial attack on graph embedding. It can generate adversarial graph to attack graph embedding methods via classifying boundary and gradient information in graph convolutional network (GCN). Specifically, we perform the following steps: 1),We first estimate the classification boundaries of different classes. 2), We calculate the minimal perturbation matrix to misclassify the attacked vertex according to the target classification boundary. 3), We modify the adjacency matrix according to the maximal absolute value of the disturbance matrix. This process is implemented iteratively. To the best of our knowledge, this is the first targeted label attack technique. The experiments on real-world graph networks demonstrate that Graphfool can derive better performance than state-of-art techniques. Compared with the second best algorithm, Graphfool can achieve an average improvement of 11.44% in attack success rate.