 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDM4Steal: Diffusion Model For Link Stealing Attack On Graph Neural Networks
Nov 05, 2024Graph has become increasingly integral to the advancement of recommendation systems, particularly with the fast development of graph neural network(GNN). By exploring the virtue of rich node features and link information, GNN is designed to provide personalized and accurate suggestions. Meanwhile, the privacy leakage of GNN in such contexts has also captured special attention. Prior work has revealed that a malicious user can utilize auxiliary knowledge to extract sensitive link data of the target graph, integral to recommendation systems, via the decision made by the target GNN model. This poses a significant risk to the integrity and confidentiality of data used in recommendation system. Though important, previous works on GNN's privacy leakage are still challenged in three aspects, i.e., limited stealing attack scenarios, sub-optimal attack performance, and adaptation against defense. To address these issues, we propose a diffusion model based link stealing attack, named DM4Steal. It differs previous work from three critical aspects. (i) Generality: aiming at six attack scenarios with limited auxiliary knowledge, we propose a novel training strategy for diffusion models so that DM4Steal is transferable to diverse attack scenarios. (ii) Effectiveness: benefiting from the retention of semantic structure in the diffusion model during the training process, DM4Steal is capable to learn the precise topology of the target graph through the GNN decision process. (iii) Adaptation: when GNN is defensive (e.g., DP, Dropout), DM4Steal relies on the stability that comes from sampling the score model multiple times to keep performance degradation to a minimum, thus DM4Steal implements successful adaptive attack on defensive GNN.
Query-Efficient Adversarial Attack Against Vertical Federated Graph Learning
Nov 05, 2024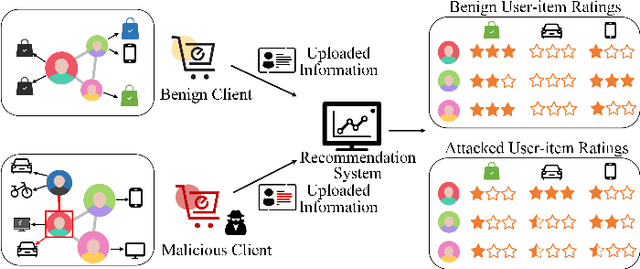
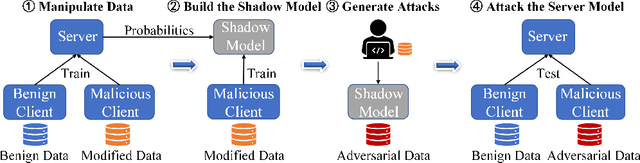
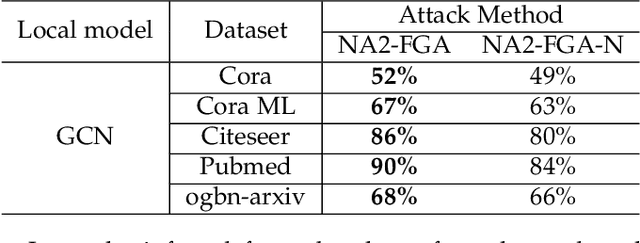
Graph neural network (GNN) has captured wide attention due to its capability of graph representation learning for graph-structured data. However, the distributed data silos limit the performance of GNN. Vertical federated learning (VFL), an emerging technique to process distributed data, successfully makes GNN possible to handle the distributed graph-structured data. Despite the prosperous development of vertical federated graph learning (VFGL), the robustness of VFGL against the adversarial attack has not been explored yet. Although numerous adversarial attacks against centralized GNNs are proposed, their attack performance is challenged in the VFGL scenario. To the best of our knowledge, this is the first work to explore the adversarial attack against VFGL. A query-efficient hybrid adversarial attack framework is proposed to significantly improve the centralized adversarial attacks against VFGL, denoted as NA2, short for Neuron-based Adversarial Attack. Specifically, a malicious client manipulates its local training data to improve its contribution in a stealthy fashion. Then a shadow model is established based on the manipulated data to simulate the behavior of the server model in VFGL. As a result, the shadow model can improve the attack success rate of various centralized attacks with a few queries. Extensive experiments on five real-world benchmarks demonstrate that NA2 improves the performance of the centralized adversarial attacks against VFGL, achieving state-of-the-art performance even under potential adaptive defense where the defender knows the attack method. Additionally, we provide interpretable experiments of the effectiveness of NA2 via sensitive neurons identification and visualization of t-SNE.
LiDAttack: Robust Black-box Attack on LiDAR-based Object Detection
Nov 04, 2024Since DNN is vulnerable to carefully crafted adversarial examples, adversarial attack on LiDAR sensors have been extensively studied. We introduce a robust black-box attack dubbed LiDAttack. It utilizes a genetic algorithm with a simulated annealing strategy to strictly limit the location and number of perturbation points, achieving a stealthy and effective attack. And it simulates scanning deviations, allowing it to adapt to dynamic changes in real world scenario variations. Extensive experiments are conducted on 3 datasets (i.e., KITTI, nuScenes, and self-constructed data) with 3 dominant object detection models (i.e., PointRCNN, PointPillar, and PV-RCNN++). The results reveal the efficiency of the LiDAttack when targeting a wide range of object detection models, with an attack success rate (ASR) up to 90%.
Robust Knowledge Distillation Based on Feature Variance Against Backdoored Teacher Model
Jun 01, 2024



Benefiting from well-trained deep neural networks (DNNs), model compression have captured special attention for computing resource limited equipment, especially edge devices. Knowledge distillation (KD) is one of the widely used compression techniques for edge deployment, by obtaining a lightweight student model from a well-trained teacher model released on public platforms. However, it has been empirically noticed that the backdoor in the teacher model will be transferred to the student model during the process of KD. Although numerous KD methods have been proposed, most of them focus on the distillation of a high-performing student model without robustness consideration. Besides, some research adopts KD techniques as effective backdoor mitigation tools, but they fail to perform model compression at the same time. Consequently, it is still an open problem to well achieve two objectives of robust KD, i.e., student model's performance and backdoor mitigation. To address these issues, we propose RobustKD, a robust knowledge distillation that compresses the model while mitigating backdoor based on feature variance. Specifically, RobustKD distinguishes the previous works in three key aspects: (1) effectiveness: by distilling the feature map of the teacher model after detoxification, the main task performance of the student model is comparable to that of the teacher model; (2) robustness: by reducing the characteristic variance between the teacher model and the student model, it mitigates the backdoor of the student model under backdoored teacher model scenario; (3) generic: RobustKD still has good performance in the face of multiple data models (e.g., WRN 28-4, Pyramid-200) and diverse DNNs (e.g., ResNet50, MobileNet).
CertPri: Certifiable Prioritization for Deep Neural Networks via Movement Cost in Feature Space
Jul 18, 2023Deep neural networks (DNNs) have demonstrated their outperformance in various software systems, but also exhibit misbehavior and even result in irreversible disasters. Therefore, it is crucial to identify the misbehavior of DNN-based software and improve DNNs' quality. Test input prioritization is one of the most appealing ways to guarantee DNNs' quality, which prioritizes test inputs so that more bug-revealing inputs can be identified earlier with limited time and manual labeling efforts. However, the existing prioritization methods are still limited from three aspects: certifiability, effectiveness, and generalizability. To overcome the challenges, we propose CertPri, a test input prioritization technique designed based on a movement cost perspective of test inputs in DNNs' feature space. CertPri differs from previous works in three key aspects: (1) certifiable: it provides a formal robustness guarantee for the movement cost; (2) effective: it leverages formally guaranteed movement costs to identify malicious bug-revealing inputs; and (3) generic: it can be applied to various tasks, data, models, and scenarios. Extensive evaluations across 2 tasks (i.e., classification and regression), 6 data forms, 4 model structures, and 2 scenarios (i.e., white-box and black-box) demonstrate CertPri's superior performance. For instance, it significantly improves 53.97% prioritization effectiveness on average compared with baselines. Its robustness and generalizability are 1.41~2.00 times and 1.33~3.39 times that of baselines on average, respectively.
AdvCheck: Characterizing Adversarial Examples via Local Gradient Checking
Mar 25, 2023Deep neural networks (DNNs) are vulnerable to adversarial examples, which may lead to catastrophe in security-critical domains. Numerous detection methods are proposed to characterize the feature uniqueness of adversarial examples, or to distinguish DNN's behavior activated by the adversarial examples. Detections based on features cannot handle adversarial examples with large perturbations. Besides, they require a large amount of specific adversarial examples. Another mainstream, model-based detections, which characterize input properties by model behaviors, suffer from heavy computation cost. To address the issues, we introduce the concept of local gradient, and reveal that adversarial examples have a quite larger bound of local gradient than the benign ones. Inspired by the observation, we leverage local gradient for detecting adversarial examples, and propose a general framework AdvCheck. Specifically, by calculating the local gradient from a few benign examples and noise-added misclassified examples to train a detector, adversarial examples and even misclassified natural inputs can be precisely distinguished from benign ones. Through extensive experiments, we have validated the AdvCheck's superior performance to the state-of-the-art (SOTA) baselines, with detection rate ($\sim \times 1.2$) on general adversarial attacks and ($\sim \times 1.4$) on misclassified natural inputs on average, with average 1/500 time cost. We also provide interpretable results for successful detection.
Edge Deep Learning Model Protection via Neuron Authorization
Mar 23, 2023With the development of deep learning processors and accelerators, deep learning models have been widely deployed on edge devices as part of the Internet of Things. Edge device models are generally considered as valuable intellectual properties that are worth for careful protection. Unfortunately, these models have a great risk of being stolen or illegally copied. The existing model protections using encryption algorithms are suffered from high computation overhead which is not practical due to the limited computing capacity on edge devices. In this work, we propose a light-weight, practical, and general Edge device model Pro tection method at neuron level, denoted as EdgePro. Specifically, we select several neurons as authorization neurons and set their activation values to locking values and scale the neuron outputs as the "asswords" during training. EdgePro protects the model by ensuring it can only work correctly when the "passwords" are met, at the cost of encrypting and storing the information of the "passwords" instead of the whole model. Extensive experimental results indicate that EdgePro can work well on the task of protecting on datasets with different modes. The inference time increase of EdgePro is only 60% of state-of-the-art methods, and the accuracy loss is less than 1%. Additionally, EdgePro is robust against adaptive attacks including fine-tuning and pruning, which makes it more practical in real-world applications. EdgePro is also open sourced to facilitate future research: https://github.com/Leon022/Edg
FedRight: An Effective Model Copyright Protection for Federated Learning
Mar 18, 2023Federated learning (FL), an effective distributed machine learning framework, implements model training and meanwhile protects local data privacy. It has been applied to a broad variety of practice areas due to its great performance and appreciable profits. Who owns the model, and how to protect the copyright has become a real problem. Intuitively, the existing property rights protection methods in centralized scenarios (e.g., watermark embedding and model fingerprints) are possible solutions for FL. But they are still challenged by the distributed nature of FL in aspects of the no data sharing, parameter aggregation, and federated training settings. For the first time, we formalize the problem of copyright protection for FL, and propose FedRight to protect model copyright based on model fingerprints, i.e., extracting model features by generating adversarial examples as model fingerprints. FedRight outperforms previous works in four key aspects: (i) Validity: it extracts model features to generate transferable fingerprints to train a detector to verify the copyright of the model. (ii) Fidelity: it is with imperceptible impact on the federated training, thus promising good main task performance. (iii) Robustness: it is empirically robust against malicious attacks on copyright protection, i.e., fine-tuning, model pruning, and adaptive attacks. (iv) Black-box: it is valid in the black-box forensic scenario where only application programming interface calls to the model are available. Extensive evaluations across 3 datasets and 9 model structures demonstrate FedRight's superior fidelity, validity, and robustness.
Motif-Backdoor: Rethinking the Backdoor Attack on Graph Neural Networks via Motifs
Oct 25, 2022Graph neural network (GNN) with a powerful representation capability has been widely applied to various areas, such as biological gene prediction, social recommendation, etc. Recent works have exposed that GNN is vulnerable to the backdoor attack, i.e., models trained with maliciously crafted training samples are easily fooled by patched samples. Most of the proposed studies launch the backdoor attack using a trigger that either is the randomly generated subgraph (e.g., erd\H{o}s-r\'enyi backdoor) for less computational burden, or the gradient-based generative subgraph (e.g., graph trojaning attack) to enable a more effective attack. However, the interpretation of how is the trigger structure and the effect of the backdoor attack related has been overlooked in the current literature. Motifs, recurrent and statistically significant sub-graphs in graphs, contain rich structure information. In this paper, we are rethinking the trigger from the perspective of motifs, and propose a motif-based backdoor attack, denoted as Motif-Backdoor. It contributes from three aspects. (i) Interpretation: it provides an in-depth explanation for backdoor effectiveness by the validity of the trigger structure from motifs, leading to some novel insights, e.g., using subgraphs that appear less frequently in the graph as the trigger can achieve better attack performance. (ii) Effectiveness: Motif-Backdoor reaches the state-of-the-art (SOTA) attack performance in both black-box and defensive scenarios. (iii) Efficiency: based on the graph motif distribution, Motif-Backdoor can quickly obtain an effective trigger structure without target model feedback or subgraph model generation. Extensive experimental results show that Motif-Backdoor realizes the SOTA performance on three popular models and four public datasets compared with five baselines.
Link-Backdoor: Backdoor Attack on Link Prediction via Node Injection
Aug 14, 2022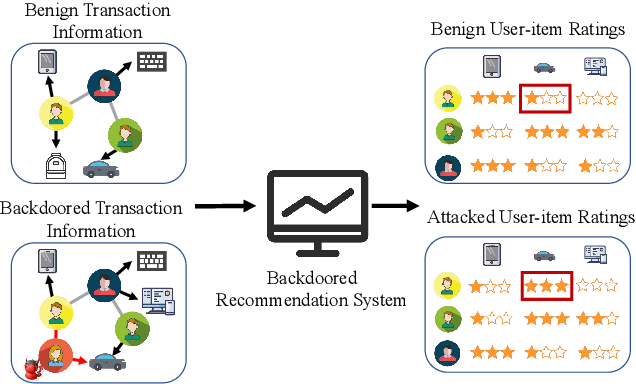

Link prediction, inferring the undiscovered or potential links of the graph, is widely applied in the real-world. By facilitating labeled links of the graph as the training data, numerous deep learning based link prediction methods have been studied, which have dominant prediction accuracy compared with non-deep methods. However,the threats of maliciously crafted training graph will leave a specific backdoor in the deep model, thus when some specific examples are fed into the model, it will make wrong prediction, defined as backdoor attack. It is an important aspect that has been overlooked in the current literature. In this paper, we prompt the concept of backdoor attack on link prediction, and propose Link-Backdoor to reveal the training vulnerability of the existing link prediction methods. Specifically, the Link-Backdoor combines the fake nodes with the nodes of the target link to form a trigger. Moreover, it optimizes the trigger by the gradient information from the target model. Consequently, the link prediction model trained on the backdoored dataset will predict the link with trigger to the target state. Extensive experiments on five benchmark datasets and five well-performing link prediction models demonstrate that the Link-Backdoor achieves the state-of-the-art attack success rate under both white-box (i.e., available of the target model parameter)and black-box (i.e., unavailable of the target model parameter) scenarios. Additionally, we testify the attack under defensive circumstance, and the results indicate that the Link-Backdoor still can construct successful attack on the well-performing link prediction methods. The code and data are available at https://github.com/Seaocn/Link-Backdoor.