 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Efficient Adversarial Attack Against Vertical Federated Graph Learning
Nov 05, 2024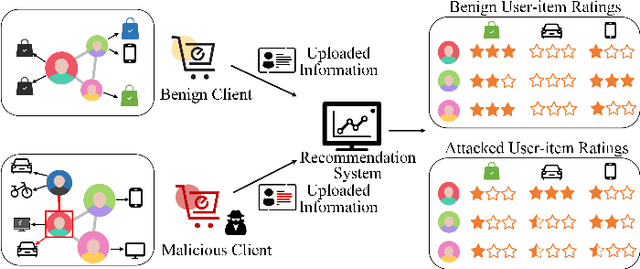
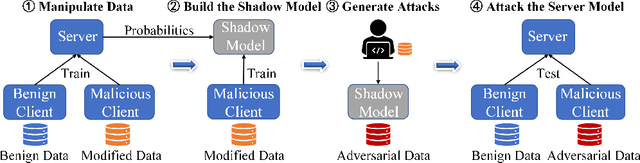
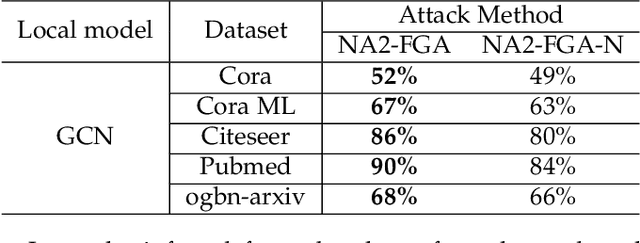
Graph neural network (GNN) has captured wide attention due to its capability of graph representation learning for graph-structured data. However, the distributed data silos limit the performance of GNN. Vertical federated learning (VFL), an emerging technique to process distributed data, successfully makes GNN possible to handle the distributed graph-structured data. Despite the prosperous development of vertical federated graph learning (VFGL), the robustness of VFGL against the adversarial attack has not been explored yet. Although numerous adversarial attacks against centralized GNNs are proposed, their attack performance is challenged in the VFGL scenario. To the best of our knowledge, this is the first work to explore the adversarial attack against VFGL. A query-efficient hybrid adversarial attack framework is proposed to significantly improve the centralized adversarial attacks against VFGL, denoted as NA2, short for Neuron-based Adversarial Attack. Specifically, a malicious client manipulates its local training data to improve its contribution in a stealthy fashion. Then a shadow model is established based on the manipulated data to simulate the behavior of the server model in VFGL. As a result, the shadow model can improve the attack success rate of various centralized attacks with a few queries. Extensive experiments on five real-world benchmarks demonstrate that NA2 improves the performance of the centralized adversarial attacks against VFGL, achieving state-of-the-art performance even under potential adaptive defense where the defender knows the attack method. Additionally, we provide interpretable experiments of the effectiveness of NA2 via sensitive neurons identification and visualization of t-SNE.
Motif-Backdoor: Rethinking the Backdoor Attack on Graph Neural Networks via Motifs
Oct 25, 2022Graph neural network (GNN) with a powerful representation capability has been widely applied to various areas, such as biological gene prediction, social recommendation, etc. Recent works have exposed that GNN is vulnerable to the backdoor attack, i.e., models trained with maliciously crafted training samples are easily fooled by patched samples. Most of the proposed studies launch the backdoor attack using a trigger that either is the randomly generated subgraph (e.g., erd\H{o}s-r\'enyi backdoor) for less computational burden, or the gradient-based generative subgraph (e.g., graph trojaning attack) to enable a more effective attack. However, the interpretation of how is the trigger structure and the effect of the backdoor attack related has been overlooked in the current literature. Motifs, recurrent and statistically significant sub-graphs in graphs, contain rich structure information. In this paper, we are rethinking the trigger from the perspective of motifs, and propose a motif-based backdoor attack, denoted as Motif-Backdoor. It contributes from three aspects. (i) Interpretation: it provides an in-depth explanation for backdoor effectiveness by the validity of the trigger structure from motifs, leading to some novel insights, e.g., using subgraphs that appear less frequently in the graph as the trigger can achieve better attack performance. (ii) Effectiveness: Motif-Backdoor reaches the state-of-the-art (SOTA) attack performance in both black-box and defensive scenarios. (iii) Efficiency: based on the graph motif distribution, Motif-Backdoor can quickly obtain an effective trigger structure without target model feedback or subgraph model generation. Extensive experimental results show that Motif-Backdoor realizes the SOTA performance on three popular models and four public datasets compared with five baselines.
Link-Backdoor: Backdoor Attack on Link Prediction via Node Injection
Aug 14, 2022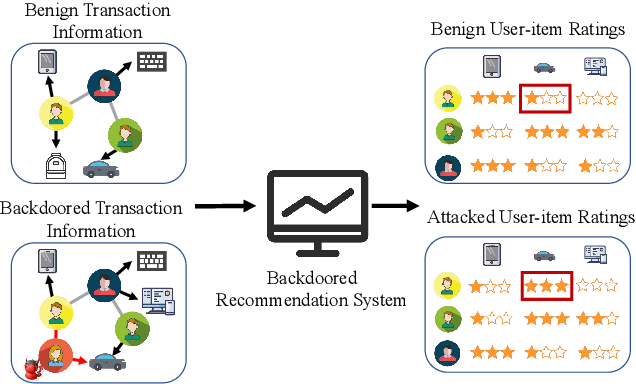

Link prediction, inferring the undiscovered or potential links of the graph, is widely applied in the real-world. By facilitating labeled links of the graph as the training data, numerous deep learning based link prediction methods have been studied, which have dominant prediction accuracy compared with non-deep methods. However,the threats of maliciously crafted training graph will leave a specific backdoor in the deep model, thus when some specific examples are fed into the model, it will make wrong prediction, defined as backdoor attack. It is an important aspect that has been overlooked in the current literature. In this paper, we prompt the concept of backdoor attack on link prediction, and propose Link-Backdoor to reveal the training vulnerability of the existing link prediction methods. Specifically, the Link-Backdoor combines the fake nodes with the nodes of the target link to form a trigger. Moreover, it optimizes the trigger by the gradient information from the target model. Consequently, the link prediction model trained on the backdoored dataset will predict the link with trigger to the target state. Extensive experiments on five benchmark datasets and five well-performing link prediction models demonstrate that the Link-Backdoor achieves the state-of-the-art attack success rate under both white-box (i.e., available of the target model parameter)and black-box (i.e., unavailable of the target model parameter) scenarios. Additionally, we testify the attack under defensive circumstance, and the results indicate that the Link-Backdoor still can construct successful attack on the well-performing link prediction methods. The code and data are available at https://github.com/Seaocn/Link-Backdoor.
Graph-Fraudster: Adversarial Attacks on Graph Neural Network Based Vertical Federated Learning
Oct 13, 2021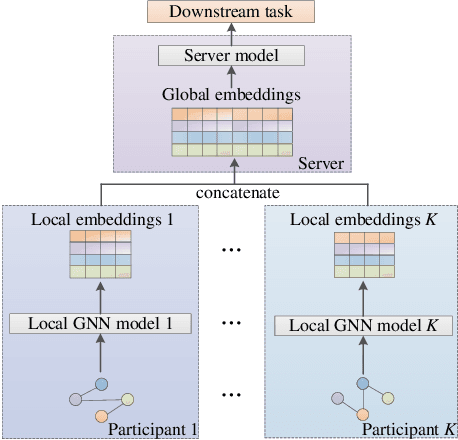
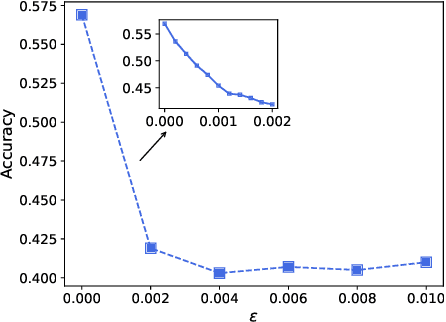
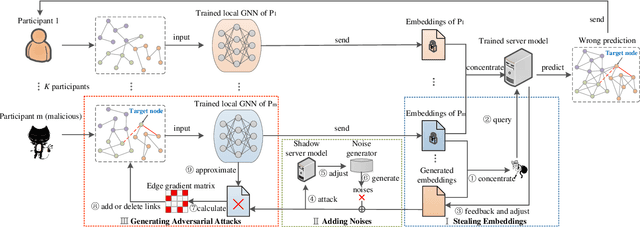
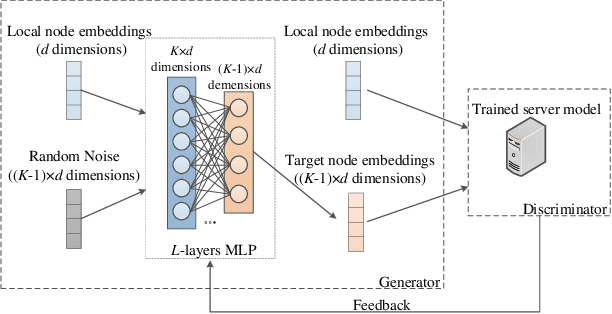
Graph neural network (GNN) models have achieved great success on graph representation learning. Challenged by large scale private data collection from user-side, GNN models may not be able to reflect the excellent performance, without rich features and complete adjacent relationships. Addressing to the problem, vertical federated learning (VFL) is proposed to implement local data protection through training a global model collaboratively. Consequently, for graph-structured data, it is natural idea to construct VFL framework with GNN models. However, GNN models are proven to be vulnerable to adversarial attacks. Whether the vulnerability will be brought into the VFL has not been studied. In this paper, we devote to study the security issues of GNN based VFL (GVFL), i.e., robustness against adversarial attacks. Further, we propose an adversarial attack method, named Graph-Fraudster. It generates adversarial perturbations based on the noise-added global node embeddings via GVFL's privacy leakage, and the gradient of pairwise node. First, it steals the global node embeddings and sets up a shadow server model for attack generator. Second, noises are added into node embeddings to confuse the shadow server model. At last, the gradient of pairwise node is used to generate attacks with the guidance of noise-added node embeddings. To the best of our knowledge, this is the first study of adversarial attacks on GVFL. The extensive experiments on five benchmark datasets demonstrate that Graph-Fraudster performs better than three possible baselines in GVFL. Furthermore, Graph-Fraudster can remain a threat to GVFL even if two possible defense mechanisms are applied. This paper reveals that GVFL is vulnerable to adversarial attack similar to centralized GNN models.
Graphfool: Targeted Label Adversarial Attack on Graph Embedding
Feb 24, 2021
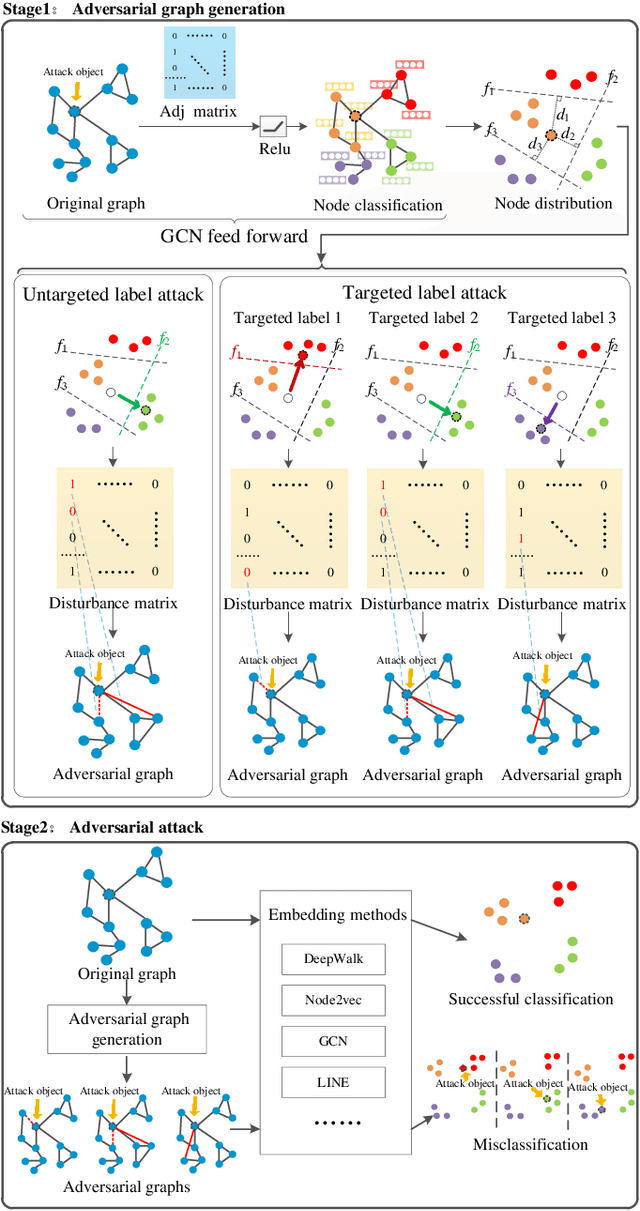
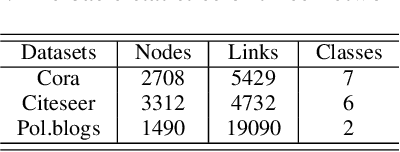
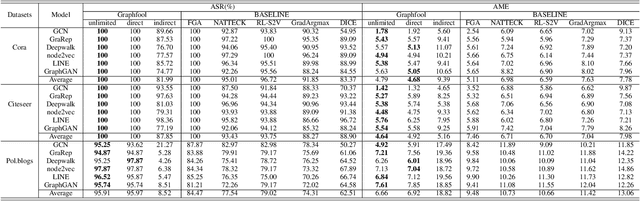
Deep learning is effective in graph analysis. It is widely applied in many related areas, such as link prediction, node classification, community detection, and graph classification etc. Graph embedding, which learns low-dimensional representations for vertices or edges in the graph, usually employs deep models to derive the embedding vector. However, these models are vulnerable. We envision that graph embedding methods based on deep models can be easily attacked using adversarial examples. Thus, in this paper, we propose Graphfool, a novel targeted label adversarial attack on graph embedding. It can generate adversarial graph to attack graph embedding methods via classifying boundary and gradient information in graph convolutional network (GCN). Specifically, we perform the following steps: 1),We first estimate the classification boundaries of different classes. 2), We calculate the minimal perturbation matrix to misclassify the attacked vertex according to the target classification boundary. 3), We modify the adjacency matrix according to the maximal absolute value of the disturbance matrix. This process is implemented iteratively. To the best of our knowledge, this is the first targeted label attack technique. The experiments on real-world graph networks demonstrate that Graphfool can derive better performance than state-of-art techniques. Compared with the second best algorithm, Graphfool can achieve an average improvement of 11.44% in attack success rate.