 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Makes a Desired Graph for Relational Deep Learning?
Jun 07, 2026Relational deep learning (RDL) converts relational databases (RDBs) into heterogeneous graphs, but graphs derived directly from database schemas are often not well suited for how graph neural networks (GNNs) perform relational reasoning. We study what makes a relational graph suitable for deep learning and show that schema-derived graphs suffer from two systematic failures: information overload and semantic fragmentation. Our empirical analysis reveals that the desired graph is not the raw schema, but a result of controlled structural adaptation. Performance depends on balancing two operations: mitigating information overload via filtering, and repairing semantic fragmentation via injection. Specifically, filtering serves as a bias-variance knob with non-monotonic effects, while injection improves performance only when it explicitly restores the relational dependencies missing from the original schema. Based on these findings, we develop an end-to-end structural optimizer that applies both operations to adapt relational graphs automatically. Across 26 tasks spanning classification, regression, and recommendation, the optimized graphs consistently improve accuracy while often reducing inference cost.
FaceRefiner: High-Fidelity Facial Texture Refinement with Differentiable Rendering-based Style Transfer
Jan 08, 2026Recent facial texture generation methods prefer to use deep networks to synthesize image content and then fill in the UV map, thus generating a compelling full texture from a single image. Nevertheless, the synthesized texture UV map usually comes from a space constructed by the training data or the 2D face generator, which limits the methods' generalization ability for in-the-wild input images. Consequently, their facial details, structures and identity may not be consistent with the input. In this paper, we address this issue by proposing a style transfer-based facial texture refinement method named FaceRefiner. FaceRefiner treats the 3D sampled texture as style and the output of a texture generation method as content. The photo-realistic style is then expected to be transferred from the style image to the content image. Different from current style transfer methods that only transfer high and middle level information to the result, our style transfer method integrates differentiable rendering to also transfer low level (or pixel level) information in the visible face regions. The main benefit of such multi-level information transfer is that, the details, structures and semantics in the input can thus be well preserved. The extensive experiments on Multi-PIE, CelebA and FFHQ datasets demonstrate that our refinement method can improve the texture quality and the face identity preserving ability, compared with state-of-the-arts.
Reconstructing Physics-Informed Machine Learning for Traffic Flow Modeling: a Multi-Gradient Descent and Pareto Learning Approach
May 19, 2025Physics-informed machine learning (PIML) is crucial in modern traffic flow modeling because it combines the benefits of both physics-based and data-driven approaches. In conventional PIML, physical information is typically incorporated by constructing a hybrid loss function that combines data-driven loss and physics loss through linear scalarization. The goal is to find a trade-off between these two objectives to improve the accuracy of model predictions. However, from a mathematical perspective, linear scalarization is limited to identifying only the convex region of the Pareto front, as it treats data-driven and physics losses as separate objectives. Given that most PIML loss functions are non-convex, linear scalarization restricts the achievable trade-off solutions. Moreover, tuning the weighting coefficients for the two loss components can be both time-consuming and computationally challenging. To address these limitations, this paper introduces a paradigm shift in PIML by reformulating the training process as a multi-objective optimization problem, treating data-driven loss and physics loss independently. We apply several multi-gradient descent algorithms (MGDAs), including traditional multi-gradient descent (TMGD) and dual cone gradient descent (DCGD), to explore the Pareto front in this multi-objective setting. These methods are evaluated on both macroscopic and microscopic traffic flow models. In the macroscopic case, MGDAs achieved comparable performance to traditional linear scalarization methods. Notably, in the microscopic case, MGDAs significantly outperformed their scalarization-based counterparts, demonstrating the advantages of a multi-objective optimization approach in complex PIML scenarios.
Potential failures of physics-informed machine learning in traffic flow modeling: theoretical and experimental analysis
May 16, 2025
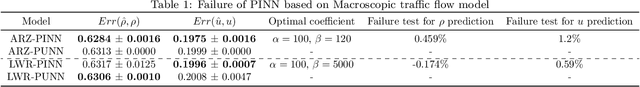
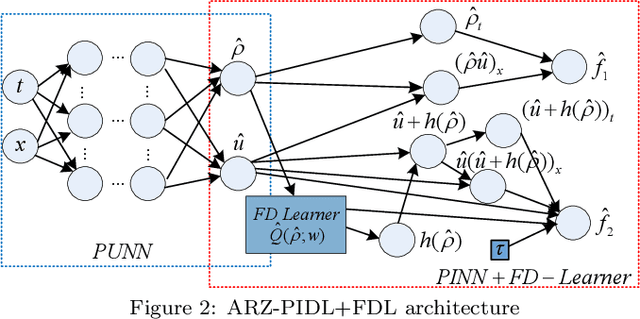
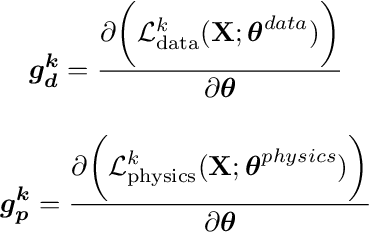
This study critically examines the performance of physics-informed machine learning (PIML) approaches for traffic flow modeling, defining the failure of a PIML model as the scenario where it underperforms both its purely data-driven and purely physics-based counterparts. We analyze the loss landscape by perturbing trained models along the principal eigenvectors of the Hessian matrix and evaluating corresponding loss values. Our results suggest that physics residuals in PIML do not inherently hinder optimization, contrary to a commonly assumed failure cause. Instead, successful parameter updates require both ML and physics gradients to form acute angles with the quasi-true gradient and lie within a conical region. Given inaccuracies in both the physics models and the training data, satisfying this condition is often difficult. Experiments reveal that physical residuals can degrade the performance of LWR- and ARZ-based PIML models, especially under highly physics-driven settings. Moreover, sparse sampling and the use of temporally averaged traffic data can produce misleadingly small physics residuals that fail to capture actual physical dynamics, contributing to model failure. We also identify the Courant-Friedrichs-Lewy (CFL) condition as a key indicator of dataset suitability for PIML, where successful applications consistently adhere to this criterion. Lastly, we observe that higher-order models like ARZ tend to have larger error lower bounds than lower-order models like LWR, which is consistent with the experimental findings of existing studies.
Intelligent Spatial Perception by Building Hierarchical 3D Scene Graphs for Indoor Scenarios with the Help of LLMs
Mar 19, 2025

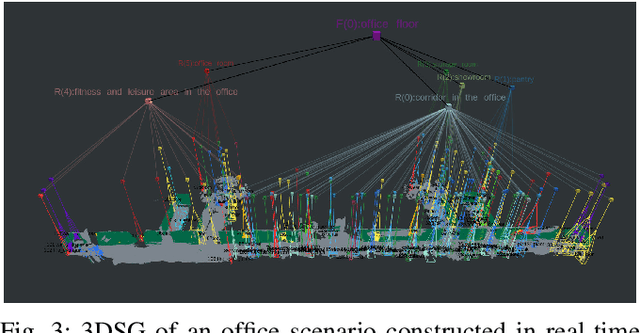

This paper addresses the high demand in advanced intelligent robot navigation for a more holistic understanding of spatial environments, by introducing a novel system that harnesses the capabilities of Large Language Models (LLMs) to construct hierarchical 3D Scene Graphs (3DSGs) for indoor scenarios. The proposed framework constructs 3DSGs consisting of a fundamental layer with rich metric-semantic information, an object layer featuring precise point-cloud representation of object nodes as well as visual descriptors, and higher layers of room, floor, and building nodes. Thanks to the innovative application of LLMs, not only object nodes but also nodes of higher layers, e.g., room nodes, are annotated in an intelligent and accurate manner. A polling mechanism for room classification using LLMs is proposed to enhance the accuracy and reliability of the room node annotation. Thorough numerical experiments demonstrate the system's ability to integrate semantic descriptions with geometric data, creating an accurate and comprehensive representation of the environment instrumental for context-aware navigation and task planning.
Human Cognition Inspired RAG with Knowledge Graph for Complex Problem Solving
Mar 09, 2025Large language models (LLMs) have demonstrated transformative potential across various domains, yet they face significant challenges in knowledge integration and complex problem reasoning, often leading to hallucinations and unreliable outputs. Retrieval-Augmented Generation (RAG) has emerged as a promising solution to enhance LLMs accuracy by incorporating external knowledge. However, traditional RAG systems struggle with processing complex relational information and multi-step reasoning, limiting their effectiveness in advanced problem-solving tasks. To address these limitations, we propose CogGRAG, a cognition inspired graph-based RAG framework, designed to improve LLMs performance in Knowledge Graph Question Answering (KGQA). Inspired by the human cognitive process of decomposing complex problems and performing self-verification, our framework introduces a three-stage methodology: decomposition, retrieval, and reasoning with self-verification. By integrating these components, CogGRAG enhances the accuracy of LLMs in complex problem solving. We conduct systematic experiments with three LLM backbones on four benchmark datasets, where CogGRAG outperforms the baselines.
SEAGraph: Unveiling the Whole Story of Paper Review Comments
Dec 16, 2024



Peer review, as a cornerstone of scientific research, ensures the integrity and quality of scholarly work by providing authors with objective feedback for refinement. However, in the traditional peer review process, authors often receive vague or insufficiently detailed feedback, which provides limited assistance and leads to a more time-consuming review cycle. If authors can identify some specific weaknesses in their paper, they can not only address the reviewer's concerns but also improve their work. This raises the critical question of how to enhance authors' comprehension of review comments. In this paper, we present SEAGraph, a novel framework developed to clarify review comments by uncovering the underlying intentions behind them. We construct two types of graphs for each paper: the semantic mind graph, which captures the author's thought process, and the hierarchical background graph, which delineates the research domains related to the paper. A retrieval method is then designed to extract relevant content from both graphs, facilitating coherent explanations for the review comments. Extensive experiments show that SEAGraph excels in review comment understanding tasks, offering significant benefits to authors.
Query-Efficient Adversarial Attack Against Vertical Federated Graph Learning
Nov 05, 2024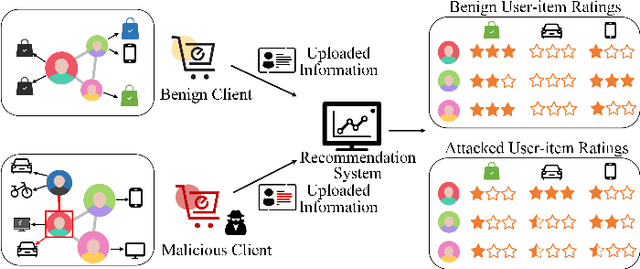
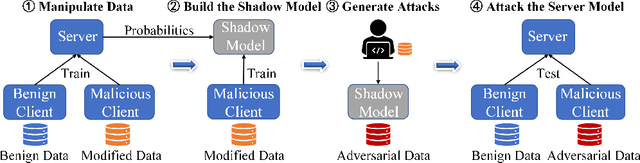
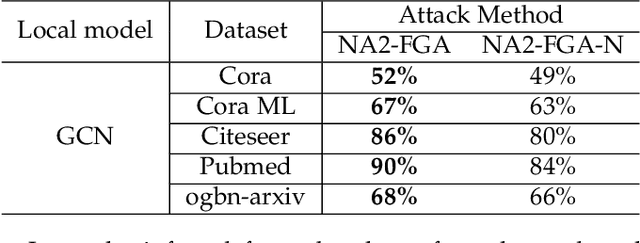
Graph neural network (GNN) has captured wide attention due to its capability of graph representation learning for graph-structured data. However, the distributed data silos limit the performance of GNN. Vertical federated learning (VFL), an emerging technique to process distributed data, successfully makes GNN possible to handle the distributed graph-structured data. Despite the prosperous development of vertical federated graph learning (VFGL), the robustness of VFGL against the adversarial attack has not been explored yet. Although numerous adversarial attacks against centralized GNNs are proposed, their attack performance is challenged in the VFGL scenario. To the best of our knowledge, this is the first work to explore the adversarial attack against VFGL. A query-efficient hybrid adversarial attack framework is proposed to significantly improve the centralized adversarial attacks against VFGL, denoted as NA2, short for Neuron-based Adversarial Attack. Specifically, a malicious client manipulates its local training data to improve its contribution in a stealthy fashion. Then a shadow model is established based on the manipulated data to simulate the behavior of the server model in VFGL. As a result, the shadow model can improve the attack success rate of various centralized attacks with a few queries. Extensive experiments on five real-world benchmarks demonstrate that NA2 improves the performance of the centralized adversarial attacks against VFGL, achieving state-of-the-art performance even under potential adaptive defense where the defender knows the attack method. Additionally, we provide interpretable experiments of the effectiveness of NA2 via sensitive neurons identification and visualization of t-SNE.
ROADFIRST: A Comprehensive Enhancement of the Systemic Approach to Safety for Improved Risk Factor Identification and Evaluation
Oct 28, 2024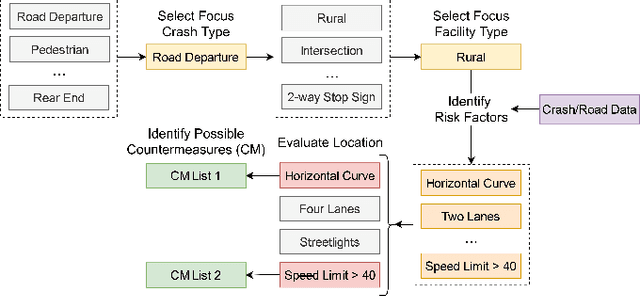
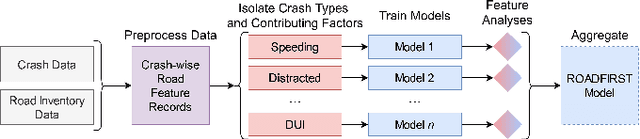
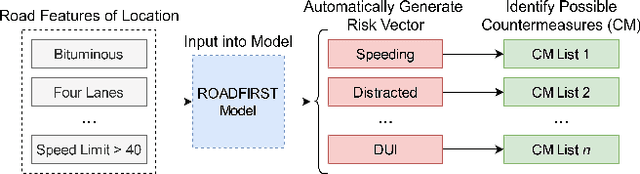
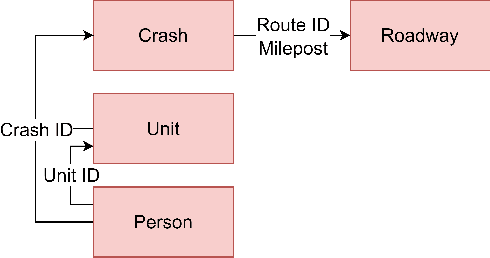
Many agencies have adopted the FHWA-recommended systemic approach to traffic safety, an essential supplement to the traditional hotspot crash analysis which develops region-wide safety projects based on identified risk factors. However, this approach narrows analysis to specific crash and facility types. This specification causes inefficient use of crash and inventory data as well as non-comprehensive risk evaluation and countermeasure selection for each location. To improve the comprehensiveness of the systemic approach to safety, we develop an enhanced process, ROADFIRST, that allows users to identify potential crash types and contributing factors at any location. As the knowledge base for such a process, crash types and contributing factors are analyzed with respect to features of interest, including both dynamic and static traffic-related features, using Random Forest and analyzed with the SHapley Additive exPlanations (SHAP) analysis. We identify and rank features impacting the likelihood of three sample contributing factors, namely alcohol-impaired driving, distracted driving, and speeding, according to crash and road inventory data from North Carolina, and quantify state-wide road segment risk for each contributing factor. The introduced models and methods serve as a sample for the further development of ROADFIRST by state and local agencies, which benefits the planning of more comprehensive region-wide safety improvement projects.
Can Large Language Models Act as Ensembler for Multi-GNNs?
Oct 22, 2024



Graph Neural Networks (GNNs) have emerged as powerful models for learning from graph-structured data. However, GNNs lack the inherent semantic understanding capability of rich textual nodesattributes, limiting their effectiveness in applications. On the other hand, we empirically observe that for existing GNN models, no one can consistently outperforms others across diverse datasets. In this paper, we study whether LLMs can act as an ensembler for multi-GNNs and propose the LensGNN model. The model first aligns multiple GNNs, mapping the representations of different GNNs into the same space. Then, through LoRA fine-tuning, it aligns the space between the GNN and the LLM, injecting graph tokens and textual information into LLMs. This allows LensGNN to integrate multiple GNNs and leverage LLM's strengths, resulting in better performance. Experimental results show that LensGNN outperforms existing models. This research advances text-attributed graph ensemble learning by providing a robust, superior solution for integrating semantic and structural information. We provide our code and data here: https://anonymous.4open.science/r/EnsemGNN-E267/.