 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Open-source World Models
Jan 28, 2026We present LingBot-World, an open-sourced world simulator stemming from video generation. Positioned as a top-tier world model, LingBot-World offers the following features. (1) It maintains high fidelity and robust dynamics in a broad spectrum of environments, including realism, scientific contexts, cartoon styles, and beyond. (2) It enables a minute-level horizon while preserving contextual consistency over time, which is also known as "long-term memory". (3) It supports real-time interactivity, achieving a latency of under 1 second when producing 16 frames per second. We provide public access to the code and model in an effort to narrow the divide between open-source and closed-source technologies. We believe our release will empower the community with practical applications across areas like content creation, gaming, and robot learning.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
HCFT: Hierarchical Convolutional Fusion Transformer for EEG Decoding
Jan 18, 2026Electroencephalography (EEG) decoding requires models that can effectively extract and integrate complex temporal, spectral, and spatial features from multichannel signals. To address this challenge, we propose a lightweight and generalizable decoding framework named Hierarchical Convolutional Fusion Transformer (HCFT), which combines dual-branch convolutional encoders and hierarchical Transformer blocks for multi-scale EEG representation learning. Specifically, the model first captures local temporal and spatiotemporal dynamics through time-domain and time-space convolutional branches, and then aligns these features via a cross-attention mechanism that enables interaction between branches at each stage. Subsequently, a hierarchical Transformer fusion structure is employed to encode global dependencies across all feature stages, while a customized Dynamic Tanh normalization module is introduced to replace traditional Layer Normalization in order to enhance training stability and reduce redundancy. Extensive experiments are conducted on two representative benchmark datasets, BCI Competition IV-2b and CHB-MIT, covering both event-related cross-subject classification and continuous seizure prediction tasks. Results show that HCFT achieves 80.83% average accuracy and a Cohen's kappa of 0.6165 on BCI IV-2b, as well as 99.10% sensitivity, 0.0236 false positives per hour, and 98.82% specificity on CHB-MIT, consistently outperforming over ten state-of-the-art baseline methods. Ablation studies confirm that each core component of the proposed framework contributes significantly to the overall decoding performance, demonstrating HCFT's effectiveness in capturing EEG dynamics and its potential for real-world BCI applications.
GRACE: Reinforcement Learning for Grounded Response and Abstention under Contextual Evidence
Jan 08, 2026Retrieval-Augmented Generation (RAG) integrates external knowledge to enhance Large Language Models (LLMs), yet systems remain susceptible to two critical flaws: providing correct answers without explicit grounded evidence and producing fabricated responses when the retrieved context is insufficient. While prior research has addressed these issues independently, a unified framework that integrates evidence-based grounding and reliable abstention is currently lacking. In this paper, we propose GRACE, a reinforcement-learning framework that simultaneously mitigates both types of flaws. GRACE employs a data construction method that utilizes heterogeneous retrievers to generate diverse training samples without manual annotation. A multi-stage gated reward function is then employed to train the model to assess evidence sufficiency, extract key supporting evidence, and provide answers or explicitly abstain. Experimental results on two benchmarks demonstrate that GRACE achieves state-of-the-art overall accuracy and strikes a favorable balance between accurate response and rejection, while requiring only 10% of the annotation costs of prior methods. Our code is available at https://github.com/YiboZhao624/Grace..
UCD: Unconditional Discriminator Promotes Nash Equilibrium in GANs
Oct 01, 2025Adversarial training turns out to be the key to one-step generation, especially for Generative Adversarial Network (GAN) and diffusion model distillation. Yet in practice, GAN training hardly converges properly and struggles in mode collapse. In this work, we quantitatively analyze the extent of Nash equilibrium in GAN training, and conclude that redundant shortcuts by inputting condition in $D$ disables meaningful knowledge extraction. We thereby propose to employ an unconditional discriminator (UCD), in which $D$ is enforced to extract more comprehensive and robust features with no condition injection. In this way, $D$ is able to leverage better knowledge to supervise $G$, which promotes Nash equilibrium in GAN literature. Theoretical guarantee on compatibility with vanilla GAN theory indicates that UCD can be implemented in a plug-in manner. Extensive experiments confirm the significant performance improvements with high efficiency. For instance, we achieved \textbf{1.47 FID} on the ImageNet-64 dataset, surpassing StyleGAN-XL and several state-of-the-art one-step diffusion models. The code will be made publicly available.
E^2GraphRAG: Streamlining Graph-based RAG for High Efficiency and Effectiveness
May 30, 2025Graph-based RAG methods like GraphRAG have shown promising global understanding of the knowledge base by constructing hierarchical entity graphs. However, they often suffer from inefficiency and rely on manually pre-defined query modes, limiting practical use. In this paper, we propose E^2GraphRAG, a streamlined graph-based RAG framework that improves both Efficiency and Effectiveness. During the indexing stage, E^2GraphRAG constructs a summary tree with large language models and an entity graph with SpaCy based on document chunks. We then construct bidirectional indexes between entities and chunks to capture their many-to-many relationships, enabling fast lookup during both local and global retrieval. For the retrieval stage, we design an adaptive retrieval strategy that leverages the graph structure to retrieve and select between local and global modes. Experiments show that E^2GraphRAG achieves up to 10 times faster indexing than GraphRAG and 100 times speedup over LightRAG in retrieval while maintaining competitive QA performance.
Relation-Aware Graph Foundation Model
May 17, 2025In recent years, large language models (LLMs) have demonstrated remarkable generalization capabilities across various natural language processing (NLP) tasks. Similarly, graph foundation models (GFMs) have emerged as a promising direction in graph learning, aiming to generalize across diverse datasets through large-scale pre-training. However, unlike language models that rely on explicit token representations, graphs lack a well-defined unit for generalization, making it challenging to design effective pre-training strategies. In this work, we propose REEF, a novel framework that leverages relation tokens as the basic units for GFMs. Inspired by the token vocabulary in LLMs, we construct a relation vocabulary of relation tokens to store relational information within graphs. To accommodate diverse relations, we introduce two hypernetworks that adaptively generate the parameters of aggregators and classifiers in graph neural networks based on relation tokens. In addition, we design another hypernetwork to construct dataset-specific projectors and incorporate a dataset-level feature bias into the initial node representations, enhancing flexibility across different datasets with the same relation. Further, we adopt graph data augmentation and a mixed-dataset pre-training strategy, allowing REEF to capture relational diversity more effectively and exhibit strong generalization capabilities. Extensive experiments show that REEF significantly outperforms existing methods on both pre-training and transfer learning tasks, underscoring its potential as a powerful foundation model for graph-based applications.
Hierarchical Vector Quantized Graph Autoencoder with Annealing-Based Code Selection
Apr 17, 2025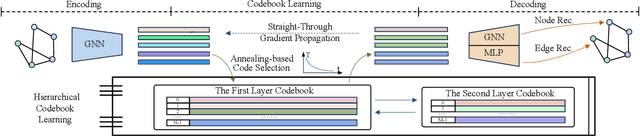
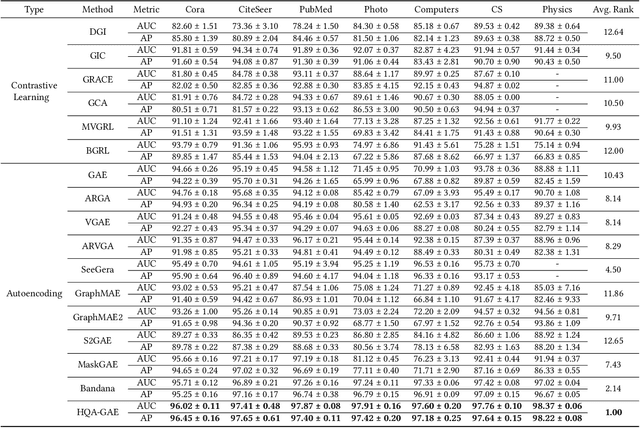
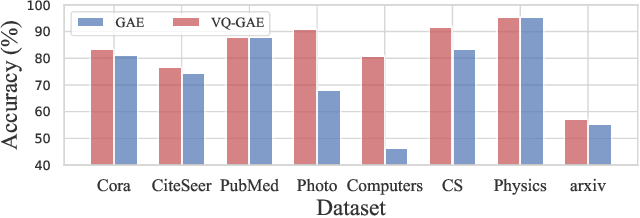
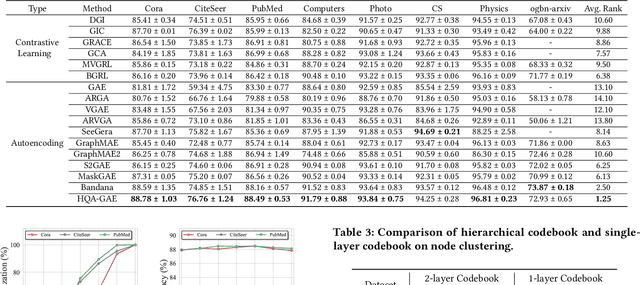
Graph self-supervised learning has gained significant attention recently. However, many existing approaches heavily depend on perturbations, and inappropriate perturbations may corrupt the graph's inherent information. The Vector Quantized Variational Autoencoder (VQ-VAE) is a powerful autoencoder extensively used in fields such as computer vision; however, its application to graph data remains underexplored. In this paper, we provide an empirical analysis of vector quantization in the context of graph autoencoders, demonstrating its significant enhancement of the model's capacity to capture graph topology. Furthermore, we identify two key challenges associated with vector quantization when applying in graph data: codebook underutilization and codebook space sparsity. For the first challenge, we propose an annealing-based encoding strategy that promotes broad code utilization in the early stages of training, gradually shifting focus toward the most effective codes as training progresses. For the second challenge, we introduce a hierarchical two-layer codebook that captures relationships between embeddings through clustering. The second layer codebook links similar codes, encouraging the model to learn closer embeddings for nodes with similar features and structural topology in the graph. Our proposed model outperforms 16 representative baseline methods in self-supervised link prediction and node classification tasks across multiple datasets.
Human Cognition Inspired RAG with Knowledge Graph for Complex Problem Solving
Mar 09, 2025Large language models (LLMs) have demonstrated transformative potential across various domains, yet they face significant challenges in knowledge integration and complex problem reasoning, often leading to hallucinations and unreliable outputs. Retrieval-Augmented Generation (RAG) has emerged as a promising solution to enhance LLMs accuracy by incorporating external knowledge. However, traditional RAG systems struggle with processing complex relational information and multi-step reasoning, limiting their effectiveness in advanced problem-solving tasks. To address these limitations, we propose CogGRAG, a cognition inspired graph-based RAG framework, designed to improve LLMs performance in Knowledge Graph Question Answering (KGQA). Inspired by the human cognitive process of decomposing complex problems and performing self-verification, our framework introduces a three-stage methodology: decomposition, retrieval, and reasoning with self-verification. By integrating these components, CogGRAG enhances the accuracy of LLMs in complex problem solving. We conduct systematic experiments with three LLM backbones on four benchmark datasets, where CogGRAG outperforms the baselines.
Enhancing LLM-based Hatred and Toxicity Detection with Meta-Toxic Knowledge Graph
Dec 24, 2024
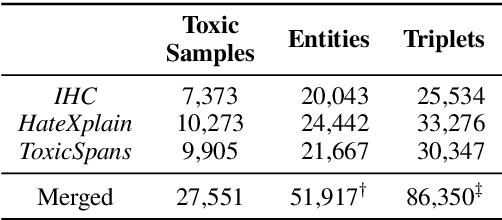
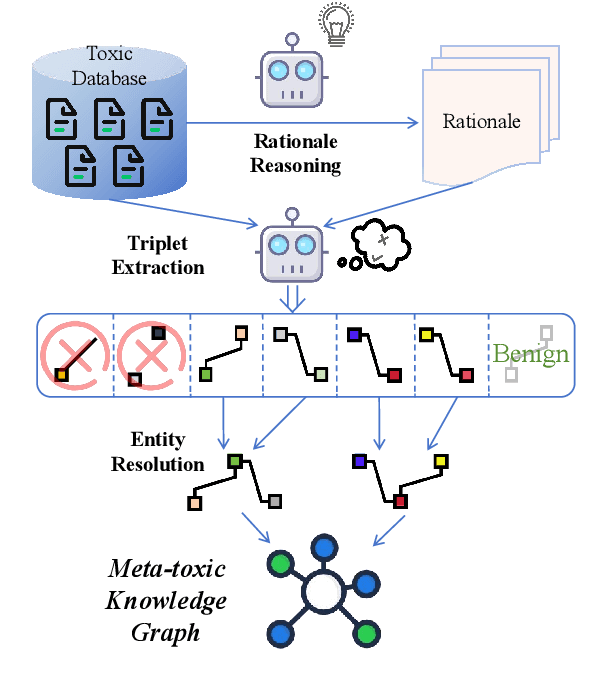
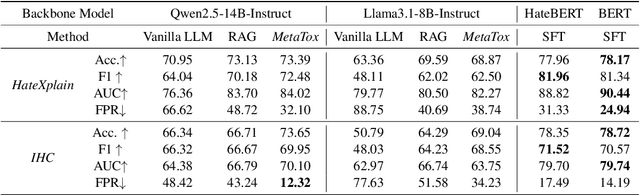
The rapid growth of social media platforms has raised significant concerns regarding online content toxicity. When Large Language Models (LLMs) are used for toxicity detection, two key challenges emerge: 1) the absence of domain-specific toxic knowledge leads to false negatives; 2) the excessive sensitivity of LLMs to toxic speech results in false positives, limiting freedom of speech. To address these issues, we propose a novel method called MetaTox, leveraging graph search on a meta-toxic knowledge graph to enhance hatred and toxicity detection. First, we construct a comprehensive meta-toxic knowledge graph by utilizing LLMs to extract toxic information through a three-step pipeline, with toxic benchmark datasets serving as corpora. Second, we query the graph via retrieval and ranking processes to supplement accurate, relevant toxic knowledge. Extensive experiments and in-depth case studies across multiple datasets demonstrate that our MetaTox significantly decreases the false positive rate while boosting overall toxicity detection performance. Our code will be available soon.