 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEFL: Prediction-Residual-Guided Rolling Forecasting for Multi-Horizon Time Series
Feb 26, 2026Time series forecasting plays a critical role in domains such as transportation, energy, and meteorology. Despite their success, modern deep forecasting models are typically trained to minimize point-wise prediction loss without leveraging the rich information contained in past prediction residuals from rolling forecasts - residuals that reflect persistent biases, unmodeled patterns, or evolving dynamics. We propose TEFL (Temporal Error Feedback Learning), a unified learning framework that explicitly incorporates these historical residuals into the forecasting pipeline during both training and evaluation. To make this practical in deep multi-step settings, we address three key challenges: (1) selecting observable multi-step residuals under the partial observability of rolling forecasts, (2) integrating them through a lightweight low-rank adapter to preserve efficiency and prevent overfitting, and (3) designing a two-stage training procedure that jointly optimizes the base forecaster and error module. Extensive experiments across 10 real-world datasets and 5 backbone architectures show that TEFL consistently improves accuracy, reducing MAE by 5-10% on average. Moreover, it demonstrates strong robustness under abrupt changes and distribution shifts, with error reductions exceeding 10% (up to 19.5%) in challenging scenarios. By embedding residual-based feedback directly into the learning process, TEFL offers a simple, general, and effective enhancement to modern deep forecasting systems.
CSP-AIT-Net: A contrastive learning-enhanced spatiotemporal graph attention framework for short-term metro OD flow prediction with asynchronous inflow tracking
Dec 02, 2024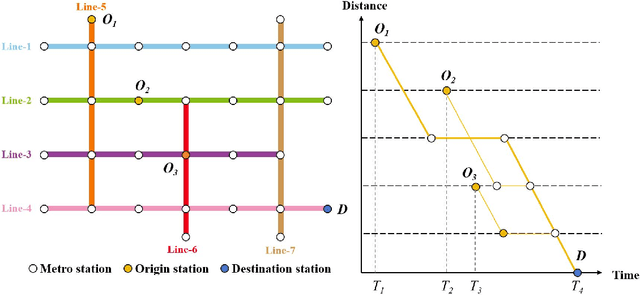
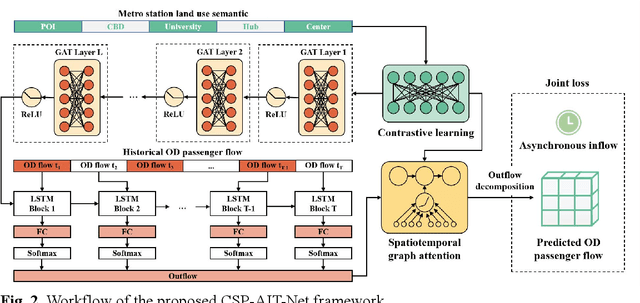
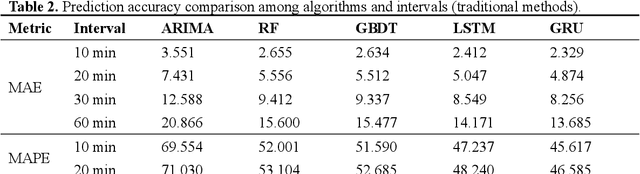
Accurate origin-destination (OD) passenger flow prediction is crucial for enhancing metro system efficiency, optimizing scheduling, and improving passenger experiences. However, current models often fail to effectively capture the asynchronous departure characteristics of OD flows and underutilize the inflow and outflow data, which limits their prediction accuracy. To address these issues, we propose CSP-AIT-Net, a novel spatiotemporal graph attention framework designed to enhance OD flow prediction by incorporating asynchronous inflow tracking and advanced station semantics representation. Our framework restructures the OD flow prediction paradigm by first predicting outflows and then decomposing OD flows using a spatiotemporal graph attention mechanism. To enhance computational efficiency, we introduce a masking mechanism and propose asynchronous passenger flow graphs that integrate inflow and OD flow with conservation constraints. Furthermore, we employ contrastive learning to extract high-dimensional land use semantics of metro stations, enriching the contextual understanding of passenger mobility patterns. Validation of the Shanghai metro system demonstrates improvement in short-term OD flow prediction accuracy over state-of-the-art methods. This work contributes to enhancing metro operational efficiency, scheduling precision, and overall system safety.
Multiscale spatiotemporal heterogeneity analysis of bike-sharing system's self-loop phenomenon: Evidence from Shanghai
Nov 26, 2024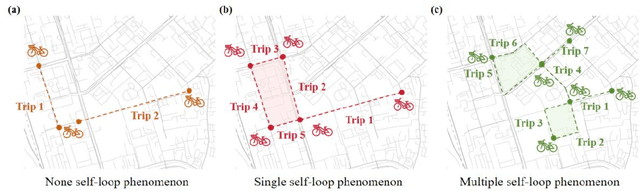
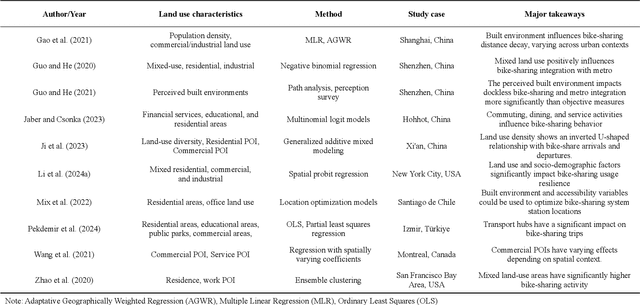
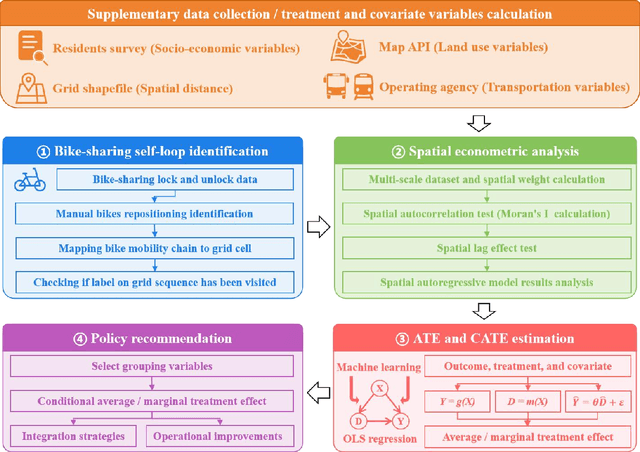

Bike-sharing is an environmentally friendly shared mobility mode, but its self-loop phenomenon, where bikes are returned to the same station after several time usage, significantly impacts equity in accessing its services. Therefore, this study conducts a multiscale analysis with a spatial autoregressive model and double machine learning framework to assess socioeconomic features and geospatial location's impact on the self-loop phenomenon at metro stations and street scales. The results reveal that bike-sharing self-loop intensity exhibits significant spatial lag effect at street scale and is positively associated with residential land use. Marginal treatment effects of residential land use is higher on streets with middle-aged residents, high fixed employment, and low car ownership. The multimodal public transit condition reveals significant positive marginal treatment effects at both scales. To enhance bike-sharing cooperation, we advocate augmenting bicycle availability in areas with high metro usage and low bus coverage, alongside implementing adaptable redistribution strategies.
Class-Balanced and Reinforced Active Learning on Graphs
Feb 19, 2024Graph neural networks (GNNs) have demonstrated significant success in various applications, such as node classification, link prediction, and graph classification. Active learning for GNNs aims to query the valuable samples from the unlabeled data for annotation to maximize the GNNs' performance at a lower cost. However, most existing algorithms for reinforced active learning in GNNs may lead to a highly imbalanced class distribution, especially in highly skewed class scenarios. GNNs trained with class-imbalanced labeled data are susceptible to bias toward majority classes, and the lower performance of minority classes may lead to a decline in overall performance. To tackle this issue, we propose a novel class-balanced and reinforced active learning framework for GNNs, namely, GCBR. It learns an optimal policy to acquire class-balanced and informative nodes for annotation, maximizing the performance of GNNs trained with selected labeled nodes. GCBR designs class-balance-aware states, as well as a reward function that achieves trade-off between model performance and class balance. The reinforcement learning algorithm Advantage Actor-Critic (A2C) is employed to learn an optimal policy stably and efficiently. We further upgrade GCBR to GCBR++ by introducing a punishment mechanism to obtain a more class-balanced labeled set. Extensive experiments on multiple datasets demonstrate the effectiveness of the proposed approaches, achieving superior performance over state-of-the-art baselines.
Self-supervised Heterogeneous Graph Variational Autoencoders
Nov 14, 2023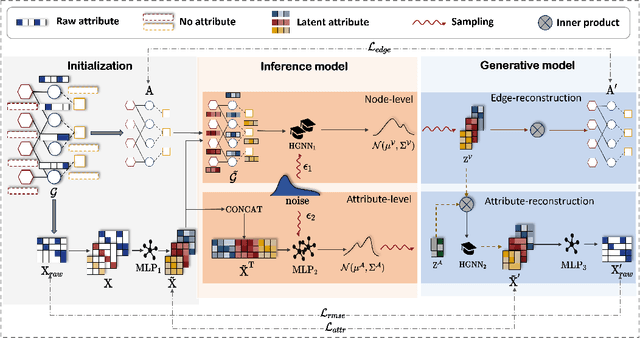
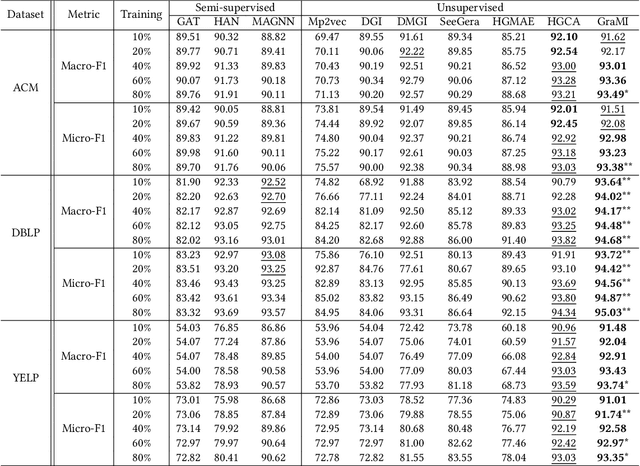
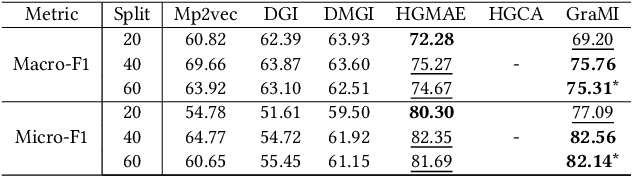
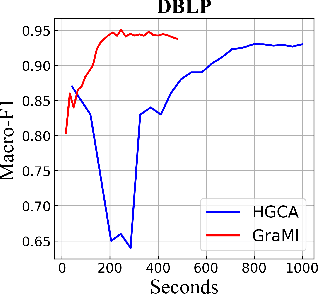
Heterogeneous Information Networks (HINs), which consist of various types of nodes and edges, have recently demonstrated excellent performance in graph mining. However, most existing heterogeneous graph neural networks (HGNNs) ignore the problems of missing attributes, inaccurate attributes and scarce labels for nodes, which limits their expressiveness. In this paper, we propose a generative self-supervised model SHAVA to address these issues simultaneously. Specifically, SHAVA first initializes all the nodes in the graph with a low-dimensional representation matrix. After that, based on the variational graph autoencoder framework, SHAVA learns both node-level and attribute-level embeddings in the encoder, which can provide fine-grained semantic information to construct node attributes. In the decoder, SHAVA reconstructs both links and attributes. Instead of directly reconstructing raw features for attributed nodes, SHAVA generates the initial low-dimensional representation matrix for all the nodes, based on which raw features of attributed nodes are further reconstructed to leverage accurate attributes. In this way, SHAVA can not only complete informative features for non-attributed nodes, but rectify inaccurate ones for attributed nodes. Finally, we conduct extensive experiments to show the superiority of SHAVA in tackling HINs with missing and inaccurate attributes.
Prompt Tuning for Multi-View Graph Contrastive Learning
Oct 16, 2023In recent years, "pre-training and fine-tuning" has emerged as a promising approach in addressing the issues of label dependency and poor generalization performance in traditional GNNs. To reduce labeling requirement, the "pre-train, fine-tune" and "pre-train, prompt" paradigms have become increasingly common. In particular, prompt tuning is a popular alternative to "pre-training and fine-tuning" in natural language processing, which is designed to narrow the gap between pre-training and downstream objectives. However, existing study of prompting on graphs is still limited, lacking a framework that can accommodate commonly used graph pre-training methods and downstream tasks. In this paper, we propose a multi-view graph contrastive learning method as pretext and design a prompting tuning for it. Specifically, we first reformulate graph pre-training and downstream tasks into a common format. Second, we construct multi-view contrasts to capture relevant information of graphs by GNN. Third, we design a prompting tuning method for our multi-view graph contrastive learning method to bridge the gap between pretexts and downsteam tasks. Finally, we conduct extensive experiments on benchmark datasets to evaluate and analyze our proposed method.