 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Academic Poster Editing Agentic Expert
Jan 08, 2026Designing academic posters is a labor-intensive process requiring the precise balance of high-density content and sophisticated layout. While existing paper-to-poster generation methods automate initial drafting, they are typically single-pass and non-interactive, often fail to align with complex, subjective user intent. To bridge this gap, we propose APEX (Academic Poster Editing agentic eXpert), the first agentic framework for interactive academic poster editing, supporting fine-grained control with robust multi-level API-based editing and a review-and-adjustment Mechanism. In addition, we introduce APEX-Bench, the first systematic benchmark comprising 514 academic poster editing instructions, categorized by a multi-dimensional taxonomy including operation type, difficulty, and abstraction level, constructed via reference-guided and reference-free strategies to ensure realism and diversity. We further establish a multi-dimensional VLM-as-a-judge evaluation protocol to assess instruction fulfillment, modification scope, and visual consistency & harmony. Experimental results demonstrate that APEX significantly outperforms baseline methods. Our implementation is available at https://github.com/Breesiu/APEX.
Breaking the Cloak! Unveiling Chinese Cloaked Toxicity with Homophone Graph and Toxic Lexicon
May 28, 2025Social media platforms have experienced a significant rise in toxic content, including abusive language and discriminatory remarks, presenting growing challenges for content moderation. Some users evade censorship by deliberately disguising toxic words through homophonic cloak, which necessitates the task of unveiling cloaked toxicity. Existing methods are mostly designed for English texts, while Chinese cloaked toxicity unveiling has not been solved yet. To tackle the issue, we propose C$^2$TU, a novel training-free and prompt-free method for Chinese cloaked toxic content unveiling. It first employs substring matching to identify candidate toxic words based on Chinese homo-graph and toxic lexicon. Then it filters those candidates that are non-toxic and corrects cloaks to be their corresponding toxicities. Specifically, we develop two model variants for filtering, which are based on BERT and LLMs, respectively. For LLMs, we address the auto-regressive limitation in computing word occurrence probability and utilize the full semantic contexts of a text sequence to reveal cloaked toxic words. Extensive experiments demonstrate that C$^2$TU can achieve superior performance on two Chinese toxic datasets. In particular, our method outperforms the best competitor by up to 71% on the F1 score and 35% on accuracy, respectively.
Relation-Aware Graph Foundation Model
May 17, 2025In recent years, large language models (LLMs) have demonstrated remarkable generalization capabilities across various natural language processing (NLP) tasks. Similarly, graph foundation models (GFMs) have emerged as a promising direction in graph learning, aiming to generalize across diverse datasets through large-scale pre-training. However, unlike language models that rely on explicit token representations, graphs lack a well-defined unit for generalization, making it challenging to design effective pre-training strategies. In this work, we propose REEF, a novel framework that leverages relation tokens as the basic units for GFMs. Inspired by the token vocabulary in LLMs, we construct a relation vocabulary of relation tokens to store relational information within graphs. To accommodate diverse relations, we introduce two hypernetworks that adaptively generate the parameters of aggregators and classifiers in graph neural networks based on relation tokens. In addition, we design another hypernetwork to construct dataset-specific projectors and incorporate a dataset-level feature bias into the initial node representations, enhancing flexibility across different datasets with the same relation. Further, we adopt graph data augmentation and a mixed-dataset pre-training strategy, allowing REEF to capture relational diversity more effectively and exhibit strong generalization capabilities. Extensive experiments show that REEF significantly outperforms existing methods on both pre-training and transfer learning tasks, underscoring its potential as a powerful foundation model for graph-based applications.
Hierarchical Vector Quantized Graph Autoencoder with Annealing-Based Code Selection
Apr 17, 2025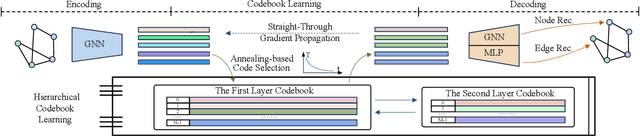
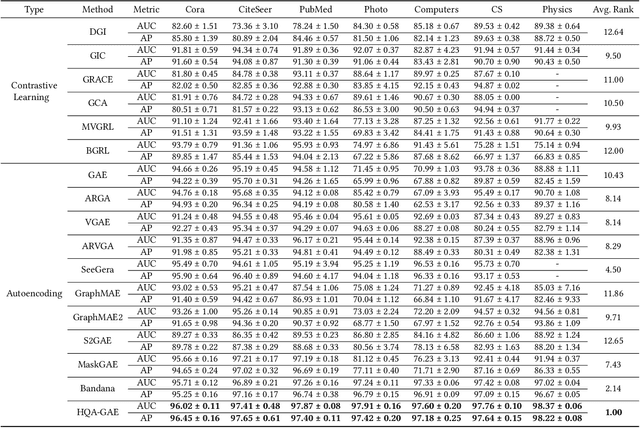
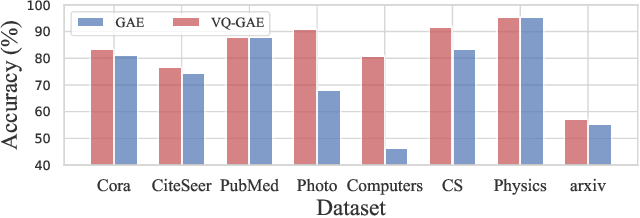
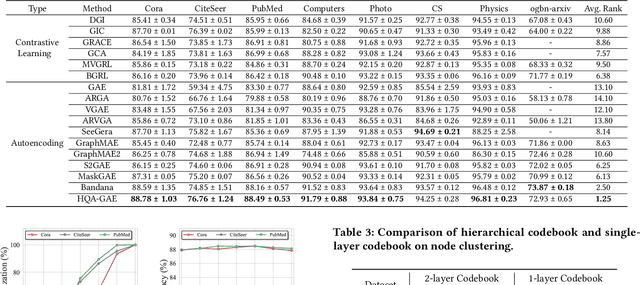
Graph self-supervised learning has gained significant attention recently. However, many existing approaches heavily depend on perturbations, and inappropriate perturbations may corrupt the graph's inherent information. The Vector Quantized Variational Autoencoder (VQ-VAE) is a powerful autoencoder extensively used in fields such as computer vision; however, its application to graph data remains underexplored. In this paper, we provide an empirical analysis of vector quantization in the context of graph autoencoders, demonstrating its significant enhancement of the model's capacity to capture graph topology. Furthermore, we identify two key challenges associated with vector quantization when applying in graph data: codebook underutilization and codebook space sparsity. For the first challenge, we propose an annealing-based encoding strategy that promotes broad code utilization in the early stages of training, gradually shifting focus toward the most effective codes as training progresses. For the second challenge, we introduce a hierarchical two-layer codebook that captures relationships between embeddings through clustering. The second layer codebook links similar codes, encouraging the model to learn closer embeddings for nodes with similar features and structural topology in the graph. Our proposed model outperforms 16 representative baseline methods in self-supervised link prediction and node classification tasks across multiple datasets.
SEAGraph: Unveiling the Whole Story of Paper Review Comments
Dec 16, 2024



Peer review, as a cornerstone of scientific research, ensures the integrity and quality of scholarly work by providing authors with objective feedback for refinement. However, in the traditional peer review process, authors often receive vague or insufficiently detailed feedback, which provides limited assistance and leads to a more time-consuming review cycle. If authors can identify some specific weaknesses in their paper, they can not only address the reviewer's concerns but also improve their work. This raises the critical question of how to enhance authors' comprehension of review comments. In this paper, we present SEAGraph, a novel framework developed to clarify review comments by uncovering the underlying intentions behind them. We construct two types of graphs for each paper: the semantic mind graph, which captures the author's thought process, and the hierarchical background graph, which delineates the research domains related to the paper. A retrieval method is then designed to extract relevant content from both graphs, facilitating coherent explanations for the review comments. Extensive experiments show that SEAGraph excels in review comment understanding tasks, offering significant benefits to authors.
Can Large Language Models Act as Ensembler for Multi-GNNs?
Oct 22, 2024



Graph Neural Networks (GNNs) have emerged as powerful models for learning from graph-structured data. However, GNNs lack the inherent semantic understanding capability of rich textual nodesattributes, limiting their effectiveness in applications. On the other hand, we empirically observe that for existing GNN models, no one can consistently outperforms others across diverse datasets. In this paper, we study whether LLMs can act as an ensembler for multi-GNNs and propose the LensGNN model. The model first aligns multiple GNNs, mapping the representations of different GNNs into the same space. Then, through LoRA fine-tuning, it aligns the space between the GNN and the LLM, injecting graph tokens and textual information into LLMs. This allows LensGNN to integrate multiple GNNs and leverage LLM's strengths, resulting in better performance. Experimental results show that LensGNN outperforms existing models. This research advances text-attributed graph ensemble learning by providing a robust, superior solution for integrating semantic and structural information. We provide our code and data here: https://anonymous.4open.science/r/EnsemGNN-E267/.
RELIEF: Reinforcement Learning Empowered Graph Feature Prompt Tuning
Aug 06, 2024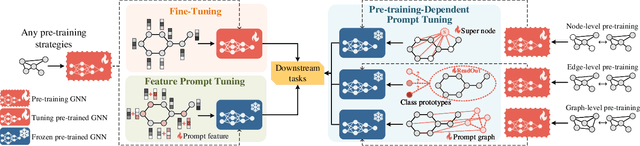
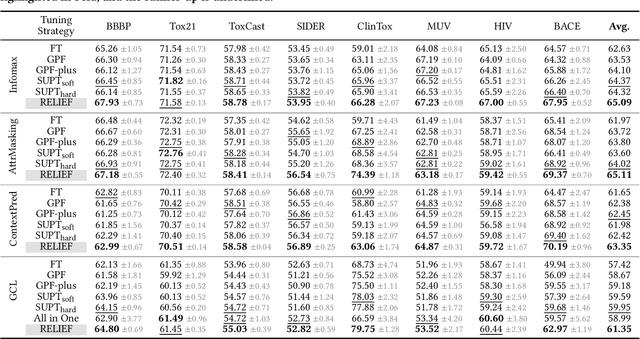
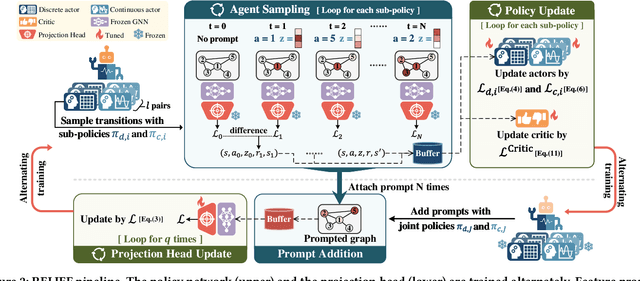
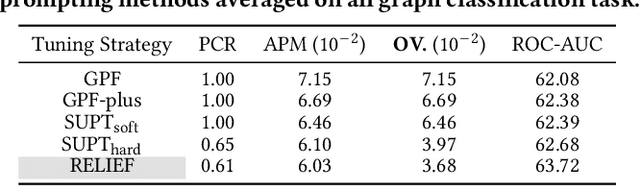
The advent of the "pre-train, prompt" paradigm has recently extended its generalization ability and data efficiency to graph representation learning, following its achievements in Natural Language Processing (NLP). Initial graph prompt tuning approaches tailored specialized prompting functions for Graph Neural Network (GNN) models pre-trained with specific strategies, such as edge prediction, thus limiting their applicability. In contrast, another pioneering line of research has explored universal prompting via adding prompts to the input graph's feature space, thereby removing the reliance on specific pre-training strategies. However, the necessity to add feature prompts to all nodes remains an open question. Motivated by findings from prompt tuning research in the NLP domain, which suggest that highly capable pre-trained models need less conditioning signal to achieve desired behaviors, we advocate for strategically incorporating necessary and lightweight feature prompts to certain graph nodes to enhance downstream task performance. This introduces a combinatorial optimization problem, requiring a policy to decide 1) which nodes to prompt and 2) what specific feature prompts to attach. We then address the problem by framing the prompt incorporation process as a sequential decision-making problem and propose our method, RELIEF, which employs Reinforcement Learning (RL) to optimize it. At each step, the RL agent selects a node (discrete action) and determines the prompt content (continuous action), aiming to maximize cumulative performance gain. Extensive experiments on graph and node-level tasks with various pre-training strategies in few-shot scenarios demonstrate that our RELIEF outperforms fine-tuning and other prompt-based approaches in classification performance and data efficiency.
Boosting Graph Foundation Model from Structural Perspective
Jul 29, 2024Graph foundation models have recently attracted significant attention due to its strong generalizability. Although existing methods resort to language models to learn unified semantic representations across domains, they disregard the unique structural characteristics of graphs from different domains. To address the problem, in this paper, we boost graph foundation model from structural perspective and propose BooG. The model constructs virtual super nodes to unify structural characteristics of graph data from different domains. Specifically, the super nodes fuse the information of anchor nodes and class labels, where each anchor node captures the information of a node or a graph instance to be classified. Instead of using the raw graph structure, we connect super nodes to all nodes within their neighborhood by virtual edges. This new structure allows for effective information aggregation while unifying cross-domain structural characteristics. Additionally, we propose a novel pre-training objective based on contrastive learning, which learns more expressive representations for graph data and generalizes effectively to different domains and downstream tasks. Experimental results on various datasets and tasks demonstrate the superior performance of BooG. We provide our code and data here: https://anonymous.4open.science/r/BooG-EE42/.
Improving Graph Out-of-distribution Generalization on Real-world Data
Jul 14, 2024



Existing methods for graph out-of-distribution (OOD) generalization primarily rely on empirical studies on synthetic datasets. Such approaches tend to overemphasize the causal relationships between invariant sub-graphs and labels, thereby neglecting the non-negligible role of environment in real-world scenarios. In contrast to previous studies that impose rigid independence assumptions on environments and invariant sub-graphs, this paper presents the theorems of environment-label dependency and mutable rationale invariance, where the former characterizes the usefulness of environments in determining graph labels while the latter refers to the mutable importance of graph rationales. Based on analytic investigations, a novel variational inference based method named ``Probability Dependency on Environments and Rationales for OOD Graphs on Real-world Data'' (DEROG) is introduced. To alleviate the adverse effect of unknown prior knowledge on environments and rationales, DEROG utilizes generalized Bayesian inference. Further, DEROG employs an EM-based algorithm for optimization. Finally, extensive experiments on real-world datasets under different distribution shifts are conducted to show the superiority of DEROG. Our code is publicly available at https://anonymous.4open.science/r/DEROG-536B.
Self-supervised Heterogeneous Graph Variational Autoencoders
Nov 14, 2023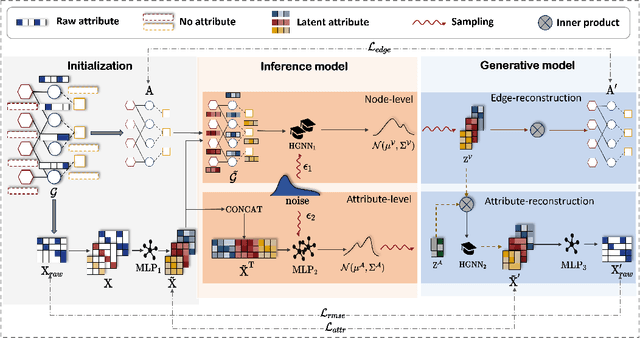
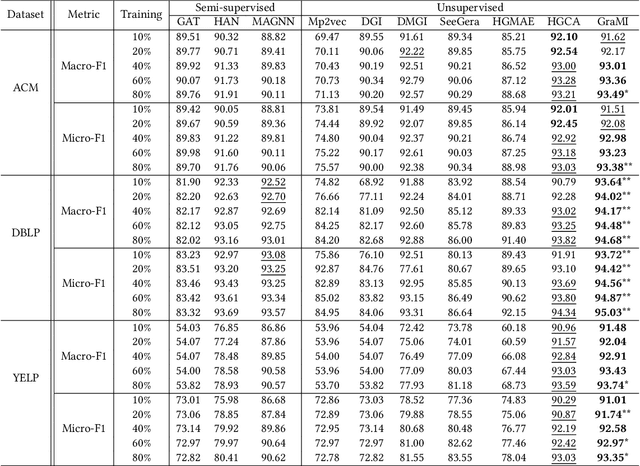
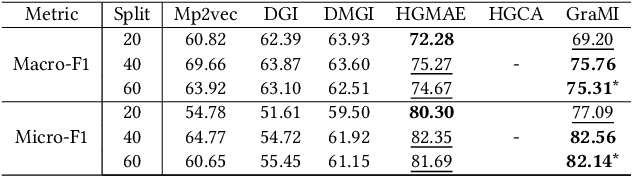
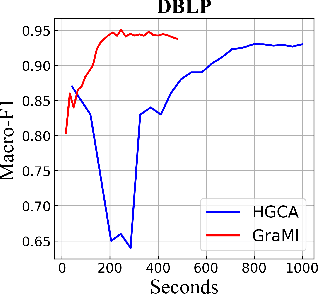
Heterogeneous Information Networks (HINs), which consist of various types of nodes and edges, have recently demonstrated excellent performance in graph mining. However, most existing heterogeneous graph neural networks (HGNNs) ignore the problems of missing attributes, inaccurate attributes and scarce labels for nodes, which limits their expressiveness. In this paper, we propose a generative self-supervised model SHAVA to address these issues simultaneously. Specifically, SHAVA first initializes all the nodes in the graph with a low-dimensional representation matrix. After that, based on the variational graph autoencoder framework, SHAVA learns both node-level and attribute-level embeddings in the encoder, which can provide fine-grained semantic information to construct node attributes. In the decoder, SHAVA reconstructs both links and attributes. Instead of directly reconstructing raw features for attributed nodes, SHAVA generates the initial low-dimensional representation matrix for all the nodes, based on which raw features of attributed nodes are further reconstructed to leverage accurate attributes. In this way, SHAVA can not only complete informative features for non-attributed nodes, but rectify inaccurate ones for attributed nodes. Finally, we conduct extensive experiments to show the superiority of SHAVA in tackling HINs with missing and inaccurate attributes.