 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Graph Foundation Model from Structural Perspective
Jul 29, 2024Graph foundation models have recently attracted significant attention due to its strong generalizability. Although existing methods resort to language models to learn unified semantic representations across domains, they disregard the unique structural characteristics of graphs from different domains. To address the problem, in this paper, we boost graph foundation model from structural perspective and propose BooG. The model constructs virtual super nodes to unify structural characteristics of graph data from different domains. Specifically, the super nodes fuse the information of anchor nodes and class labels, where each anchor node captures the information of a node or a graph instance to be classified. Instead of using the raw graph structure, we connect super nodes to all nodes within their neighborhood by virtual edges. This new structure allows for effective information aggregation while unifying cross-domain structural characteristics. Additionally, we propose a novel pre-training objective based on contrastive learning, which learns more expressive representations for graph data and generalizes effectively to different domains and downstream tasks. Experimental results on various datasets and tasks demonstrate the superior performance of BooG. We provide our code and data here: https://anonymous.4open.science/r/BooG-EE42/.
Self-supervised Heterogeneous Graph Variational Autoencoders
Nov 14, 2023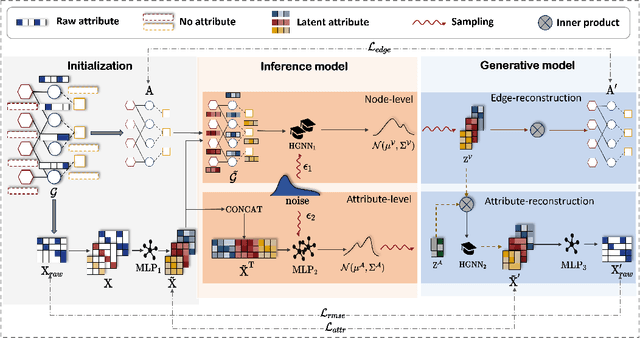
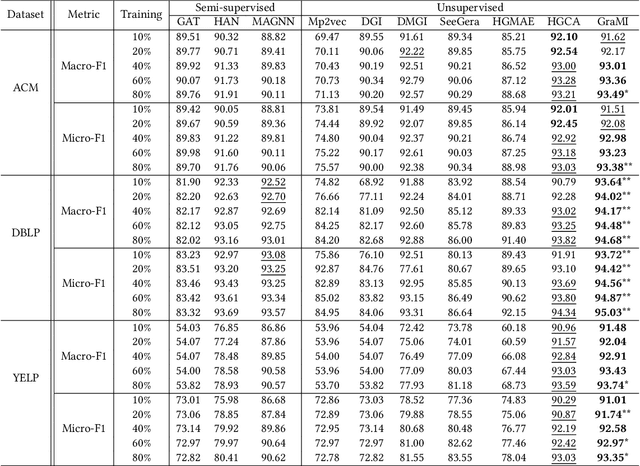
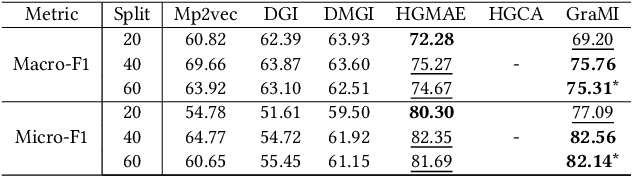
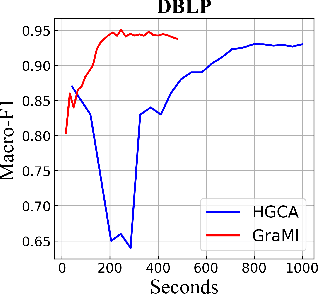
Heterogeneous Information Networks (HINs), which consist of various types of nodes and edges, have recently demonstrated excellent performance in graph mining. However, most existing heterogeneous graph neural networks (HGNNs) ignore the problems of missing attributes, inaccurate attributes and scarce labels for nodes, which limits their expressiveness. In this paper, we propose a generative self-supervised model SHAVA to address these issues simultaneously. Specifically, SHAVA first initializes all the nodes in the graph with a low-dimensional representation matrix. After that, based on the variational graph autoencoder framework, SHAVA learns both node-level and attribute-level embeddings in the encoder, which can provide fine-grained semantic information to construct node attributes. In the decoder, SHAVA reconstructs both links and attributes. Instead of directly reconstructing raw features for attributed nodes, SHAVA generates the initial low-dimensional representation matrix for all the nodes, based on which raw features of attributed nodes are further reconstructed to leverage accurate attributes. In this way, SHAVA can not only complete informative features for non-attributed nodes, but rectify inaccurate ones for attributed nodes. Finally, we conduct extensive experiments to show the superiority of SHAVA in tackling HINs with missing and inaccurate attributes.