 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
May 16, 2025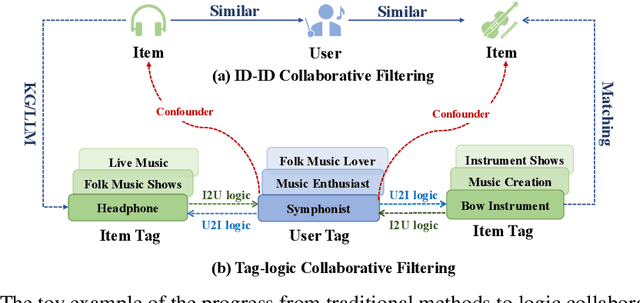
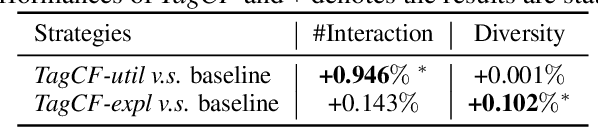
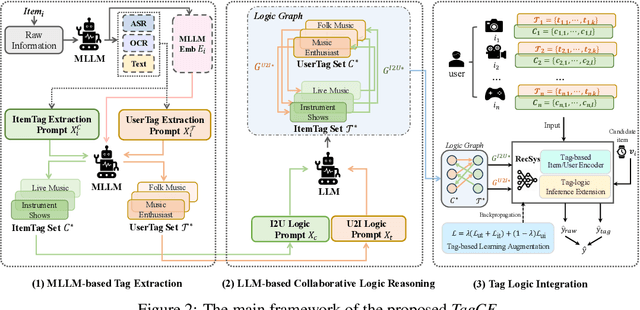
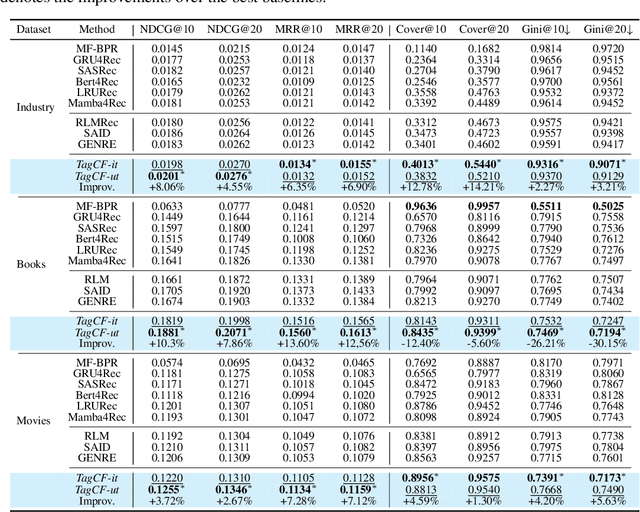
Recommender systems filter contents/items valuable to users by inferring preferences from user features and historical behaviors. Mainstream approaches follow the learning-to-rank paradigm, which focus on discovering and modeling item topics (e.g., categories), and capturing user preferences on these topics based on historical interactions. However, this paradigm often neglects the modeling of user characteristics and their social roles, which are logical confounders influencing the correlated interest and user preference transition. To bridge this gap, we introduce the user role identification task and the behavioral logic modeling task that aim to explicitly model user roles and learn the logical relations between item topics and user social roles. We show that it is possible to explicitly solve these tasks through an efficient integration framework of Large Language Model (LLM) and recommendation systems, for which we propose TagCF. On the one hand, the exploitation of the LLM's world knowledge and logic inference ability produces a virtual logic graph that reveals dynamic and expressive knowledge of users, augmenting the recommendation performance. On the other hand, the user role aligns the user behavioral logic with the observed user feedback, refining our understanding of user behaviors. Additionally, we also show that the extracted user-item logic graph is empirically a general knowledge that can benefit a wide range of recommendation tasks, and conduct experiments on industrial and several public datasets as verification.
A Benchmark and Evaluation for Real-World Out-of-Distribution Detection Using Vision-Language Models
Jan 30, 2025



Out-of-distribution (OOD) detection is a task that detects OOD samples during inference to ensure the safety of deployed models. However, conventional benchmarks have reached performance saturation, making it difficult to compare recent OOD detection methods. To address this challenge, we introduce three novel OOD detection benchmarks that enable a deeper understanding of method characteristics and reflect real-world conditions. First, we present ImageNet-X, designed to evaluate performance under challenging semantic shifts. Second, we propose ImageNet-FS-X for full-spectrum OOD detection, assessing robustness to covariate shifts (feature distribution shifts). Finally, we propose Wilds-FS-X, which extends these evaluations to real-world datasets, offering a more comprehensive testbed. Our experiments reveal that recent CLIP-based OOD detection methods struggle to varying degrees across the three proposed benchmarks, and none of them consistently outperforms the others. We hope the community goes beyond specific benchmarks and includes more challenging conditions reflecting real-world scenarios. The code is https://github.com/hoshi23/OOD-X-Banchmarks.
Global Estimation of Building-Integrated Facade and Rooftop Photovoltaic Potential by Integrating 3D Building Footprint and Spatio-Temporal Datasets
Dec 02, 2024This research tackles the challenges of estimating Building-Integrated Photovoltaics (BIPV) potential across various temporal and spatial scales, accounting for different geographical climates and urban morphology. We introduce a holistic methodology for evaluating BIPV potential, integrating 3D building footprint models with diverse meteorological data sources to account for dynamic shadow effects. The approach enables the assessment of PV potential on facades and rooftops at different levels-individual buildings, urban blocks, and cities globally. Through an analysis of 120 typical cities, we highlight the importance of 3D building forms, cityscape morphology, and geographic positioning in measuring BIPV potential at various levels. In particular, our simulation study reveals that among cities with optimal facade PV performance, the average ratio of facade PV potential to rooftop PV potential is approximately 68.2%. Additionally, approximately 17.5% of the analyzed samples demonstrate even higher facade PV potentials compared to rooftop installations. This finding underscores the strategic value of incorporating facade PV applications into urban sustainable energy systems.
Multiscale spatiotemporal heterogeneity analysis of bike-sharing system's self-loop phenomenon: Evidence from Shanghai
Nov 26, 2024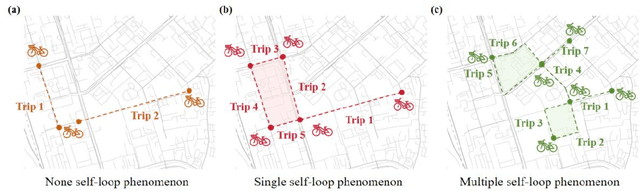
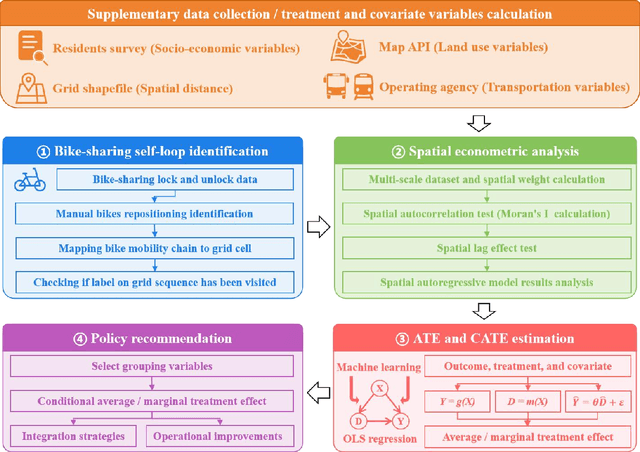

Bike-sharing is an environmentally friendly shared mobility mode, but its self-loop phenomenon, where bikes are returned to the same station after several time usage, significantly impacts equity in accessing its services. Therefore, this study conducts a multiscale analysis with a spatial autoregressive model and double machine learning framework to assess socioeconomic features and geospatial location's impact on the self-loop phenomenon at metro stations and street scales. The results reveal that bike-sharing self-loop intensity exhibits significant spatial lag effect at street scale and is positively associated with residential land use. Marginal treatment effects of residential land use is higher on streets with middle-aged residents, high fixed employment, and low car ownership. The multimodal public transit condition reveals significant positive marginal treatment effects at both scales. To enhance bike-sharing cooperation, we advocate augmenting bicycle availability in areas with high metro usage and low bus coverage, alongside implementing adaptable redistribution strategies.
Generalized Out-of-Distribution Detection and Beyond in Vision Language Model Era: A Survey
Jul 31, 2024



Detecting out-of-distribution (OOD) samples is crucial for ensuring the safety of machine learning systems and has shaped the field of OOD detection. Meanwhile, several other problems are closely related to OOD detection, including anomaly detection (AD), novelty detection (ND), open set recognition (OSR), and outlier detection (OD). To unify these problems, a generalized OOD detection framework was proposed, taxonomically categorizing these five problems. However, Vision Language Models (VLMs) such as CLIP have significantly changed the paradigm and blurred the boundaries between these fields, again confusing researchers. In this survey, we first present a generalized OOD detection v2, encapsulating the evolution of AD, ND, OSR, OOD detection, and OD in the VLM era. Our framework reveals that, with some field inactivity and integration, the demanding challenges have become OOD detection and AD. In addition, we also highlight the significant shift in the definition, problem settings, and benchmarks; we thus feature a comprehensive review of the methodology for OOD detection, including the discussion over other related tasks to clarify their relationship to OOD detection. Finally, we explore the advancements in the emerging Large Vision Language Model (LVLM) era, such as GPT-4V. We conclude this survey with open challenges and future directions.
Chronologically Accurate Retrieval for Temporal Grounding of Motion-Language Models
Jul 22, 2024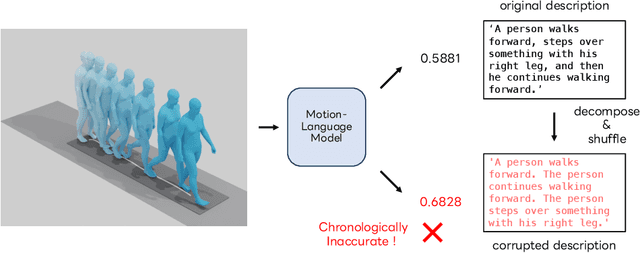
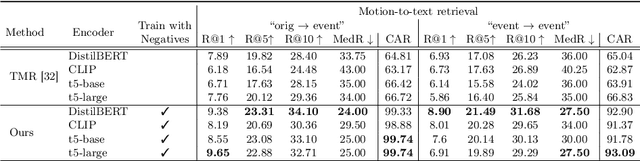

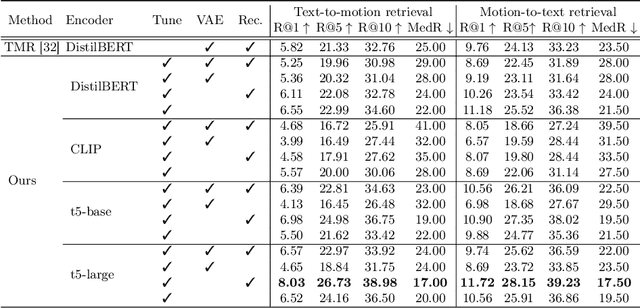
With the release of large-scale motion datasets with textual annotations, the task of establishing a robust latent space for language and 3D human motion has recently witnessed a surge of interest. Methods have been proposed to convert human motion and texts into features to achieve accurate correspondence between them. Despite these efforts to align language and motion representations, we claim that the temporal element is often overlooked, especially for compound actions, resulting in chronological inaccuracies. To shed light on the temporal alignment in motion-language latent spaces, we propose Chronologically Accurate Retrieval (CAR) to evaluate the chronological understanding of the models. We decompose textual descriptions into events, and prepare negative text samples by shuffling the order of events in compound action descriptions. We then design a simple task for motion-language models to retrieve the more likely text from the ground truth and its chronologically shuffled version. CAR reveals many cases where current motion-language models fail to distinguish the event chronology of human motion, despite their impressive performance in terms of conventional evaluation metrics. To achieve better temporal alignment between text and motion, we further propose to use these texts with shuffled sequence of events as negative samples during training to reinforce the motion-language models. We conduct experiments on text-motion retrieval and text-to-motion generation using the reinforced motion-language models, which demonstrate improved performance over conventional approaches, indicating the necessity to consider temporal elements in motion-language alignment.
Exploring Vision Transformers for 3D Human Motion-Language Models with Motion Patches
May 08, 2024



To build a cross-modal latent space between 3D human motion and language, acquiring large-scale and high-quality human motion data is crucial. However, unlike the abundance of image data, the scarcity of motion data has limited the performance of existing motion-language models. To counter this, we introduce "motion patches", a new representation of motion sequences, and propose using Vision Transformers (ViT) as motion encoders via transfer learning, aiming to extract useful knowledge from the image domain and apply it to the motion domain. These motion patches, created by dividing and sorting skeleton joints based on body parts in motion sequences, are robust to varying skeleton structures, and can be regarded as color image patches in ViT. We find that transfer learning with pre-trained weights of ViT obtained through training with 2D image data can boost the performance of motion analysis, presenting a promising direction for addressing the issue of limited motion data. Our extensive experiments show that the proposed motion patches, used jointly with ViT, achieve state-of-the-art performance in the benchmarks of text-to-motion retrieval, and other novel challenging tasks, such as cross-skeleton recognition, zero-shot motion classification, and human interaction recognition, which are currently impeded by the lack of data.
Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models
Mar 29, 2024This paper introduces a novel and significant challenge for Vision Language Models (VLMs), termed Unsolvable Problem Detection (UPD). UPD examines the VLM's ability to withhold answers when faced with unsolvable problems in the context of Visual Question Answering (VQA) tasks. UPD encompasses three distinct settings: Absent Answer Detection (AAD), Incompatible Answer Set Detection (IASD), and Incompatible Visual Question Detection (IVQD). To deeply investigate the UPD problem, extensive experiments indicate that most VLMs, including GPT-4V and LLaVA-Next-34B, struggle with our benchmarks to varying extents, highlighting significant room for the improvements. To address UPD, we explore both training-free and training-based solutions, offering new insights into their effectiveness and limitations. We hope our insights, together with future efforts within the proposed UPD settings, will enhance the broader understanding and development of more practical and reliable VLMs.
Can Pre-trained Networks Detect Familiar Out-of-Distribution Data?
Oct 12, 2023



Out-of-distribution (OOD) detection is critical for safety-sensitive machine learning applications and has been extensively studied, yielding a plethora of methods developed in the literature. However, most studies for OOD detection did not use pre-trained models and trained a backbone from scratch. In recent years, transferring knowledge from large pre-trained models to downstream tasks by lightweight tuning has become mainstream for training in-distribution (ID) classifiers. To bridge the gap between the practice of OOD detection and current classifiers, the unique and crucial problem is that the samples whose information networks know often come as OOD input. We consider that such data may significantly affect the performance of large pre-trained networks because the discriminability of these OOD data depends on the pre-training algorithm. Here, we define such OOD data as PT-OOD (Pre-Trained OOD) data. In this paper, we aim to reveal the effect of PT-OOD on the OOD detection performance of pre-trained networks from the perspective of pre-training algorithms. To achieve this, we explore the PT-OOD detection performance of supervised and self-supervised pre-training algorithms with linear-probing tuning, the most common efficient tuning method. Through our experiments and analysis, we find that the low linear separability of PT-OOD in the feature space heavily degrades the PT-OOD detection performance, and self-supervised models are more vulnerable to PT-OOD than supervised pre-trained models, even with state-of-the-art detection methods. To solve this vulnerability, we further propose a unique solution to large-scale pre-trained models: Leveraging powerful instance-by-instance discriminative representations of pre-trained models and detecting OOD in the feature space independent of the ID decision boundaries. The code will be available via https://github.com/AtsuMiyai/PT-OOD.
CPR-Coach: Recognizing Composite Error Actions based on Single-class Training
Sep 21, 2023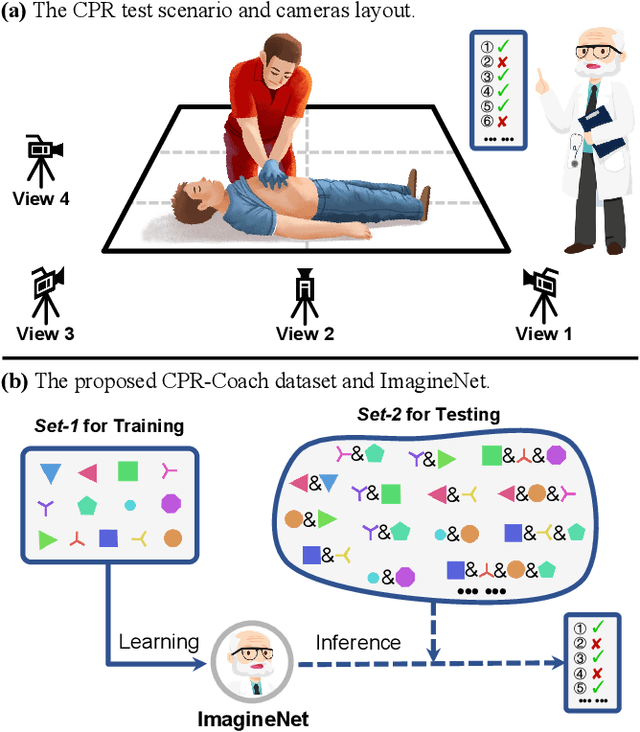
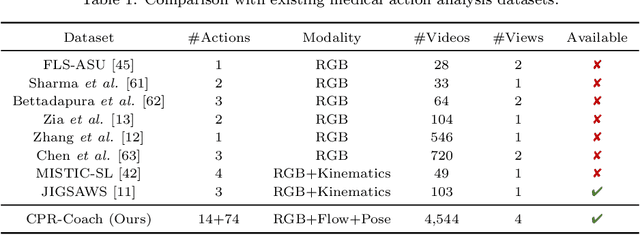

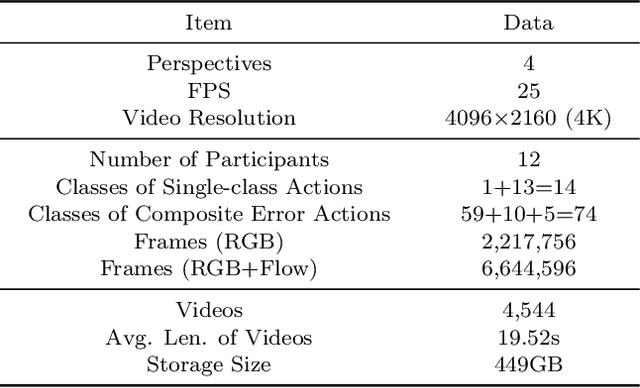
The fine-grained medical action analysis task has received considerable attention from pattern recognition communities recently, but it faces the problems of data and algorithm shortage. Cardiopulmonary Resuscitation (CPR) is an essential skill in emergency treatment. Currently, the assessment of CPR skills mainly depends on dummies and trainers, leading to high training costs and low efficiency. For the first time, this paper constructs a vision-based system to complete error action recognition and skill assessment in CPR. Specifically, we define 13 types of single-error actions and 74 types of composite error actions during external cardiac compression and then develop a video dataset named CPR-Coach. By taking the CPR-Coach as a benchmark, this paper thoroughly investigates and compares the performance of existing action recognition models based on different data modalities. To solve the unavoidable Single-class Training & Multi-class Testing problem, we propose a humancognition-inspired framework named ImagineNet to improve the model's multierror recognition performance under restricted supervision. Extensive experiments verify the effectiveness of the framework. We hope this work could advance research toward fine-grained medical action analysis and skill assessment. The CPR-Coach dataset and the code of ImagineNet are publicly available on Github.