 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjFlow: Projection Sampling with Flow Matching for Zero-Shot Exact Spatial Motion Control
Feb 26, 2026Generating human motion with precise spatial control is a challenging problem. Existing approaches often require task-specific training or slow optimization, and enforcing hard constraints frequently disrupts motion naturalness. Building on the observation that many animation tasks can be formulated as a linear inverse problem, we introduce ProjFlow, a training-free sampler that achieves zero-shot, exact satisfaction of linear spatial constraints while preserving motion realism. Our key advance is a novel kinematics-aware metric that encodes skeletal topology. This metric allows the sampler to enforce hard constraints by distributing corrections coherently across the entire skeleton, avoiding the unnatural artifacts of naive projection. Furthermore, for sparse inputs, such as filling in long gaps between a few keyframes, we introduce a time-varying formulation using pseudo-observations that fade during sampling. Extensive experiments on representative applications, motion inpainting, and 2D-to-3D lifting, demonstrate that ProjFlow achieves exact constraint satisfaction and matches or improves realism over zero-shot baselines, while remaining competitive with training-based controllers.
Causal Motion Diffusion Models for Autoregressive Motion Generation
Feb 26, 2026Recent advances in motion diffusion models have substantially improved the realism of human motion synthesis. However, existing approaches either rely on full-sequence diffusion models with bidirectional generation, which limits temporal causality and real-time applicability, or autoregressive models that suffer from instability and cumulative errors. In this work, we present Causal Motion Diffusion Models (CMDM), a unified framework for autoregressive motion generation based on a causal diffusion transformer that operates in a semantically aligned latent space. CMDM builds upon a Motion-Language-Aligned Causal VAE (MAC-VAE), which encodes motion sequences into temporally causal latent representations. On top of this latent representation, an autoregressive diffusion transformer is trained using causal diffusion forcing to perform temporally ordered denoising across motion frames. To achieve fast inference, we introduce a frame-wise sampling schedule with causal uncertainty, where each subsequent frame is predicted from partially denoised previous frames. The resulting framework supports high-quality text-to-motion generation, streaming synthesis, and long-horizon motion generation at interactive rates. Experiments on HumanML3D and SnapMoGen demonstrate that CMDM outperforms existing diffusion and autoregressive models in both semantic fidelity and temporal smoothness, while substantially reducing inference latency.
Chronologically Accurate Retrieval for Temporal Grounding of Motion-Language Models
Jul 22, 2024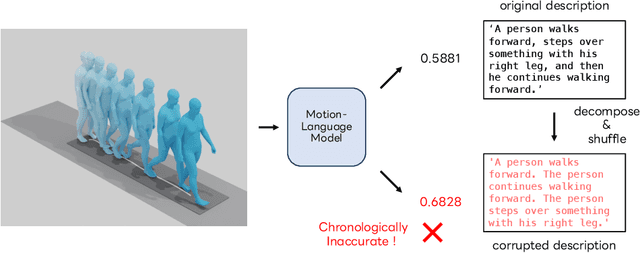
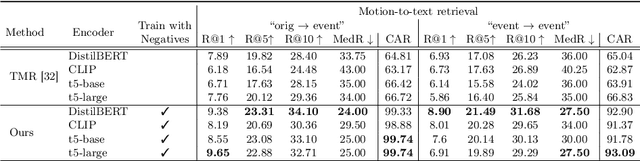

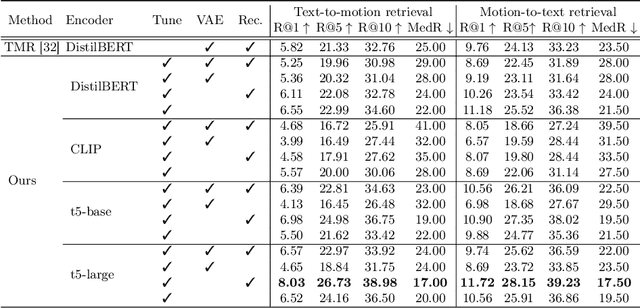
With the release of large-scale motion datasets with textual annotations, the task of establishing a robust latent space for language and 3D human motion has recently witnessed a surge of interest. Methods have been proposed to convert human motion and texts into features to achieve accurate correspondence between them. Despite these efforts to align language and motion representations, we claim that the temporal element is often overlooked, especially for compound actions, resulting in chronological inaccuracies. To shed light on the temporal alignment in motion-language latent spaces, we propose Chronologically Accurate Retrieval (CAR) to evaluate the chronological understanding of the models. We decompose textual descriptions into events, and prepare negative text samples by shuffling the order of events in compound action descriptions. We then design a simple task for motion-language models to retrieve the more likely text from the ground truth and its chronologically shuffled version. CAR reveals many cases where current motion-language models fail to distinguish the event chronology of human motion, despite their impressive performance in terms of conventional evaluation metrics. To achieve better temporal alignment between text and motion, we further propose to use these texts with shuffled sequence of events as negative samples during training to reinforce the motion-language models. We conduct experiments on text-motion retrieval and text-to-motion generation using the reinforced motion-language models, which demonstrate improved performance over conventional approaches, indicating the necessity to consider temporal elements in motion-language alignment.
Exploring Vision Transformers for 3D Human Motion-Language Models with Motion Patches
May 08, 2024



To build a cross-modal latent space between 3D human motion and language, acquiring large-scale and high-quality human motion data is crucial. However, unlike the abundance of image data, the scarcity of motion data has limited the performance of existing motion-language models. To counter this, we introduce "motion patches", a new representation of motion sequences, and propose using Vision Transformers (ViT) as motion encoders via transfer learning, aiming to extract useful knowledge from the image domain and apply it to the motion domain. These motion patches, created by dividing and sorting skeleton joints based on body parts in motion sequences, are robust to varying skeleton structures, and can be regarded as color image patches in ViT. We find that transfer learning with pre-trained weights of ViT obtained through training with 2D image data can boost the performance of motion analysis, presenting a promising direction for addressing the issue of limited motion data. Our extensive experiments show that the proposed motion patches, used jointly with ViT, achieve state-of-the-art performance in the benchmarks of text-to-motion retrieval, and other novel challenging tasks, such as cross-skeleton recognition, zero-shot motion classification, and human interaction recognition, which are currently impeded by the lack of data.
Canonical and Compact Point Cloud Representation for Shape Classification
Sep 13, 2018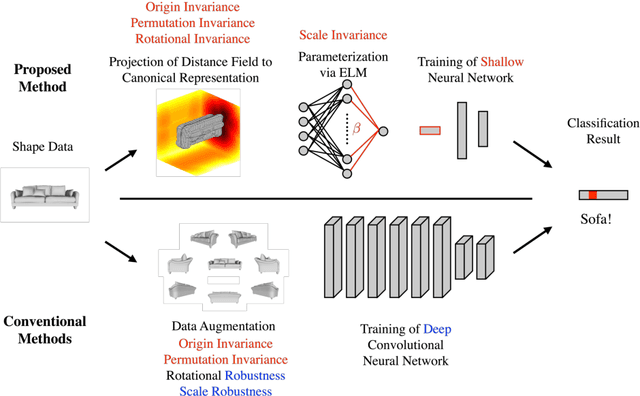
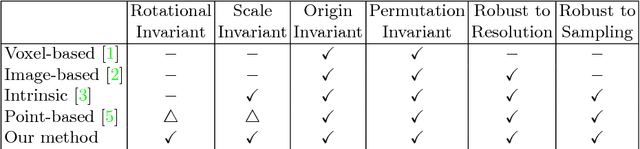
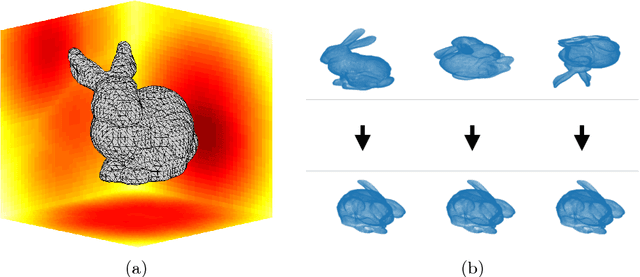
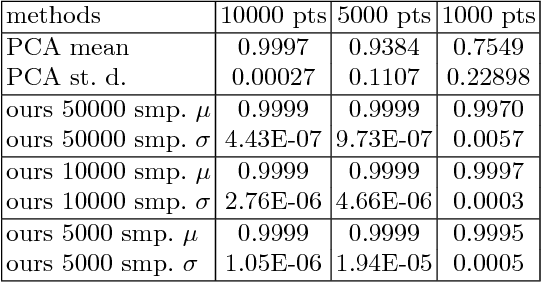
We present a novel compact point cloud representation that is inherently invariant to scale, coordinate change and point permutation. The key idea is to parametrize a distance field around an individual shape into a unique, canonical, and compact vector in an unsupervised manner. We firstly project a distance field to a $4$D canonical space using singular value decomposition. We then train a neural network for each instance to non-linearly embed its distance field into network parameters. We employ a bias-free Extreme Learning Machine (ELM) with ReLU activation units, which has scale-factor commutative property between layers. We demonstrate the descriptiveness of the instance-wise, shape-embedded network parameters by using them to classify shapes in $3$D datasets. Our learning-based representation requires minimal augmentation and simple neural networks, where previous approaches demand numerous representations to handle coordinate change and point permutation.