 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePULSE: Practical Evaluation Scenarios for Large Multimodal Model Unlearning
Jul 02, 2025In recent years, unlearning techniques, which are methods for inducing a model to "forget" previously learned information, have attracted attention as a way to address privacy and copyright concerns in large language models (LLMs) and large multimodal models (LMMs). While several unlearning benchmarks have been established for LLMs, a practical evaluation framework for unlearning in LMMs has been less explored. Specifically, existing unlearning benchmark for LMMs considers only scenarios in which the model is required to unlearn fine-tuned knowledge through a single unlearning operation. In this study, we introduce PULSE protocol for realistic unlearning scenarios for LMMs by introducing two critical perspectives: (i) Pre-trained knowledge Unlearning for analyzing the effect across different knowledge acquisition phases and (ii) Long-term Sustainability Evaluation to address sequential requests. We then evaluate existing unlearning methods along these dimensions. Our results reveal that, although some techniques can successfully unlearn knowledge acquired through fine-tuning, they struggle to eliminate information learned during pre-training. Moreover, methods that effectively unlearn a batch of target data in a single operation exhibit substantial performance degradation when the same data are split and unlearned sequentially.
A Benchmark and Evaluation for Real-World Out-of-Distribution Detection Using Vision-Language Models
Jan 30, 2025



Out-of-distribution (OOD) detection is a task that detects OOD samples during inference to ensure the safety of deployed models. However, conventional benchmarks have reached performance saturation, making it difficult to compare recent OOD detection methods. To address this challenge, we introduce three novel OOD detection benchmarks that enable a deeper understanding of method characteristics and reflect real-world conditions. First, we present ImageNet-X, designed to evaluate performance under challenging semantic shifts. Second, we propose ImageNet-FS-X for full-spectrum OOD detection, assessing robustness to covariate shifts (feature distribution shifts). Finally, we propose Wilds-FS-X, which extends these evaluations to real-world datasets, offering a more comprehensive testbed. Our experiments reveal that recent CLIP-based OOD detection methods struggle to varying degrees across the three proposed benchmarks, and none of them consistently outperforms the others. We hope the community goes beyond specific benchmarks and includes more challenging conditions reflecting real-world scenarios. The code is https://github.com/hoshi23/OOD-X-Banchmarks.
Acoustic-based 3D Human Pose Estimation Robust to Human Position
Nov 08, 2024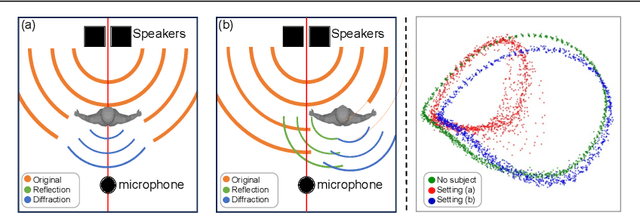
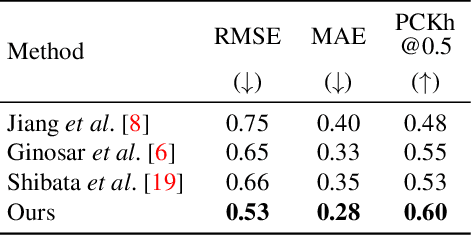
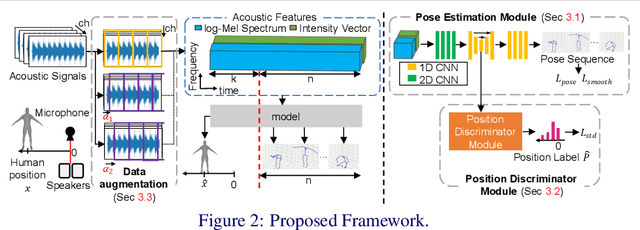
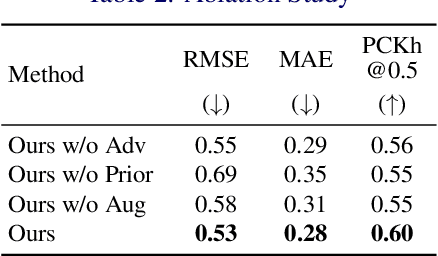
This paper explores the problem of 3D human pose estimation from only low-level acoustic signals. The existing active acoustic sensing-based approach for 3D human pose estimation implicitly assumes that the target user is positioned along a line between loudspeakers and a microphone. Because reflection and diffraction of sound by the human body cause subtle acoustic signal changes compared to sound obstruction, the existing model degrades its accuracy significantly when subjects deviate from this line, limiting its practicality in real-world scenarios. To overcome this limitation, we propose a novel method composed of a position discriminator and reverberation-resistant model. The former predicts the standing positions of subjects and applies adversarial learning to extract subject position-invariant features. The latter utilizes acoustic signals before the estimation target time as references to enhance robustness against the variations in sound arrival times due to diffraction and reflection. We construct an acoustic pose estimation dataset that covers diverse human locations and demonstrate through experiments that our proposed method outperforms existing approaches.
Black-Box Forgetting
Nov 01, 2024Large-scale pre-trained models (PTMs) provide remarkable zero-shot classification capability covering a wide variety of object classes. However, practical applications do not always require the classification of all kinds of objects, and leaving the model capable of recognizing unnecessary classes not only degrades overall accuracy but also leads to operational disadvantages. To mitigate this issue, we explore the selective forgetting problem for PTMs, where the task is to make the model unable to recognize only the specified classes while maintaining accuracy for the rest. All the existing methods assume "white-box" settings, where model information such as architectures, parameters, and gradients is available for training. However, PTMs are often "black-box," where information on such models is unavailable for commercial reasons or social responsibilities. In this paper, we address a novel problem of selective forgetting for black-box models, named Black-Box Forgetting, and propose an approach to the problem. Given that information on the model is unavailable, we optimize the input prompt to decrease the accuracy of specified classes through derivative-free optimization. To avoid difficult high-dimensional optimization while ensuring high forgetting performance, we propose Latent Context Sharing, which introduces common low-dimensional latent components among multiple tokens for the prompt. Experiments on four standard benchmark datasets demonstrate the superiority of our method with reasonable baselines. The code is available at https://github.com/yusukekwn/Black-Box-Forgetting.
Estimating Indoor Scene Depth Maps from Ultrasonic Echoes
Sep 08, 2024
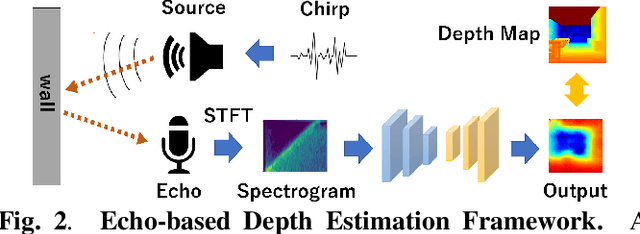
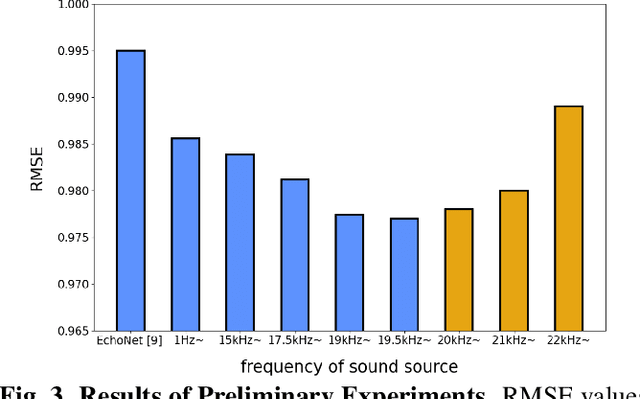
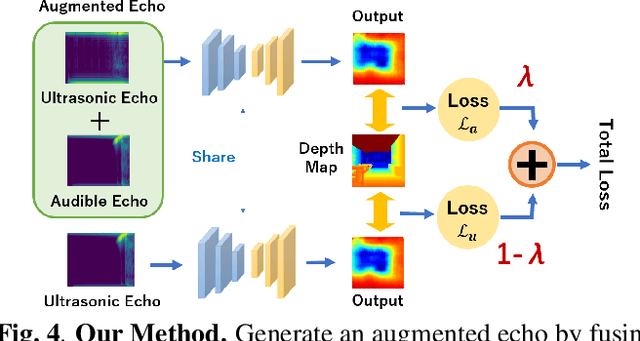
Measuring 3D geometric structures of indoor scenes requires dedicated depth sensors, which are not always available. Echo-based depth estimation has recently been studied as a promising alternative solution. All previous studies have assumed the use of echoes in the audible range. However, one major problem is that audible echoes cannot be used in quiet spaces or other situations where producing audible sounds is prohibited. In this paper, we consider echo-based depth estimation using inaudible ultrasonic echoes. While ultrasonic waves provide high measurement accuracy in theory, the actual depth estimation accuracy when ultrasonic echoes are used has remained unclear, due to its disadvantage of being sensitive to noise and susceptible to attenuation. We first investigate the depth estimation accuracy when the frequency of the sound source is restricted to the high-frequency band, and found that the accuracy decreased when the frequency was limited to ultrasonic ranges. Based on this observation, we propose a novel deep learning method to improve the accuracy of ultrasonic echo-based depth estimation by using audible echoes as auxiliary data only during training. Experimental results with a public dataset demonstrate that our method improves the estimation accuracy.
Eetimating Indoor Scene Depth Maps from Ultrasonic Echoes
Sep 05, 2024Measuring 3D geometric structures of indoor scenes requires dedicated depth sensors, which are not always available. Echo-based depth estimation has recently been studied as a promising alternative solution. All previous studies have assumed the use of echoes in the audible range. However, one major problem is that audible echoes cannot be used in quiet spaces or other situations where producing audible sounds is prohibited. In this paper, we consider echo-based depth estimation using inaudible ultrasonic echoes. While ultrasonic waves provide high measurement accuracy in theory, the actual depth estimation accuracy when ultrasonic echoes are used has remained unclear, due to its disadvantage of being sensitive to noise and susceptible to attenuation. We first investigate the depth estimation accuracy when the frequency of the sound source is restricted to the high-frequency band, and found that the accuracy decreased when the frequency was limited to ultrasonic ranges. Based on this observation, we propose a novel deep learning method to improve the accuracy of ultrasonic echo-based depth estimation by using audible echoes as auxiliary data only during training. Experimental results with a public dataset demonstrate that our method improves the estimation accuracy.
Generalized Out-of-Distribution Detection and Beyond in Vision Language Model Era: A Survey
Jul 31, 2024



Detecting out-of-distribution (OOD) samples is crucial for ensuring the safety of machine learning systems and has shaped the field of OOD detection. Meanwhile, several other problems are closely related to OOD detection, including anomaly detection (AD), novelty detection (ND), open set recognition (OSR), and outlier detection (OD). To unify these problems, a generalized OOD detection framework was proposed, taxonomically categorizing these five problems. However, Vision Language Models (VLMs) such as CLIP have significantly changed the paradigm and blurred the boundaries between these fields, again confusing researchers. In this survey, we first present a generalized OOD detection v2, encapsulating the evolution of AD, ND, OSR, OOD detection, and OD in the VLM era. Our framework reveals that, with some field inactivity and integration, the demanding challenges have become OOD detection and AD. In addition, we also highlight the significant shift in the definition, problem settings, and benchmarks; we thus feature a comprehensive review of the methodology for OOD detection, including the discussion over other related tasks to clarify their relationship to OOD detection. Finally, we explore the advancements in the emerging Large Vision Language Model (LVLM) era, such as GPT-4V. We conclude this survey with open challenges and future directions.
Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models
Mar 29, 2024This paper introduces a novel and significant challenge for Vision Language Models (VLMs), termed Unsolvable Problem Detection (UPD). UPD examines the VLM's ability to withhold answers when faced with unsolvable problems in the context of Visual Question Answering (VQA) tasks. UPD encompasses three distinct settings: Absent Answer Detection (AAD), Incompatible Answer Set Detection (IASD), and Incompatible Visual Question Detection (IVQD). To deeply investigate the UPD problem, extensive experiments indicate that most VLMs, including GPT-4V and LLaVA-Next-34B, struggle with our benchmarks to varying extents, highlighting significant room for the improvements. To address UPD, we explore both training-free and training-based solutions, offering new insights into their effectiveness and limitations. We hope our insights, together with future efforts within the proposed UPD settings, will enhance the broader understanding and development of more practical and reliable VLMs.
Can Pre-trained Networks Detect Familiar Out-of-Distribution Data?
Oct 12, 2023



Out-of-distribution (OOD) detection is critical for safety-sensitive machine learning applications and has been extensively studied, yielding a plethora of methods developed in the literature. However, most studies for OOD detection did not use pre-trained models and trained a backbone from scratch. In recent years, transferring knowledge from large pre-trained models to downstream tasks by lightweight tuning has become mainstream for training in-distribution (ID) classifiers. To bridge the gap between the practice of OOD detection and current classifiers, the unique and crucial problem is that the samples whose information networks know often come as OOD input. We consider that such data may significantly affect the performance of large pre-trained networks because the discriminability of these OOD data depends on the pre-training algorithm. Here, we define such OOD data as PT-OOD (Pre-Trained OOD) data. In this paper, we aim to reveal the effect of PT-OOD on the OOD detection performance of pre-trained networks from the perspective of pre-training algorithms. To achieve this, we explore the PT-OOD detection performance of supervised and self-supervised pre-training algorithms with linear-probing tuning, the most common efficient tuning method. Through our experiments and analysis, we find that the low linear separability of PT-OOD in the feature space heavily degrades the PT-OOD detection performance, and self-supervised models are more vulnerable to PT-OOD than supervised pre-trained models, even with state-of-the-art detection methods. To solve this vulnerability, we further propose a unique solution to large-scale pre-trained models: Leveraging powerful instance-by-instance discriminative representations of pre-trained models and detecting OOD in the feature space independent of the ID decision boundaries. The code will be available via https://github.com/AtsuMiyai/PT-OOD.
Open-Set Domain Adaptation with Visual-Language Foundation Models
Jul 30, 2023Unsupervised domain adaptation (UDA) has proven to be very effective in transferring knowledge obtained from a source domain with labeled data to a target domain with unlabeled data. Owing to the lack of labeled data in the target domain and the possible presence of unknown classes, open-set domain adaptation (ODA) has emerged as a potential solution to identify these classes during the training phase. Although existing ODA approaches aim to solve the distribution shifts between the source and target domains, most methods fine-tuned ImageNet pre-trained models on the source domain with the adaptation on the target domain. Recent visual-language foundation models (VLFM), such as Contrastive Language-Image Pre-Training (CLIP), are robust to many distribution shifts and, therefore, should substantially improve the performance of ODA. In this work, we explore generic ways to adopt CLIP, a popular VLFM, for ODA. We investigate the performance of zero-shot prediction using CLIP, and then propose an entropy optimization strategy to assist the ODA models with the outputs of CLIP. The proposed approach achieves state-of-the-art results on various benchmarks, demonstrating its effectiveness in addressing the ODA problem.