 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D Reconstruction from Sparse Dynamic Cameras
Jun 03, 2026Although dynamic 3D (i.e., 4D) reconstruction from a monocular dynamic camera has recently advanced, it remains fundamentally limited by depth ambiguity. In this paper, we focus on an alternative practical way, i.e., sparse dynamic camera setup, where a handful of independently moving cameras capture the same subjects. While keeping capture costs low, this setup introduces multi-view constraints and remains practical for real-world video production such as sports, concerts, and TV shows. Despite its potential, our experiments show that naive extensions of existing monocular or dense-fixed camera-based methods are insufficient since they fail to resolve the complex spatiotemporal inconsistencies across views and time. To fill this gap, we propose a simple yet effective 3D track initialization method designed to ensure spatiotemporal consistency by integrating inter-camera feature matching with intra-camera point tracking. Additionally, we incorporate a noise-robust depth-ordering regularization loss and a spatiotemporally diverse batch sampling strategy to enhance optimization stability and cross-view generalization. Furthermore, to address the lack of standardized benchmarks for this task, we introduce LetCamsGo, a new real-world video dataset with 5 sequences across 4 diverse environments, recorded by three independently moving cameras and one fixed camera. Comprehensive benchmarking on LetCamsGo demonstrated that our proposed framework improves 4D reconstruction quality in dynamic regions compared with baselines, paving the way for a low-cost 4D reconstruction paradigm in the wild.
Reference-Free Image Quality Assessment for Virtual Try-On via Human Feedback
Mar 13, 2026Given a person image and a garment image, image-based Virtual Try-ON (VTON) synthesizes a try-on image of the person wearing the target garment. As VTON systems become increasingly important in practical applications such as fashion e-commerce, reliable evaluation of their outputs has emerged as a critical challenge. In real-world scenarios, ground-truth images of the same person wearing the target garment are typically unavailable, making reference-based evaluation impractical. Moreover, widely used distribution-level metrics such as Fréchet Inception Distance and Kernel Inception Distance measure dataset-level similarity and fail to reflect the perceptual quality of individual generated images. To address these limitations, we propose Image Quality Assessment for Virtual Try-On (VTON-IQA), a reference-free framework for human-aligned, image-level quality assessment without requiring ground-truth images. To model human perceptual judgments, we construct VTON-QBench, a large-scale human-annotated benchmark comprising 62,688 try-on images generated by 14 representative VTON models and 431,800 quality annotations collected from 13,838 qualified annotators. To the best of our knowledge, this is the largest dataset to date for human subjective evaluation in virtual try-on. Evaluating virtual try-on quality requires verifying both garment fidelity and the preservation of person-specific details. To explicitly model such interactions, we introduce an Interleaved Cross-Attention module that extends standard transformer blocks by inserting a cross-attention layer between self-attention and MLP in the latter blocks. Extensive experiments show that VTON-IQA achieves reliable human-aligned image-level quality prediction. Moreover, we conduct a comprehensive benchmark evaluation of 14 representative VTON models using VTON-IQA.
Learning to Assist: Physics-Grounded Human-Human Control via Multi-Agent Reinforcement Learning
Mar 11, 2026Humanoid robotics has strong potential to transform daily service and caregiving applications. Although recent advances in general motion tracking within physics engines (GMT) have enabled virtual characters and humanoid robots to reproduce a broad range of human motions, these behaviors are primarily limited to contact-less social interactions or isolated movements. Assistive scenarios, by contrast, require continuous awareness of a human partner and rapid adaptation to their evolving posture and dynamics. In this paper, we formulate the imitation of closely interacting, force-exchanging human-human motion sequences as a multi-agent reinforcement learning problem. We jointly train partner-aware policies for both the supporter (assistant) agent and the recipient agent in a physics simulator to track assistive motion references. To make this problem tractable, we introduce a partner policies initialization scheme that transfers priors from single-human motion-tracking controllers, greatly improving exploration. We further propose dynamic reference retargeting and contact-promoting reward, which adapt the assistant's reference motion to the recipient's real-time pose and encourage physically meaningful support. We show that AssistMimic is the first method capable of successfully tracking assistive interaction motions on established benchmarks, demonstrating the benefits of a multi-agent RL formulation for physically grounded and socially aware humanoid control.
Image-based Joint-level Detection for Inflammation in Rheumatoid Arthritis from Small and Imbalanced Data
Feb 16, 2026Rheumatoid arthritis (RA) is an autoimmune disease characterized by systemic joint inflammation. Early diagnosis and tight follow-up are essential to the management of RA, as ongoing inflammation can cause irreversible joint damage. The detection of arthritis is important for diagnosis and assessment of disease activity; however, it often takes a long time for patients to receive appropriate specialist care. Therefore, there is a strong need to develop systems that can detect joint inflammation easily using RGB images captured at home. Consequently, we tackle the task of RA inflammation detection from RGB hand images. This task is highly challenging due to general issues in medical imaging, such as the scarcity of positive samples, data imbalance, and the inherent difficulty of the task itself. However, to the best of our knowledge, no existing work has explicitly addressed these challenges in RGB-based RA inflammation detection. This paper quantitatively demonstrates the difficulty of visually detecting inflammation by constructing a dedicated dataset, and we propose a inflammation detection framework with global local encoder that combines self-supervised pretraining on large-scale healthy hand images with imbalance-aware training to detect RA-related joint inflammation from RGB hand images. Our experiments demonstrated that the proposed approach improves F1-score by 0.2 points and Gmean by 0.25 points compared with the baseline model.
Geometric-Photometric Event-based 3D Gaussian Ray Tracing
Dec 21, 2025Event cameras offer a high temporal resolution over traditional frame-based cameras, which makes them suitable for motion and structure estimation. However, it has been unclear how event-based 3D Gaussian Splatting (3DGS) approaches could leverage fine-grained temporal information of sparse events. This work proposes a framework to address the trade-off between accuracy and temporal resolution in event-based 3DGS. Our key idea is to decouple the rendering into two branches: event-by-event geometry (depth) rendering and snapshot-based radiance (intensity) rendering, by using ray-tracing and the image of warped events. The extensive evaluation shows that our method achieves state-of-the-art performance on the real-world datasets and competitive performance on the synthetic dataset. Also, the proposed method works without prior information (e.g., pretrained image reconstruction models) or COLMAP-based initialization, is more flexible in the event selection number, and achieves sharp reconstruction on scene edges with fast training time. We hope that this work deepens our understanding of the sparse nature of events for 3D reconstruction. The code will be released.
Language-Guided Contrastive Audio-Visual Masked Autoencoder with Automatically Generated Audio-Visual-Text Triplets from Videos
Jul 16, 2025
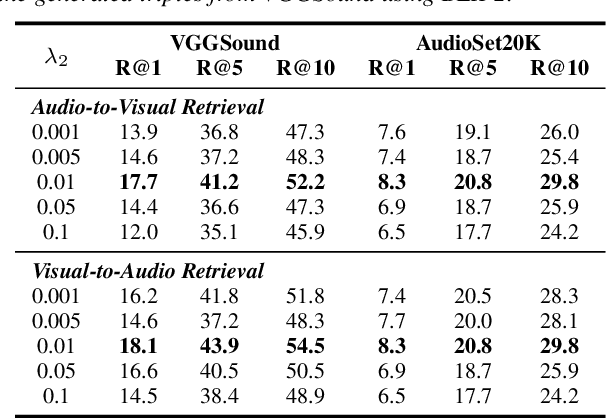
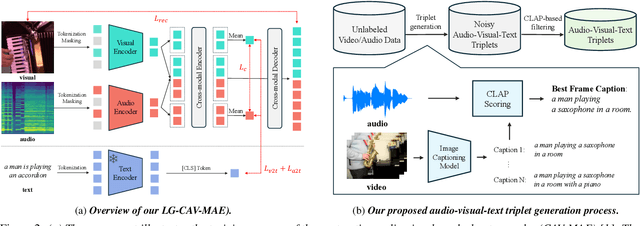

In this paper, we propose Language-Guided Contrastive Audio-Visual Masked Autoencoders (LG-CAV-MAE) to improve audio-visual representation learning. LG-CAV-MAE integrates a pretrained text encoder into contrastive audio-visual masked autoencoders, enabling the model to learn across audio, visual and text modalities. To train LG-CAV-MAE, we introduce an automatic method to generate audio-visual-text triplets from unlabeled videos. We first generate frame-level captions using an image captioning model and then apply CLAP-based filtering to ensure strong alignment between audio and captions. This approach yields high-quality audio-visual-text triplets without requiring manual annotations. We evaluate LG-CAV-MAE on audio-visual retrieval tasks, as well as an audio-visual classification task. Our method significantly outperforms existing approaches, achieving up to a 5.6% improvement in recall@10 for retrieval tasks and a 3.2% improvement for the classification task.
Iterative Event-based Motion Segmentation by Variational Contrast Maximization
Apr 25, 2025Event cameras provide rich signals that are suitable for motion estimation since they respond to changes in the scene. As any visual changes in the scene produce event data, it is paramount to classify the data into different motions (i.e., motion segmentation), which is useful for various tasks such as object detection and visual servoing. We propose an iterative motion segmentation method, by classifying events into background (e.g., dominant motion hypothesis) and foreground (independent motion residuals), thus extending the Contrast Maximization framework. Experimental results demonstrate that the proposed method successfully classifies event clusters both for public and self-recorded datasets, producing sharp, motion-compensated edge-like images. The proposed method achieves state-of-the-art accuracy on moving object detection benchmarks with an improvement of over 30%, and demonstrates its possibility of applying to more complex and noisy real-world scenes. We hope this work broadens the sensitivity of Contrast Maximization with respect to both motion parameters and input events, thus contributing to theoretical advancements in event-based motion segmentation estimation. https://github.com/aoki-media-lab/event_based_segmentation_vcmax
Formula-Supervised Sound Event Detection: Pre-Training Without Real Data
Apr 06, 2025In this paper, we propose a novel formula-driven supervised learning (FDSL) framework for pre-training an environmental sound analysis model by leveraging acoustic signals parametrically synthesized through formula-driven methods. Specifically, we outline detailed procedures and evaluate their effectiveness for sound event detection (SED). The SED task, which involves estimating the types and timings of sound events, is particularly challenged by the difficulty of acquiring a sufficient quantity of accurately labeled training data. Moreover, it is well known that manually annotated labels often contain noises and are significantly influenced by the subjective judgment of annotators. To address these challenges, we propose a novel pre-training method that utilizes a synthetic dataset, Formula-SED, where acoustic data are generated solely based on mathematical formulas. The proposed method enables large-scale pre-training by using the synthesis parameters applied at each time step as ground truth labels, thereby eliminating label noise and bias. We demonstrate that large-scale pre-training with Formula-SED significantly enhances model accuracy and accelerates training, as evidenced by our results in the DESED dataset used for DCASE2023 Challenge Task 4. The project page is at https://yutoshibata07.github.io/Formula-SED/
Simultaneous Motion And Noise Estimation with Event Cameras
Apr 05, 2025



Event cameras are emerging vision sensors, whose noise is challenging to characterize. Existing denoising methods for event cameras consider other tasks such as motion estimation separately (i.e., sequentially after denoising). However, motion is an intrinsic part of event data, since scene edges cannot be sensed without motion. This work proposes, to the best of our knowledge, the first method that simultaneously estimates motion in its various forms (e.g., ego-motion, optical flow) and noise. The method is flexible, as it allows replacing the 1-step motion estimation of the widely-used Contrast Maximization framework with any other motion estimator, such as deep neural networks. The experiments show that the proposed method achieves state-of-the-art results on the E-MLB denoising benchmark and competitive results on the DND21 benchmark, while showing its efficacy on motion estimation and intensity reconstruction tasks. We believe that the proposed approach contributes to strengthening the theory of event-data denoising, as well as impacting practical denoising use-cases, as we release the code upon acceptance. Project page: https://github.com/tub-rip/ESMD
BoundMatch: Boundary detection applied to semi-supervised segmentation for urban-driving scenes
Mar 30, 2025Semi-supervised semantic segmentation (SS-SS) aims to mitigate the heavy annotation burden of dense pixel labeling by leveraging abundant unlabeled images alongside a small labeled set. While current teacher-student consistency regularization methods achieve strong results, they often overlook a critical challenge: the precise delineation of object boundaries. In this paper, we propose BoundMatch, a novel multi-task SS-SS framework that explicitly integrates semantic boundary detection into the consistency regularization pipeline. Our core mechanism, Boundary Consistency Regularized Multi-Task Learning (BCRM), enforces prediction agreement between teacher and student models on both segmentation masks and detailed semantic boundaries. To further enhance performance and sharpen contours, BoundMatch incorporates two lightweight fusion modules: Boundary-Semantic Fusion (BSF) injects learned boundary cues into the segmentation decoder, while Spatial Gradient Fusion (SGF) refines boundary predictions using mask gradients, leading to higher-quality boundary pseudo-labels. This framework is built upon SAMTH, a strong teacher-student baseline featuring a Harmonious Batch Normalization (HBN) update strategy for improved stability. Extensive experiments on diverse datasets including Cityscapes, BDD100K, SYNTHIA, ADE20K, and Pascal VOC show that BoundMatch achieves competitive performance against state-of-the-art methods while significantly improving boundary-specific evaluation metrics. We also demonstrate its effectiveness in realistic large-scale unlabeled data scenarios and on lightweight architectures designed for mobile deployment.