 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormula-Supervised Sound Event Detection: Pre-Training Without Real Data
Apr 06, 2025In this paper, we propose a novel formula-driven supervised learning (FDSL) framework for pre-training an environmental sound analysis model by leveraging acoustic signals parametrically synthesized through formula-driven methods. Specifically, we outline detailed procedures and evaluate their effectiveness for sound event detection (SED). The SED task, which involves estimating the types and timings of sound events, is particularly challenged by the difficulty of acquiring a sufficient quantity of accurately labeled training data. Moreover, it is well known that manually annotated labels often contain noises and are significantly influenced by the subjective judgment of annotators. To address these challenges, we propose a novel pre-training method that utilizes a synthetic dataset, Formula-SED, where acoustic data are generated solely based on mathematical formulas. The proposed method enables large-scale pre-training by using the synthesis parameters applied at each time step as ground truth labels, thereby eliminating label noise and bias. We demonstrate that large-scale pre-training with Formula-SED significantly enhances model accuracy and accelerates training, as evidenced by our results in the DESED dataset used for DCASE2023 Challenge Task 4. The project page is at https://yutoshibata07.github.io/Formula-SED/
SyncViolinist: Music-Oriented Violin Motion Generation Based on Bowing and Fingering
Dec 11, 2024



Automatically generating realistic musical performance motion can greatly enhance digital media production, often involving collaboration between professionals and musicians. However, capturing the intricate body, hand, and finger movements required for accurate musical performances is challenging. Existing methods often fall short due to the complex mapping between audio and motion, typically requiring additional inputs like scores or MIDI data. In this work, we present SyncViolinist, a multi-stage end-to-end framework that generates synchronized violin performance motion solely from audio input. Our method overcomes the challenge of capturing both global and fine-grained performance features through two key modules: a bowing/fingering module and a motion generation module. The bowing/fingering module extracts detailed playing information from the audio, which the motion generation module uses to create precise, coordinated body motions reflecting the temporal granularity and nature of the violin performance. We demonstrate the effectiveness of SyncViolinist with significantly improved qualitative and quantitative results from unseen violin performance audio, outperforming state-of-the-art methods. Extensive subjective evaluations involving professional violinists further validate our approach. The code and dataset are available at https://github.com/Kakanat/SyncViolinist.
Gaze-Driven Sentence Simplification for Language Learners: Enhancing Comprehension and Readability
Sep 30, 2023



Language learners should regularly engage in reading challenging materials as part of their study routine. Nevertheless, constantly referring to dictionaries is time-consuming and distracting. This paper presents a novel gaze-driven sentence simplification system designed to enhance reading comprehension while maintaining their focus on the content. Our system incorporates machine learning models tailored to individual learners, combining eye gaze features and linguistic features to assess sentence comprehension. When the system identifies comprehension difficulties, it provides simplified versions by replacing complex vocabulary and grammar with simpler alternatives via GPT-3.5. We conducted an experiment with 19 English learners, collecting data on their eye movements while reading English text. The results demonstrated that our system is capable of accurately estimating sentence-level comprehension. Additionally, we found that GPT-3.5 simplification improved readability in terms of traditional readability metrics and individual word difficulty, paraphrasing across different linguistic levels.
Audio-Visual Speech Enhancement With Selective Off-Screen Speech Extraction
Jun 10, 2023



This paper describes an audio-visual speech enhancement (AV-SE) method that estimates from noisy input audio a mixture of the speech of the speaker appearing in an input video (on-screen target speech) and of a selected speaker not appearing in the video (off-screen target speech). Although conventional AV-SE methods have suppressed all off-screen sounds, it is necessary to listen to a specific pre-known speaker's speech (e.g., family member's voice and announcements in stations) in future applications of AV-SE (e.g., hearing aids), even when users' sight does not capture the speaker. To overcome this limitation, we extract a visual clue for the on-screen target speech from the input video and a voiceprint clue for the off-screen one from a pre-recorded speech of the speaker. Two clues from different domains are integrated as an audio-visual clue, and the proposed model directly estimates the target mixture. To improve the estimation accuracy, we introduce a temporal attention mechanism for the voiceprint clue and propose a training strategy called the muting strategy. Experimental results show that our method outperforms a baseline method that uses the state-of-the-art AV-SE and speaker extraction methods individually in terms of estimation accuracy and computational efficiency.
Improving the Gap in Visual Speech Recognition Between Normal and Silent Speech Based on Metric Learning
May 23, 2023



This paper presents a novel metric learning approach to address the performance gap between normal and silent speech in visual speech recognition (VSR). The difference in lip movements between the two poses a challenge for existing VSR models, which exhibit degraded accuracy when applied to silent speech. To solve this issue and tackle the scarcity of training data for silent speech, we propose to leverage the shared literal content between normal and silent speech and present a metric learning approach based on visemes. Specifically, we aim to map the input of two speech types close to each other in a latent space if they have similar viseme representations. By minimizing the Kullback-Leibler divergence of the predicted viseme probability distributions between and within the two speech types, our model effectively learns and predicts viseme identities. Our evaluation demonstrates that our method improves the accuracy of silent VSR, even when limited training data is available.
Memory Efficient Diffusion Probabilistic Models via Patch-based Generation
Apr 14, 2023Diffusion probabilistic models have been successful in generating high-quality and diverse images. However, traditional models, whose input and output are high-resolution images, suffer from excessive memory requirements, making them less practical for edge devices. Previous approaches for generative adversarial networks proposed a patch-based method that uses positional encoding and global content information. Nevertheless, designing a patch-based approach for diffusion probabilistic models is non-trivial. In this paper, we resent a diffusion probabilistic model that generates images on a patch-by-patch basis. We propose two conditioning methods for a patch-based generation. First, we propose position-wise conditioning using one-hot representation to ensure patches are in proper positions. Second, we propose Global Content Conditioning (GCC) to ensure patches have coherent content when concatenated together. We evaluate our model qualitatively and quantitatively on CelebA and LSUN bedroom datasets and demonstrate a moderate trade-off between maximum memory consumption and generated image quality. Specifically, when an entire image is divided into 2 x 2 patches, our proposed approach can reduce the maximum memory consumption by half while maintaining comparable image quality.
Manifold-Aware Deep Clustering: Maximizing Angles between Embedding Vectors Based on Regular Simplex
Jun 16, 2021
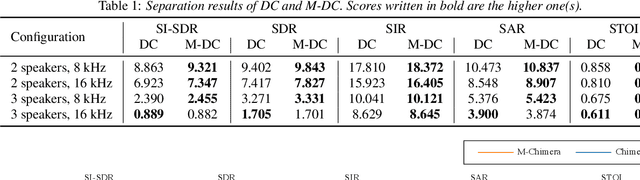
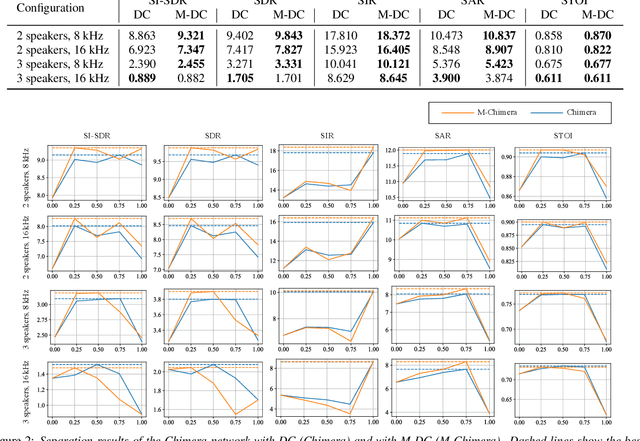
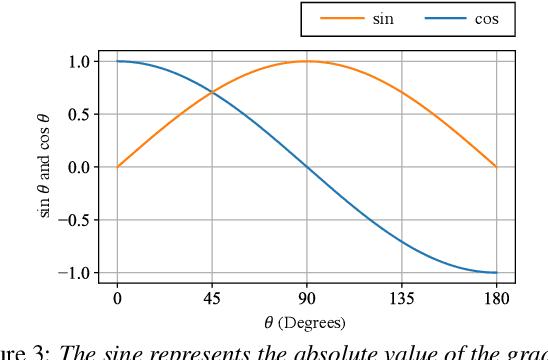
This paper presents a new deep clustering (DC) method called manifold-aware DC (M-DC) that can enhance hyperspace utilization more effectively than the original DC. The original DC has a limitation in that a pair of two speakers has to be embedded having an orthogonal relationship due to its use of the one-hot vector-based loss function, while our method derives a unique loss function aimed at maximizing the target angle in the hyperspace based on the nature of a regular simplex. Our proposed loss imposes a higher penalty than the original DC when the speaker is assigned incorrectly. The change from DC to M-DC can be easily achieved by rewriting just one term in the loss function of DC, without any other modifications to the network architecture or model parameters. As such, our method has high practicability because it does not affect the original inference part. The experimental results show that the proposed method improves the performances of the original DC and its expansion method.