 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointing out Human Answer Mistakes in a Goal-Oriented Visual Dialogue
Sep 19, 2023



Effective communication between humans and intelligent agents has promising applications for solving complex problems. One such approach is visual dialogue, which leverages multimodal context to assist humans. However, real-world scenarios occasionally involve human mistakes, which can cause intelligent agents to fail. While most prior research assumes perfect answers from human interlocutors, we focus on a setting where the agent points out unintentional mistakes for the interlocutor to review, better reflecting real-world situations. In this paper, we show that human answer mistakes depend on question type and QA turn in the visual dialogue by analyzing a previously unused data collection of human mistakes. We demonstrate the effectiveness of those factors for the model's accuracy in a pointing-human-mistake task through experiments using a simple MLP model and a Visual Language Model.
Enhancing Inverse Problem Solutions with Accurate Surrogate Simulators and Promising Candidates
Apr 26, 2023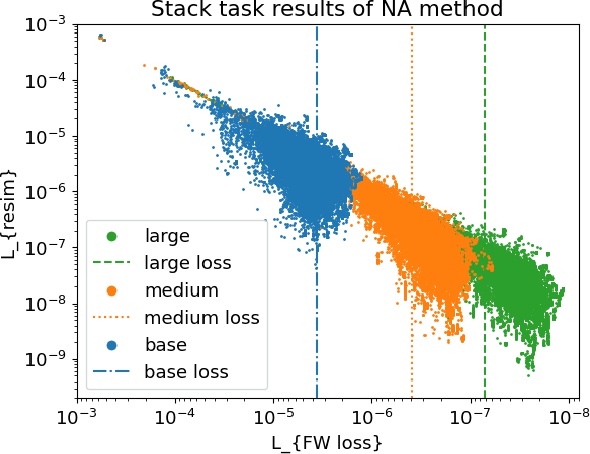

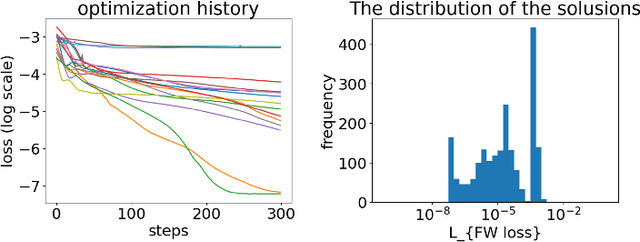

Deep-learning inverse techniques have attracted significant attention in recent years. Among them, the neural adjoint (NA) method, which employs a neural network surrogate simulator, has demonstrated impressive performance in the design tasks of artificial electromagnetic materials (AEM). However, the impact of the surrogate simulators' accuracy on the solutions in the NA method remains uncertain. Furthermore, achieving sufficient optimization becomes challenging in this method when the surrogate simulator is large, and computational resources are limited. Additionally, the behavior under constraints has not been studied, despite its importance from the engineering perspective. In this study, we investigated the impact of surrogate simulators' accuracy on the solutions and discovered that the more accurate the surrogate simulator is, the better the solutions become. We then developed an extension of the NA method, named Neural Lagrangian (NeuLag) method, capable of efficiently optimizing a sufficient number of solution candidates. We then demonstrated that the NeuLag method can find optimal solutions even when handling sufficient candidates is difficult due to the use of a large and accurate surrogate simulator. The resimulation errors of the NeuLag method were approximately 1/50 compared to previous methods for three AEM tasks. Finally, we performed optimization under constraint using NA and NeuLag, and confirmed their potential in optimization with soft or hard constraints. We believe our method holds potential in areas that require large and accurate surrogate simulators.
Memory Efficient Diffusion Probabilistic Models via Patch-based Generation
Apr 14, 2023Diffusion probabilistic models have been successful in generating high-quality and diverse images. However, traditional models, whose input and output are high-resolution images, suffer from excessive memory requirements, making them less practical for edge devices. Previous approaches for generative adversarial networks proposed a patch-based method that uses positional encoding and global content information. Nevertheless, designing a patch-based approach for diffusion probabilistic models is non-trivial. In this paper, we resent a diffusion probabilistic model that generates images on a patch-by-patch basis. We propose two conditioning methods for a patch-based generation. First, we propose position-wise conditioning using one-hot representation to ensure patches are in proper positions. Second, we propose Global Content Conditioning (GCC) to ensure patches have coherent content when concatenated together. We evaluate our model qualitatively and quantitatively on CelebA and LSUN bedroom datasets and demonstrate a moderate trade-off between maximum memory consumption and generated image quality. Specifically, when an entire image is divided into 2 x 2 patches, our proposed approach can reduce the maximum memory consumption by half while maintaining comparable image quality.
Scapegoat Generation for Privacy Protection from Deepfake
Mar 06, 2023



To protect privacy and prevent malicious use of deepfake, current studies propose methods that interfere with the generation process, such as detection and destruction approaches. However, these methods suffer from sub-optimal generalization performance to unseen models and add undesirable noise to the original image. To address these problems, we propose a new problem formulation for deepfake prevention: generating a ``scapegoat image'' by modifying the style of the original input in a way that is recognizable as an avatar by the user, but impossible to reconstruct the real face. Even in the case of malicious deepfake, the privacy of the users is still protected. To achieve this, we introduce an optimization-based editing method that utilizes GAN inversion to discourage deepfake models from generating similar scapegoats. We validate the effectiveness of our proposed method through quantitative and user studies.