 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoireMix: A Formula-Based Data Augmentation for Improving Image Classification Robustness
Mar 26, 2026Data augmentation is a key technique for improving the robustness of image classification models. However, many recent approaches rely on diffusion-based synthesis or complex feature mixing strategies, which introduce substantial computational overhead or require external datasets. In this work, we explore a different direction: procedural augmentation based on analytic interference patterns. Unlike conventional augmentation methods that rely on stochastic noise, feature mixing, or generative models, our approach exploits Moire interference to generate structured perturbations spanning a wide range of spatial frequencies. We propose a lightweight augmentation method that procedurally generates Moire textures on-the-fly using a closed-form mathematical formulation. The patterns are synthesized directly in memory with negligible computational cost (0.0026 seconds per image), mixed with training images during training, and immediately discarded, enabling a storage-free augmentation pipeline without external data. Extensive experiments with Vision Transformers demonstrate that the proposed method consistently improves robustness across multiple benchmarks, including ImageNet-C, ImageNet-R, and adversarial benchmarks, outperforming standard augmentation baselines and existing external-data-free augmentation approaches. These results suggest that analytic interference patterns provide a practical and efficient alternative to data-driven generative augmentation methods.
FDIF: Formula-Driven supervised Learning with Implicit Functions for 3D Medical Image Segmentation
Mar 24, 2026Deep learning-based 3D medical image segmentation methods relies on large-scale labeled datasets, yet acquiring such data is difficult due to privacy constraints and the high cost of expert annotation. Formula-Driven Supervised Learning (FDSL) offers an appealing alternative by generating training data and labels directly from mathematical formulas. However, existing voxel-based approaches are limited in geometric expressiveness and cannot synthesize realistic textures. We introduce Formula-Driven supervised learning with Implicit Functions (FDIF), a framework that enables scalable pre-training without using any real data and medical expert annotations. FDIF introduces an implicit-function representation based on signed distance functions (SDFs), enabling compact modeling of complex geometries while exploiting the surface representation of SDFs to support controllable synthesis of both geometric and intensity textures. Across three medical image segmentation benchmarks (AMOS, ACDC, and KiTS) and three architectures (SwinUNETR, nnUNet ResEnc-L, and nnUNet Primus-M), FDIF consistently improves over a formula-driven method, and achieves performance comparable to self-supervised approaches pre-trained on large-scale real datasets. We further show that FDIF pre-training also benefits 3D classification tasks, highlighting implicit-function-based formula supervision as a promising paradigm for data-free representation learning. Code is available at https://github.com/yamanoko/FDIF.
3D sans 3D Scans: Scalable Pre-training from Video-Generated Point Clouds
Dec 28, 2025Despite recent progress in 3D self-supervised learning, collecting large-scale 3D scene scans remains expensive and labor-intensive. In this work, we investigate whether 3D representations can be learned from unlabeled videos recorded without any real 3D sensors. We present Laplacian-Aware Multi-level 3D Clustering with Sinkhorn-Knopp (LAM3C), a self-supervised framework that learns from video-generated point clouds from unlabeled videos. We first introduce RoomTours, a video-generated point cloud dataset constructed by collecting room-walkthrough videos from the web (e.g., real-estate tours) and generating 49,219 scenes using an off-the-shelf feed-forward reconstruction model. We also propose a noise-regularized loss that stabilizes representation learning by enforcing local geometric smoothness and ensuring feature stability under noisy point clouds. Remarkably, without using any real 3D scans, LAM3C achieves higher performance than the previous self-supervised methods on indoor semantic and instance segmentation. These results suggest that unlabeled videos represent an abundant source of data for 3D self-supervised learning.
S3OD: Towards Generalizable Salient Object Detection with Synthetic Data
Oct 24, 2025Salient object detection exemplifies data-bounded tasks where expensive pixel-precise annotations force separate model training for related subtasks like DIS and HR-SOD. We present a method that dramatically improves generalization through large-scale synthetic data generation and ambiguity-aware architecture. We introduce S3OD, a dataset of over 139,000 high-resolution images created through our multi-modal diffusion pipeline that extracts labels from diffusion and DINO-v3 features. The iterative generation framework prioritizes challenging categories based on model performance. We propose a streamlined multi-mask decoder that naturally handles the inherent ambiguity in salient object detection by predicting multiple valid interpretations. Models trained solely on synthetic data achieve 20-50% error reduction in cross-dataset generalization, while fine-tuned versions reach state-of-the-art performance across DIS and HR-SOD benchmarks.
AgroBench: Vision-Language Model Benchmark in Agriculture
Jul 28, 2025

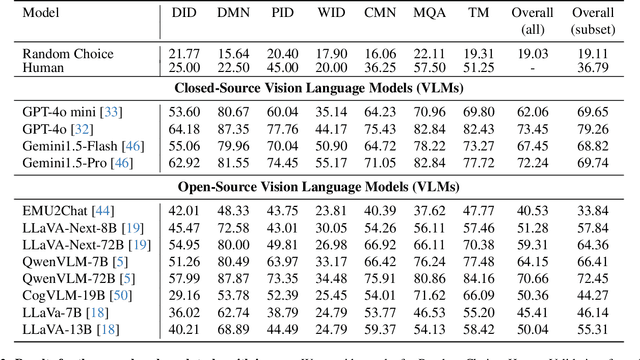
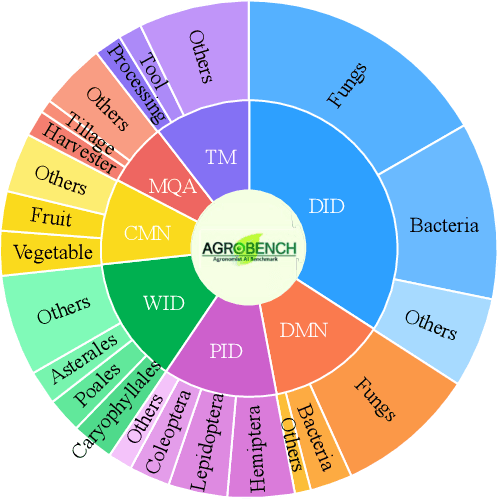
Precise automated understanding of agricultural tasks such as disease identification is essential for sustainable crop production. Recent advances in vision-language models (VLMs) are expected to further expand the range of agricultural tasks by facilitating human-model interaction through easy, text-based communication. Here, we introduce AgroBench (Agronomist AI Benchmark), a benchmark for evaluating VLM models across seven agricultural topics, covering key areas in agricultural engineering and relevant to real-world farming. Unlike recent agricultural VLM benchmarks, AgroBench is annotated by expert agronomists. Our AgroBench covers a state-of-the-art range of categories, including 203 crop categories and 682 disease categories, to thoroughly evaluate VLM capabilities. In our evaluation on AgroBench, we reveal that VLMs have room for improvement in fine-grained identification tasks. Notably, in weed identification, most open-source VLMs perform close to random. With our wide range of topics and expert-annotated categories, we analyze the types of errors made by VLMs and suggest potential pathways for future VLM development. Our dataset and code are available at https://dahlian00.github.io/AgroBenchPage/ .
AnimalClue: Recognizing Animals by their Traces
Jul 27, 2025



Wildlife observation plays an important role in biodiversity conservation, necessitating robust methodologies for monitoring wildlife populations and interspecies interactions. Recent advances in computer vision have significantly contributed to automating fundamental wildlife observation tasks, such as animal detection and species identification. However, accurately identifying species from indirect evidence like footprints and feces remains relatively underexplored, despite its importance in contributing to wildlife monitoring. To bridge this gap, we introduce AnimalClue, the first large-scale dataset for species identification from images of indirect evidence. Our dataset consists of 159,605 bounding boxes encompassing five categories of indirect clues: footprints, feces, eggs, bones, and feathers. It covers 968 species, 200 families, and 65 orders. Each image is annotated with species-level labels, bounding boxes or segmentation masks, and fine-grained trait information, including activity patterns and habitat preferences. Unlike existing datasets primarily focused on direct visual features (e.g., animal appearances), AnimalClue presents unique challenges for classification, detection, and instance segmentation tasks due to the need for recognizing more detailed and subtle visual features. In our experiments, we extensively evaluate representative vision models and identify key challenges in animal identification from their traces. Our dataset and code are available at https://dahlian00.github.io/AnimalCluePage/
Industrial Synthetic Segment Pre-training
May 20, 2025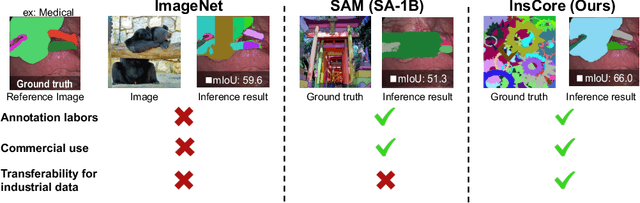


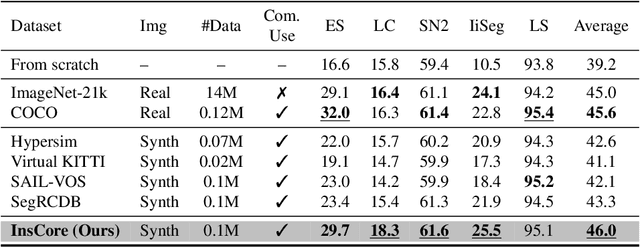
Pre-training on real-image datasets has been widely proven effective for improving instance segmentation. However, industrial applications face two key challenges: (1) legal and ethical restrictions, such as ImageNet's prohibition of commercial use, and (2) limited transferability due to the domain gap between web images and industrial imagery. Even recent vision foundation models, including the segment anything model (SAM), show notable performance degradation in industrial settings. These challenges raise critical questions: Can we build a vision foundation model for industrial applications without relying on real images or manual annotations? And can such models outperform even fine-tuned SAM on industrial datasets? To address these questions, we propose the Instance Core Segmentation Dataset (InsCore), a synthetic pre-training dataset based on formula-driven supervised learning (FDSL). InsCore generates fully annotated instance segmentation images that reflect key characteristics of industrial data, including complex occlusions, dense hierarchical masks, and diverse non-rigid shapes, distinct from typical web imagery. Unlike previous methods, InsCore requires neither real images nor human annotations. Experiments on five industrial datasets show that models pre-trained with InsCore outperform those trained on COCO and ImageNet-21k, as well as fine-tuned SAM, achieving an average improvement of 6.2 points in instance segmentation performance. This result is achieved using only 100k synthetic images, more than 100 times fewer than the 11 million images in SAM's SA-1B dataset, demonstrating the data efficiency of our approach. These findings position InsCore as a practical and license-free vision foundation model for industrial applications.
Industry-focused Synthetic Segmentation Pre-training
May 19, 2025Pre-training on real-image datasets has been widely proven effective for improving instance segmentation. However, industrial applications face two key challenges: (1) legal and ethical restrictions, such as ImageNet's prohibition of commercial use, and (2) limited transferability due to the domain gap between web images and industrial imagery. Even recent vision foundation models, including the segment anything model (SAM), show notable performance degradation in industrial settings. These challenges raise critical questions: Can we build a vision foundation model for industrial applications without relying on real images or manual annotations? And can such models outperform even fine-tuned SAM on industrial datasets? To address these questions, we propose the Instance Core Segmentation Dataset (InsCore), a synthetic pre-training dataset based on formula-driven supervised learning (FDSL). InsCore generates fully annotated instance segmentation images that reflect key characteristics of industrial data, including complex occlusions, dense hierarchical masks, and diverse non-rigid shapes, distinct from typical web imagery. Unlike previous methods, InsCore requires neither real images nor human annotations. Experiments on five industrial datasets show that models pre-trained with InsCore outperform those trained on COCO and ImageNet-21k, as well as fine-tuned SAM, achieving an average improvement of 6.2 points in instance segmentation performance. This result is achieved using only 100k synthetic images, more than 100 times fewer than the 11 million images in SAM's SA-1B dataset, demonstrating the data efficiency of our approach. These findings position InsCore as a practical and license-free vision foundation model for industrial applications.
Simple Visual Artifact Detection in Sora-Generated Videos
Apr 30, 2025The December 2024 release of OpenAI's Sora, a powerful video generation model driven by natural language prompts, highlights a growing convergence between large language models (LLMs) and video synthesis. As these multimodal systems evolve into video-enabled LLMs (VidLLMs), capable of interpreting, generating, and interacting with visual content, understanding their limitations and ensuring their safe deployment becomes essential. This study investigates visual artifacts frequently found and reported in Sora-generated videos, which can compromise quality, mislead viewers, or propagate disinformation. We propose a multi-label classification framework targeting four common artifact label types: label 1: boundary / edge defects, label 2: texture / noise issues, label 3: movement / joint anomalies, and label 4: object mismatches / disappearances. Using a dataset of 300 manually annotated frames extracted from 15 Sora-generated videos, we trained multiple 2D CNN architectures (ResNet-50, EfficientNet-B3 / B4, ViT-Base). The best-performing model trained by ResNet-50 achieved an average multi-label classification accuracy of 94.14%. This work supports the broader development of VidLLMs by contributing to (1) the creation of datasets for video quality evaluation, (2) interpretable artifact-based analysis beyond language metrics, and (3) the identification of visual risks relevant to factuality and safety.
Formula-Supervised Sound Event Detection: Pre-Training Without Real Data
Apr 06, 2025In this paper, we propose a novel formula-driven supervised learning (FDSL) framework for pre-training an environmental sound analysis model by leveraging acoustic signals parametrically synthesized through formula-driven methods. Specifically, we outline detailed procedures and evaluate their effectiveness for sound event detection (SED). The SED task, which involves estimating the types and timings of sound events, is particularly challenged by the difficulty of acquiring a sufficient quantity of accurately labeled training data. Moreover, it is well known that manually annotated labels often contain noises and are significantly influenced by the subjective judgment of annotators. To address these challenges, we propose a novel pre-training method that utilizes a synthetic dataset, Formula-SED, where acoustic data are generated solely based on mathematical formulas. The proposed method enables large-scale pre-training by using the synthesis parameters applied at each time step as ground truth labels, thereby eliminating label noise and bias. We demonstrate that large-scale pre-training with Formula-SED significantly enhances model accuracy and accelerates training, as evidenced by our results in the DESED dataset used for DCASE2023 Challenge Task 4. The project page is at https://yutoshibata07.github.io/Formula-SED/