 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETR: Entropy Trend Reward for Efficient Chain-of-Thought Reasoning
Apr 07, 2026Chain-of-thought (CoT) reasoning improves large language model performance on complex tasks, but often produces excessively long and inefficient reasoning traces. Existing methods shorten CoTs using length penalties or global entropy reduction, implicitly assuming that low uncertainty is desirable throughout reasoning. We show instead that reasoning efficiency is governed by the trajectory of uncertainty. CoTs with dominant downward entropy trends are substantially shorter. Motivated by this insight, we propose Entropy Trend Reward (ETR), a trajectory-aware objective that encourages progressive uncertainty reduction while allowing limited local exploration. We integrate ETR into Group Relative Policy Optimization (GRPO) and evaluate it across multiple reasoning models and challenging benchmarks. ETR consistently achieves a superior accuracy-efficiency tradeoff, improving DeepSeek-R1-Distill-7B by 9.9% in accuracy while reducing CoT length by 67% across four benchmarks. Code is available at https://github.com/Xuan1030/ETR
VP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
Nov 14, 2025Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.
Leveraging LLMs with Iterative Loop Structure for Enhanced Social Intelligence in Video Question Answering
Mar 27, 2025



Social intelligence, the ability to interpret emotions, intentions, and behaviors, is essential for effective communication and adaptive responses. As robots and AI systems become more prevalent in caregiving, healthcare, and education, the demand for AI that can interact naturally with humans grows. However, creating AI that seamlessly integrates multiple modalities, such as vision and speech, remains a challenge. Current video-based methods for social intelligence rely on general video recognition or emotion recognition techniques, often overlook the unique elements inherent in human interactions. To address this, we propose the Looped Video Debating (LVD) framework, which integrates Large Language Models (LLMs) with visual information, such as facial expressions and body movements, to enhance the transparency and reliability of question-answering tasks involving human interaction videos. Our results on the Social-IQ 2.0 benchmark show that LVD achieves state-of-the-art performance without fine-tuning. Furthermore, supplementary human annotations on existing datasets provide insights into the model's accuracy, guiding future improvements in AI-driven social intelligence.
From Text to Trajectory: Exploring Complex Constraint Representation and Decomposition in Safe Reinforcement Learning
Dec 12, 2024
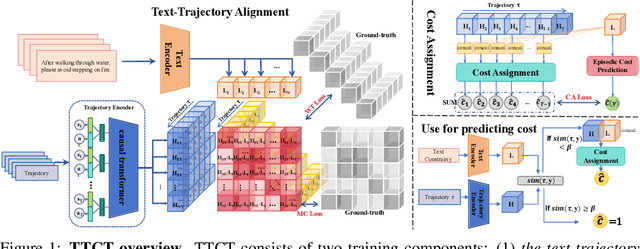
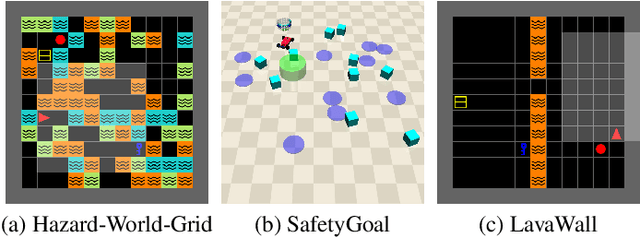

Safe reinforcement learning (RL) requires the agent to finish a given task while obeying specific constraints. Giving constraints in natural language form has great potential for practical scenarios due to its flexible transfer capability and accessibility. Previous safe RL methods with natural language constraints typically need to design cost functions manually for each constraint, which requires domain expertise and lacks flexibility. In this paper, we harness the dual role of text in this task, using it not only to provide constraint but also as a training signal. We introduce the Trajectory-level Textual Constraints Translator (TTCT) to replace the manually designed cost function. Our empirical results demonstrate that TTCT effectively comprehends textual constraint and trajectory, and the policies trained by TTCT can achieve a lower violation rate than the standard cost function. Extra studies are conducted to demonstrate that the TTCT has zero-shot transfer capability to adapt to constraint-shift environments.
MS2Mesh-XR: Multi-modal Sketch-to-Mesh Generation in XR Environments
Dec 12, 2024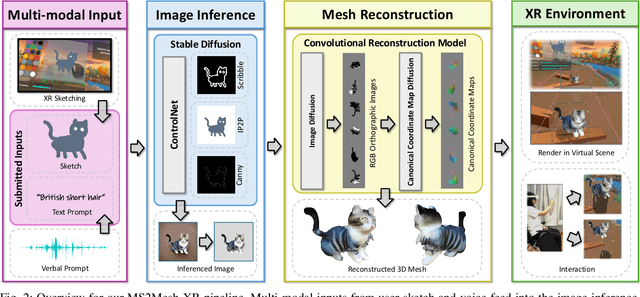

We present MS2Mesh-XR, a novel multi-modal sketch-to-mesh generation pipeline that enables users to create realistic 3D objects in extended reality (XR) environments using hand-drawn sketches assisted by voice inputs. In specific, users can intuitively sketch objects using natural hand movements in mid-air within a virtual environment. By integrating voice inputs, we devise ControlNet to infer realistic images based on the drawn sketches and interpreted text prompts. Users can then review and select their preferred image, which is subsequently reconstructed into a detailed 3D mesh using the Convolutional Reconstruction Model. In particular, our proposed pipeline can generate a high-quality 3D mesh in less than 20 seconds, allowing for immersive visualization and manipulation in run-time XR scenes. We demonstrate the practicability of our pipeline through two use cases in XR settings. By leveraging natural user inputs and cutting-edge generative AI capabilities, our approach can significantly facilitate XR-based creative production and enhance user experiences. Our code and demo will be available at: https://yueqiu0911.github.io/MS2Mesh-XR/
Segment Any Object Model : Real-to-Simulation Fine-Tuning Strategy for Multi-Class Multi-Instance Segmentation
Mar 16, 2024



Multi-class multi-instance segmentation is the task of identifying masks for multiple object classes and multiple instances of the same class within an image. The foundational Segment Anything Model (SAM) is designed for promptable multi-class multi-instance segmentation but tends to output part or sub-part masks in the "everything" mode for various real-world applications. Whole object segmentation masks play a crucial role for indoor scene understanding, especially in robotics applications. We propose a new domain invariant Real-to-Simulation (Real-Sim) fine-tuning strategy for SAM. We use object images and ground truth data collected from Ai2Thor simulator during fine-tuning (real-to-sim). To allow our Segment Any Object Model (SAOM) to work in the "everything" mode, we propose the novel nearest neighbour assignment method, updating point embeddings for each ground-truth mask. SAOM is evaluated on our own dataset collected from Ai2Thor simulator. SAOM significantly improves on SAM, with a 28% increase in mIoU and a 25% increase in mAcc for 54 frequently-seen indoor object classes. Moreover, our Real-to-Simulation fine-tuning strategy demonstrates promising generalization performance in real environments without being trained on the real-world data (sim-to-real). The dataset and the code will be released after publication.
Resolution invariant deep operator network for PDEs with complex geometries
Feb 01, 2024Neural operators (NO) are discretization invariant deep learning methods with functional output and can approximate any continuous operator. NO have demonstrated the superiority of solving partial differential equations (PDEs) over other deep learning methods. However, the spatial domain of its input function needs to be identical to its output, which limits its applicability. For instance, the widely used Fourier neural operator (FNO) fails to approximate the operator that maps the boundary condition to the PDE solution. To address this issue, we propose a novel framework called resolution-invariant deep operator (RDO) that decouples the spatial domain of the input and output. RDO is motivated by the Deep operator network (DeepONet) and it does not require retraining the network when the input/output is changed compared with DeepONet. RDO takes functional input and its output is also functional so that it keeps the resolution invariant property of NO. It can also resolve PDEs with complex geometries whereas NO fail. Various numerical experiments demonstrate the advantage of our method over DeepONet and FNO.
Sparse discovery of differential equations based on multi-fidelity Gaussian process
Jan 22, 2024

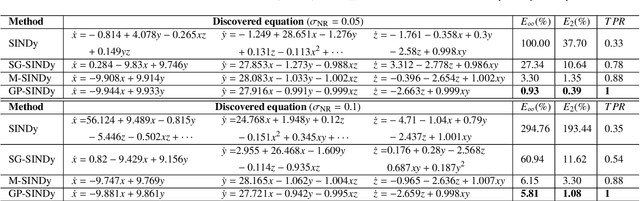
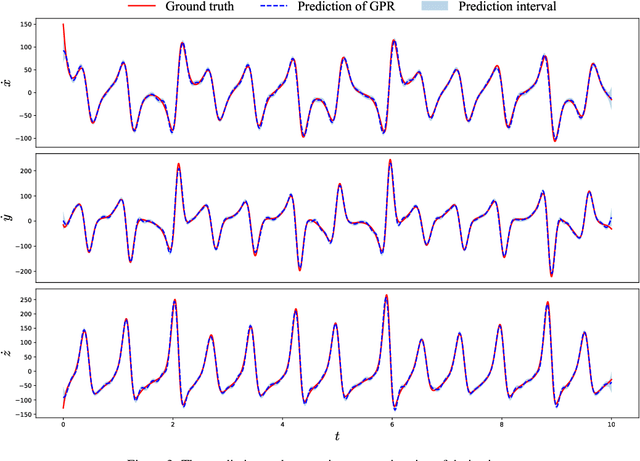
Sparse identification of differential equations aims to compute the analytic expressions from the observed data explicitly. However, there exist two primary challenges. Firstly, it exhibits sensitivity to the noise in the observed data, particularly for the derivatives computations. Secondly, existing literature predominantly concentrates on single-fidelity (SF) data, which imposes limitations on its applicability due to the computational cost. In this paper, we present two novel approaches to address these problems from the view of uncertainty quantification. We construct a surrogate model employing the Gaussian process regression (GPR) to mitigate the effect of noise in the observed data, quantify its uncertainty, and ultimately recover the equations accurately. Subsequently, we exploit the multi-fidelity Gaussian processes (MFGP) to address scenarios involving multi-fidelity (MF), sparse, and noisy observed data. We demonstrate the robustness and effectiveness of our methodologies through several numerical experiments.
Conformal Prediction for Deep Classifier via Label Ranking
Oct 10, 2023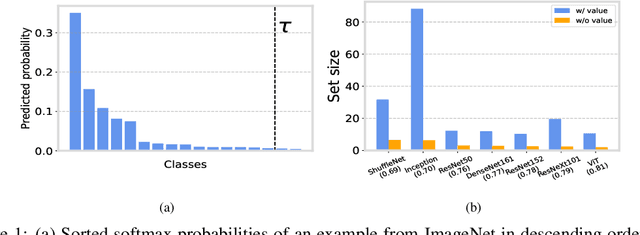
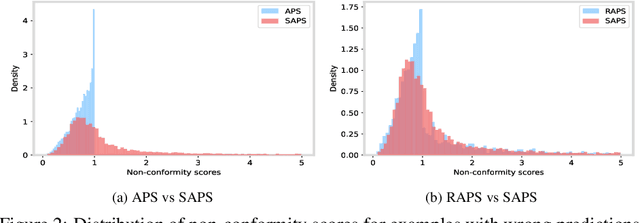
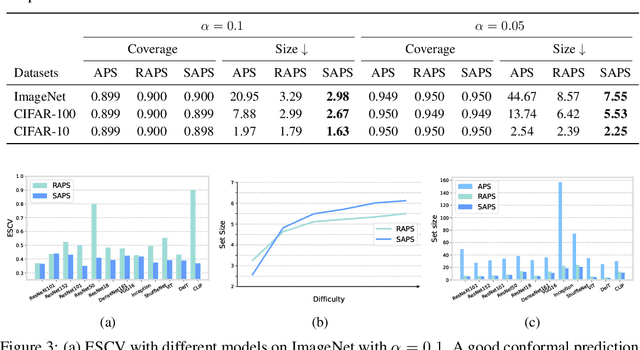
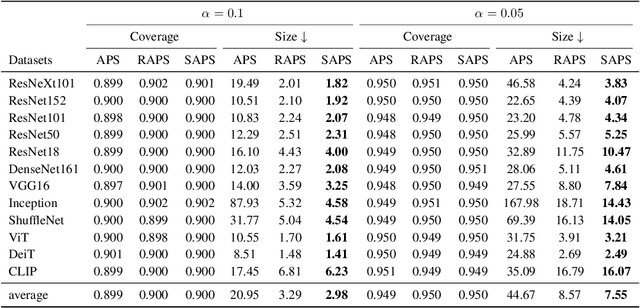
Conformal prediction is a statistical framework that generates prediction sets containing ground-truth labels with a desired coverage guarantee. The predicted probabilities produced by machine learning models are generally miscalibrated, leading to large prediction sets in conformal prediction. In this paper, we empirically and theoretically show that disregarding the probabilities' value will mitigate the undesirable effect of miscalibrated probability values. Then, we propose a novel algorithm named $\textit{Sorted Adaptive prediction sets}$ (SAPS), which discards all the probability values except for the maximum softmax probability. The key idea behind SAPS is to minimize the dependence of the non-conformity score on the probability values while retaining the uncertainty information. In this manner, SAPS can produce sets of small size and communicate instance-wise uncertainty. Theoretically, we provide a finite-sample coverage guarantee of SAPS and show that the expected value of set size from SAPS is always smaller than APS. Extensive experiments validate that SAPS not only lessens the prediction sets but also broadly enhances the conditional coverage rate and adaptation of prediction sets.
Physics-informed invertible neural network for the Koopman operator learning
Jun 30, 2023In Koopman operator theory, a finite-dimensional nonlinear system is transformed into an infinite but linear system using a set of observable functions. However, manually selecting observable functions that span the invariant subspace of the Koopman operator based on prior knowledge is inefficient and challenging, particularly when little or no information is available about the underlying systems. Furthermore, current methodologies tend to disregard the importance of the invertibility of observable functions, which leads to inaccurate results. To address these challenges, we propose the so-called FlowDMD, a Flow-based Dynamic Mode Decomposition that utilizes the Coupling Flow Invertible Neural Network (CF-INN) framework. FlowDMD leverages the intrinsically invertible characteristics of the CF-INN to learn the invariant subspaces of the Koopman operator and accurately reconstruct state variables. Numerical experiments demonstrate the superior performance of our algorithm compared to state-of-the-art methodologies.