 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-Guided Lidar Segmentation and Odometry Using Image-to-Point Cloud Saliency Transfer
Aug 28, 2023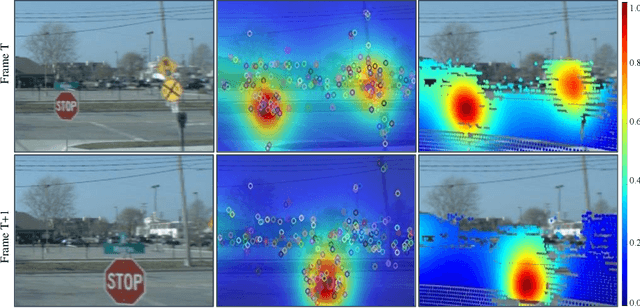

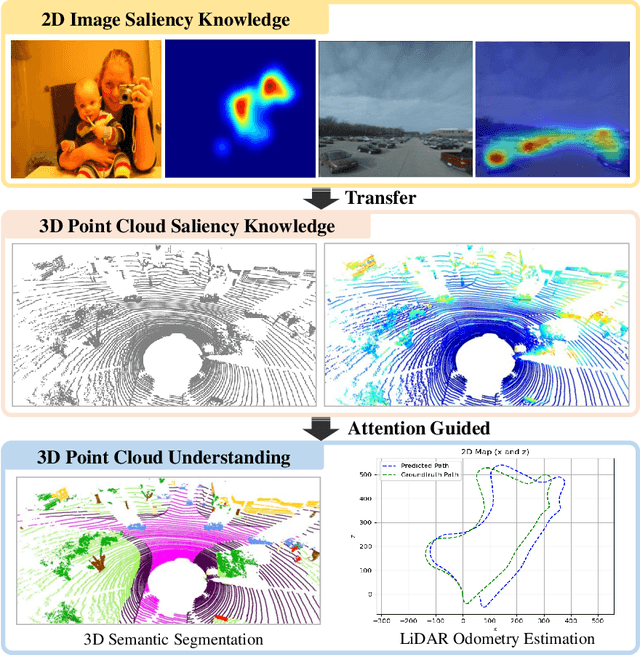
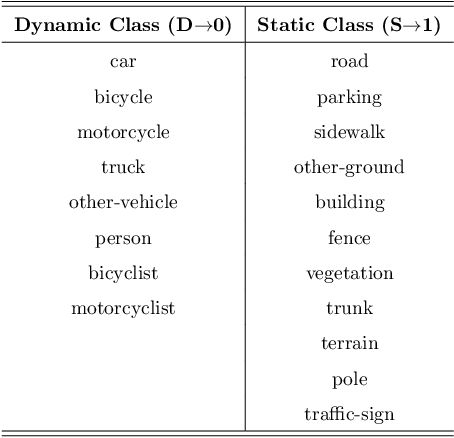
LiDAR odometry estimation and 3D semantic segmentation are crucial for autonomous driving, which has achieved remarkable advances recently. However, these tasks are challenging due to the imbalance of points in different semantic categories for 3D semantic segmentation and the influence of dynamic objects for LiDAR odometry estimation, which increases the importance of using representative/salient landmarks as reference points for robust feature learning. To address these challenges, we propose a saliency-guided approach that leverages attention information to improve the performance of LiDAR odometry estimation and semantic segmentation models. Unlike in the image domain, only a few studies have addressed point cloud saliency information due to the lack of annotated training data. To alleviate this, we first present a universal framework to transfer saliency distribution knowledge from color images to point clouds, and use this to construct a pseudo-saliency dataset (i.e. FordSaliency) for point clouds. Then, we adopt point cloud-based backbones to learn saliency distribution from pseudo-saliency labels, which is followed by our proposed SalLiDAR module. SalLiDAR is a saliency-guided 3D semantic segmentation model that integrates saliency information to improve segmentation performance. Finally, we introduce SalLONet, a self-supervised saliency-guided LiDAR odometry network that uses the semantic and saliency predictions of SalLiDAR to achieve better odometry estimation. Our extensive experiments on benchmark datasets demonstrate that the proposed SalLiDAR and SalLONet models achieve state-of-the-art performance against existing methods, highlighting the effectiveness of image-to-LiDAR saliency knowledge transfer. Source code will be available at https://github.com/nevrez/SalLONet.
TransFusionOdom: Interpretable Transformer-based LiDAR-Inertial Fusion Odometry Estimation
Apr 26, 2023Multi-modal fusion of sensors is a commonly used approach to enhance the performance of odometry estimation, which is also a fundamental module for mobile robots. However, the question of \textit{how to perform fusion among different modalities in a supervised sensor fusion odometry estimation task?} is still one of challenging issues remains. Some simple operations, such as element-wise summation and concatenation, are not capable of assigning adaptive attentional weights to incorporate different modalities efficiently, which make it difficult to achieve competitive odometry results. Recently, the Transformer architecture has shown potential for multi-modal fusion tasks, particularly in the domains of vision with language. In this work, we propose an end-to-end supervised Transformer-based LiDAR-Inertial fusion framework (namely TransFusionOdom) for odometry estimation. The multi-attention fusion module demonstrates different fusion approaches for homogeneous and heterogeneous modalities to address the overfitting problem that can arise from blindly increasing the complexity of the model. Additionally, to interpret the learning process of the Transformer-based multi-modal interactions, a general visualization approach is introduced to illustrate the interactions between modalities. Moreover, exhaustive ablation studies evaluate different multi-modal fusion strategies to verify the performance of the proposed fusion strategy. A synthetic multi-modal dataset is made public to validate the generalization ability of the proposed fusion strategy, which also works for other combinations of different modalities. The quantitative and qualitative odometry evaluations on the KITTI dataset verify the proposed TransFusionOdom could achieve superior performance compared with other related works.
SalFBNet: Learning Pseudo-Saliency Distribution via Feedback Convolutional Networks
Jan 11, 2022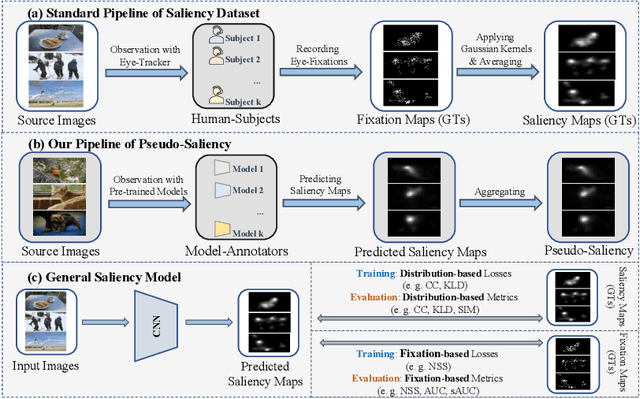
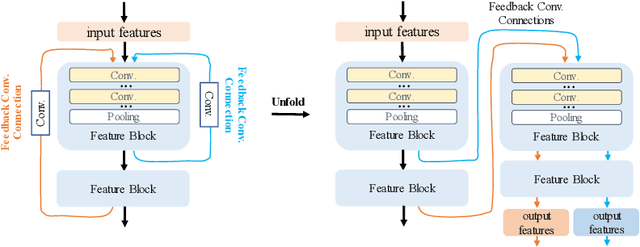
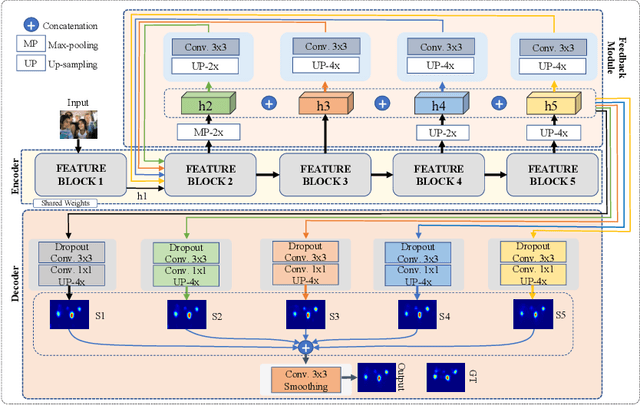
Feed-forward only convolutional neural networks (CNNs) may ignore intrinsic relationships and potential benefits of feedback connections in vision tasks such as saliency detection, despite their significant representation capabilities. In this work, we propose a feedback-recursive convolutional framework (SalFBNet) for saliency detection. The proposed feedback model can learn abundant contextual representations by bridging a recursive pathway from higher-level feature blocks to low-level layer. Moreover, we create a large-scale Pseudo-Saliency dataset to alleviate the problem of data deficiency in saliency detection. We first use the proposed feedback model to learn saliency distribution from pseudo-ground-truth. Afterwards, we fine-tune the feedback model on existing eye-fixation datasets. Furthermore, we present a novel Selective Fixation and Non-Fixation Error (sFNE) loss to make proposed feedback model better learn distinguishable eye-fixation-based features. Extensive experimental results show that our SalFBNet with fewer parameters achieves competitive results on the public saliency detection benchmarks, which demonstrate the effectiveness of proposed feedback model and Pseudo-Saliency data. Source codes and Pseudo-Saliency dataset can be found at https://github.com/gqding/SalFBNet
Anomaly Detection in Video Sequences: A Benchmark and Computational Model
Jun 16, 2021
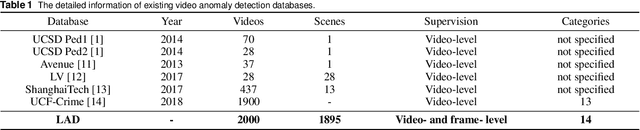


Anomaly detection has attracted considerable search attention. However, existing anomaly detection databases encounter two major problems. Firstly, they are limited in scale. Secondly, training sets contain only video-level labels indicating the existence of an abnormal event during the full video while lacking annotations of precise time durations. To tackle these problems, we contribute a new Large-scale Anomaly Detection (LAD) database as the benchmark for anomaly detection in video sequences, which is featured in two aspects. 1) It contains 2000 video sequences including normal and abnormal video clips with 14 anomaly categories including crash, fire, violence, etc. with large scene varieties, making it the largest anomaly analysis database to date. 2) It provides the annotation data, including video-level labels (abnormal/normal video, anomaly type) and frame-level labels (abnormal/normal video frame) to facilitate anomaly detection. Leveraging the above benefits from the LAD database, we further formulate anomaly detection as a fully-supervised learning problem and propose a multi-task deep neural network to solve it. We first obtain the local spatiotemporal contextual feature by using an Inflated 3D convolutional (I3D) network. Then we construct a recurrent convolutional neural network fed the local spatiotemporal contextual feature to extract the spatiotemporal contextual feature. With the global spatiotemporal contextual feature, the anomaly type and score can be computed simultaneously by a multi-task neural network. Experimental results show that the proposed method outperforms the state-of-the-art anomaly detection methods on our database and other public databases of anomaly detection. Codes are available at https://github.com/wanboyang/anomaly_detection_LAD2000.
Salient object detection on hyperspectral images using features learned from unsupervised segmentation task
Feb 28, 2019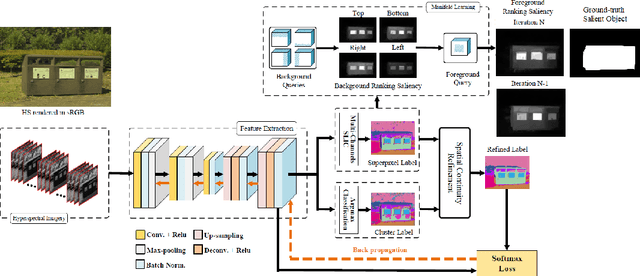
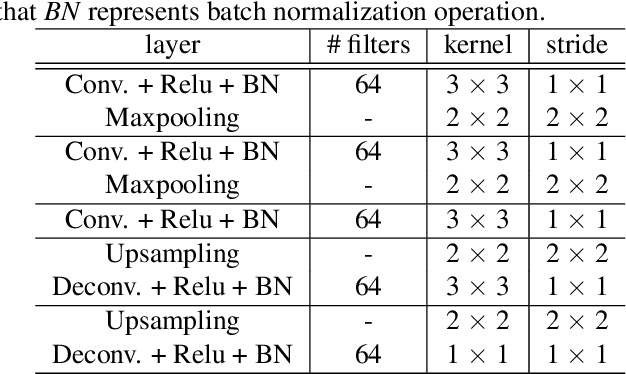
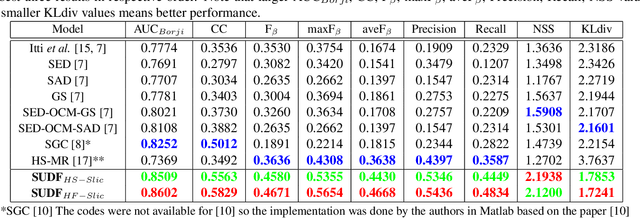

Various saliency detection algorithms from color images have been proposed to mimic eye fixation or attentive object detection response of human observers for the same scenes. However, developments on hyperspectral imaging systems enable us to obtain redundant spectral information of the observed scenes from the reflected light source from objects. A few studies using low-level features on hyperspectral images demonstrated that salient object detection can be achieved. In this work, we proposed a salient object detection model on hyperspectral images by applying manifold ranking (MR) on self-supervised Convolutional Neural Network (CNN) features (high-level features) from unsupervised image segmentation task. Self-supervision of CNN continues until clustering loss or saliency maps converges to a defined error between each iteration. Finally, saliency estimations is done as the saliency map at last iteration when the self-supervision procedure terminates with convergence. Experimental evaluations demonstrated that proposed saliency detection algorithm on hyperspectral images is outperforming state-of-the-arts hyperspectral saliency models including the original MR based saliency model.
Robustness Analysis of Pedestrian Detectors for Surveillance
Jul 17, 2018

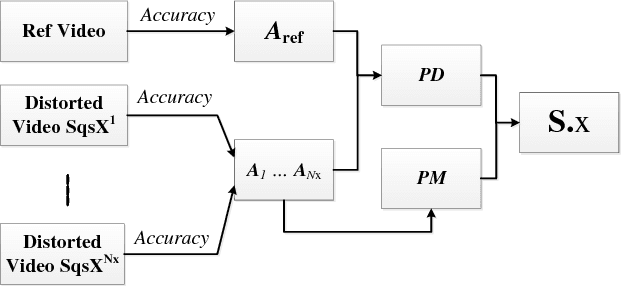
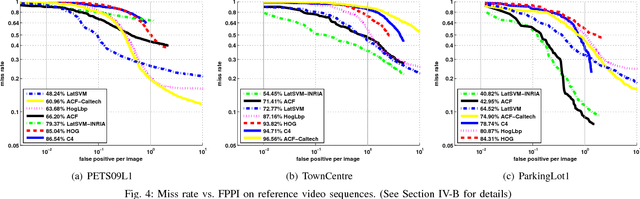
To obtain effective pedestrian detection results in surveillance video, there have been many methods proposed to handle the problems from severe occlusion, pose variation, clutter background, \emph{etc}. Besides detection accuracy, a robust surveillance video system should be stable to video quality degradation by network transmission, environment variation, etc. In this study, we conduct the research on the robustness of pedestrian detection algorithms to video quality degradation. The main contribution of this work includes the following three aspects. First, a large-scale Distorted Surveillance Video Data Set (DSurVD) is constructed from high-quality video sequences and their corresponding distorted versions. Second, we design a method to evaluate detection stability and a robustness measure called Robustness Quadrangle, which can be adopted to visualize detection accuracy of pedestrian detection algorithms on high-quality video sequences and stability with video quality degradation. Third, the robustness of seven existing pedestrian detection algorithms is evaluated by the built DSurVD. Experimental results show that the robustness can be further improved for existing pedestrian detection algorithms. Additionally, we provide much in-depth discussion on how different distortion types influence the performance of pedestrian detection algorithms, which is important to design effective pedestrian detection algorithms for surveillance. The DSurVD data set can be download from BaiduYunDisk, https://pan.baidu.com/s/1I9Kqj8rmubOYu7bkBfkUpA, Password: lqmc
Video Saliency Detection by 3D Convolutional Neural Networks
Jul 12, 2018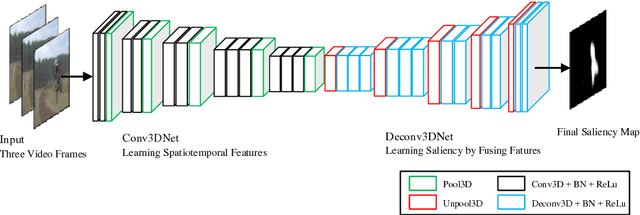
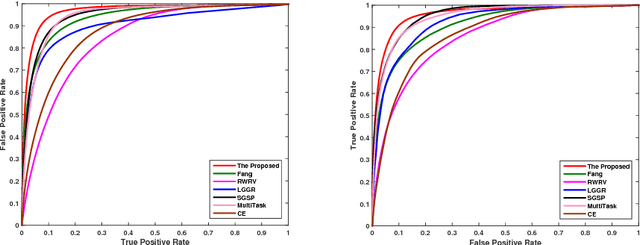
Different from salient object detection methods for still images, a key challenging for video saliency detection is how to extract and combine spatial and temporal features. In this paper, we present a novel and effective approach for salient object detection for video sequences based on 3D convolutional neural networks. First, we design a 3D convolutional network (Conv3DNet) with the input as three video frame to learn the spatiotemporal features for video sequences. Then, we design a 3D deconvolutional network (Deconv3DNet) to combine the spatiotemporal features to predict the final saliency map for video sequences. Experimental results show that the proposed saliency detection model performs better in video saliency prediction compared with the state-of-the-art video saliency detection methods.
Hyperspectral Image Dataset for Benchmarking on Salient Object Detection
Jul 02, 2018


Many works have been done on salient object detection using supervised or unsupervised approaches on colour images. Recently, a few studies demonstrated that efficient salient object detection can also be implemented by using spectral features in visible spectrum of hyperspectral images from natural scenes. However, these models on hyperspectral salient object detection were tested with a very few number of data selected from various online public dataset, which are not specifically created for object detection purposes. Therefore, here, we aim to contribute to the field by releasing a hyperspectral salient object detection dataset with a collection of 60 hyperspectral images with their respective ground-truth binary images and representative rendered colour images (sRGB). We took several aspects in consideration during the data collection such as variation in object size, number of objects, foreground-background contrast, object position on the image, and etc. Then, we prepared ground truth binary images for each hyperspectral data, where salient objects are labelled on the images. Finally, we did performance evaluation using Area Under Curve (AUC) metric on some existing hyperspectral saliency detection models in literature.