 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Saliency Detection by 3D Convolutional Neural Networks
Paper and Code
Jul 12, 2018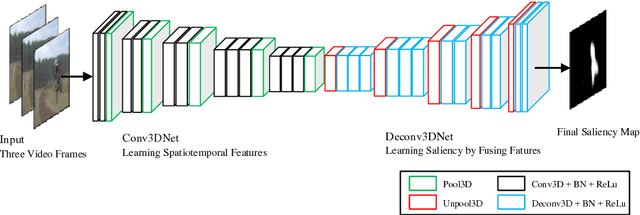
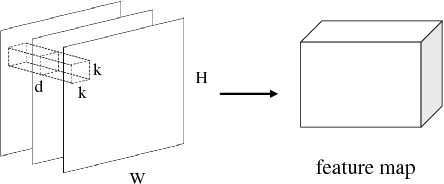
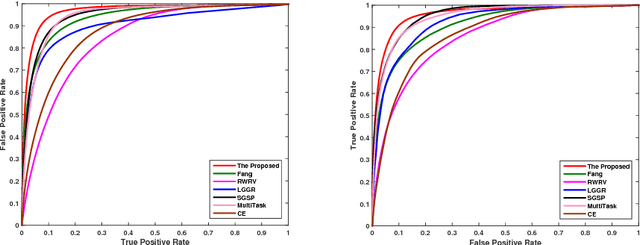
Different from salient object detection methods for still images, a key challenging for video saliency detection is how to extract and combine spatial and temporal features. In this paper, we present a novel and effective approach for salient object detection for video sequences based on 3D convolutional neural networks. First, we design a 3D convolutional network (Conv3DNet) with the input as three video frame to learn the spatiotemporal features for video sequences. Then, we design a 3D deconvolutional network (Deconv3DNet) to combine the spatiotemporal features to predict the final saliency map for video sequences. Experimental results show that the proposed saliency detection model performs better in video saliency prediction compared with the state-of-the-art video saliency detection methods.