 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSurf: A Transformer-based Diffusion Model for Generating and Reconstructing 3D Surfaces in Pose
Aug 27, 2024This paper presents DiffSurf, a transformer-based denoising diffusion model for generating and reconstructing 3D surfaces. Specifically, we design a diffusion transformer architecture that predicts noise from noisy 3D surface vertices and normals. With this architecture, DiffSurf is able to generate 3D surfaces in various poses and shapes, such as human bodies, hands, animals and man-made objects. Further, DiffSurf is versatile in that it can address various 3D downstream tasks including morphing, body shape variation and 3D human mesh fitting to 2D keypoints. Experimental results on 3D human model benchmarks demonstrate that DiffSurf can generate shapes with greater diversity and higher quality than previous generative models. Furthermore, when applied to the task of single-image 3D human mesh recovery, DiffSurf achieves accuracy comparable to prior techniques at a near real-time rate.
Leveraging Large Language Model-based Room-Object Relationships Knowledge for Enhancing Multimodal-Input Object Goal Navigation
Mar 21, 2024Object-goal navigation is a crucial engineering task for the community of embodied navigation; it involves navigating to an instance of a specified object category within unseen environments. Although extensive investigations have been conducted on both end-to-end and modular-based, data-driven approaches, fully enabling an agent to comprehend the environment through perceptual knowledge and perform object-goal navigation as efficiently as humans remains a significant challenge. Recently, large language models have shown potential in this task, thanks to their powerful capabilities for knowledge extraction and integration. In this study, we propose a data-driven, modular-based approach, trained on a dataset that incorporates common-sense knowledge of object-to-room relationships extracted from a large language model. We utilize the multi-channel Swin-Unet architecture to conduct multi-task learning incorporating with multimodal inputs. The results in the Habitat simulator demonstrate that our framework outperforms the baseline by an average of 10.6% in the efficiency metric, Success weighted by Path Length (SPL). The real-world demonstration shows that the proposed approach can efficiently conduct this task by traversing several rooms. For more details and real-world demonstrations, please check our project webpage (https://sunleyuan.github.io/ObjectNav).
PEGASUS: Physically Enhanced Gaussian Splatting Simulation System for 6DOF Object Pose Dataset Generation
Jan 04, 2024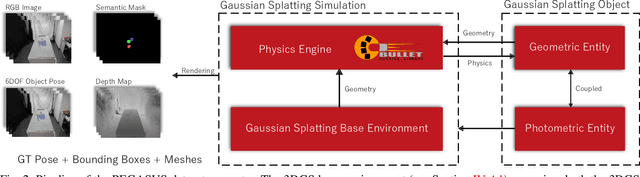


We introduce Physically Enhanced Gaussian Splatting Simulation System (PEGASUS) for 6DOF object pose dataset generation, a versatile dataset generator based on 3D Gaussian Splatting. Environment and object representations can be easily obtained using commodity cameras to reconstruct with Gaussian Splatting. PEGASUS allows the composition of new scenes by merging the respective underlying Gaussian Splatting point cloud of an environment with one or multiple objects. Leveraging a physics engine enables the simulation of natural object placement within a scene through interaction between meshes extracted for the objects and the environment. Consequently, an extensive amount of new scenes - static or dynamic - can be created by combining different environments and objects. By rendering scenes from various perspectives, diverse data points such as RGB images, depth maps, semantic masks, and 6DoF object poses can be extracted. Our study demonstrates that training on data generated by PEGASUS enables pose estimation networks to successfully transfer from synthetic data to real-world data. Moreover, we introduce the Ramen dataset, comprising 30 Japanese cup noodle items. This dataset includes spherical scans that captures images from both object hemisphere and the Gaussian Splatting reconstruction, making them compatible with PEGASUS.
NeuralLabeling: A versatile toolset for labeling vision datasets using Neural Radiance Fields
Sep 21, 2023



We present NeuralLabeling, a labeling approach and toolset for annotating a scene using either bounding boxes or meshes and generating segmentation masks, affordance maps, 2D bounding boxes, 3D bounding boxes, 6DOF object poses, depth maps and object meshes. NeuralLabeling uses Neural Radiance Fields (NeRF) as renderer, allowing labeling to be performed using 3D spatial tools while incorporating geometric clues such as occlusions, relying only on images captured from multiple viewpoints as input. To demonstrate the applicability of NeuralLabeling to a practical problem in robotics, we added ground truth depth maps to 30000 frames of transparent object RGB and noisy depth maps of glasses placed in a dishwasher captured using an RGBD sensor, yielding the Dishwasher30k dataset. We show that training a simple deep neural network with supervision using the annotated depth maps yields a higher reconstruction performance than training with the previously applied weakly supervised approach.
TransFusionOdom: Interpretable Transformer-based LiDAR-Inertial Fusion Odometry Estimation
Apr 26, 2023Multi-modal fusion of sensors is a commonly used approach to enhance the performance of odometry estimation, which is also a fundamental module for mobile robots. However, the question of \textit{how to perform fusion among different modalities in a supervised sensor fusion odometry estimation task?} is still one of challenging issues remains. Some simple operations, such as element-wise summation and concatenation, are not capable of assigning adaptive attentional weights to incorporate different modalities efficiently, which make it difficult to achieve competitive odometry results. Recently, the Transformer architecture has shown potential for multi-modal fusion tasks, particularly in the domains of vision with language. In this work, we propose an end-to-end supervised Transformer-based LiDAR-Inertial fusion framework (namely TransFusionOdom) for odometry estimation. The multi-attention fusion module demonstrates different fusion approaches for homogeneous and heterogeneous modalities to address the overfitting problem that can arise from blindly increasing the complexity of the model. Additionally, to interpret the learning process of the Transformer-based multi-modal interactions, a general visualization approach is introduced to illustrate the interactions between modalities. Moreover, exhaustive ablation studies evaluate different multi-modal fusion strategies to verify the performance of the proposed fusion strategy. A synthetic multi-modal dataset is made public to validate the generalization ability of the proposed fusion strategy, which also works for other combinations of different modalities. The quantitative and qualitative odometry evaluations on the KITTI dataset verify the proposed TransFusionOdom could achieve superior performance compared with other related works.
Instance-specific 6-DoF Object Pose Estimation from Minimal Annotations
Jul 27, 2022
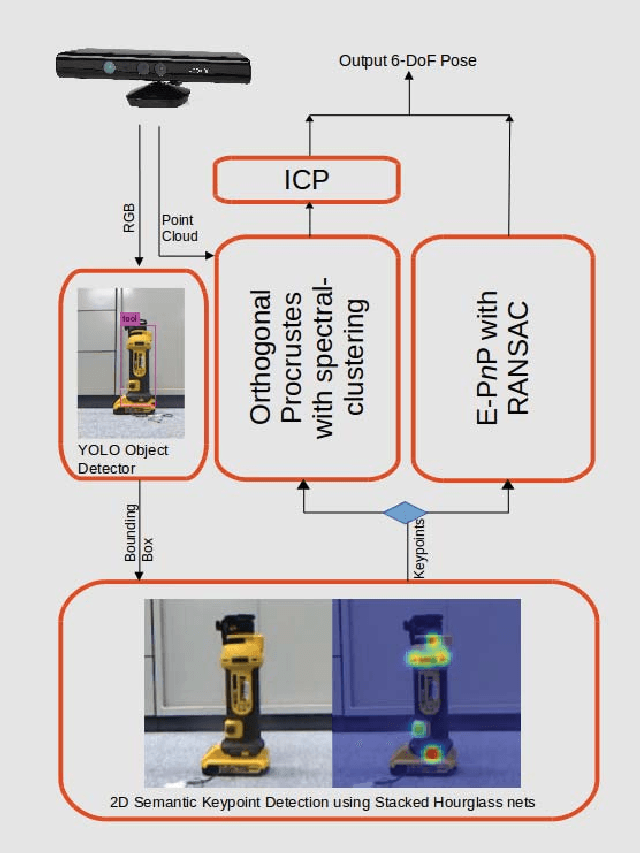
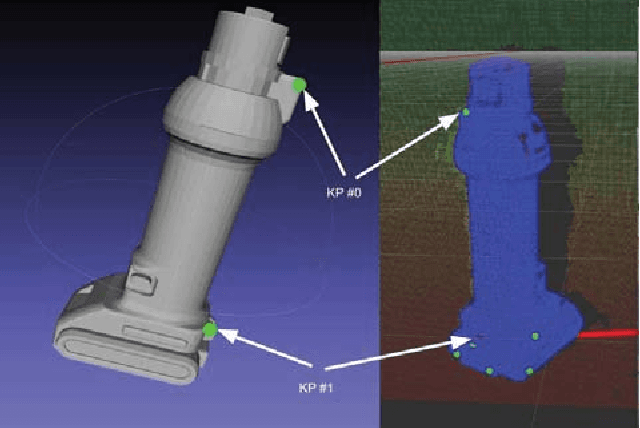
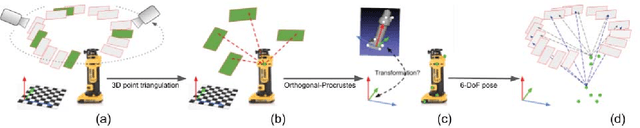
In many robotic applications, the environment setting in which the 6-DoF pose estimation of a known, rigid object and its subsequent grasping is to be performed, remains nearly unchanging and might even be known to the robot in advance. In this paper, we refer to this problem as instance-specific pose estimation: the robot is expected to estimate the pose with a high degree of accuracy in only a limited set of familiar scenarios. Minor changes in the scene, including variations in lighting conditions and background appearance, are acceptable but drastic alterations are not anticipated. To this end, we present a method to rapidly train and deploy a pipeline for estimating the continuous 6-DoF pose of an object from a single RGB image. The key idea is to leverage known camera poses and rigid body geometry to partially automate the generation of a large labeled dataset. The dataset, along with sufficient domain randomization, is then used to supervise the training of deep neural networks for predicting semantic keypoints. Experimentally, we demonstrate the convenience and effectiveness of our proposed method to accurately estimate object pose requiring only a very small amount of manual annotation for training.
* GitHub code: https://github.com/rohanpsingh/ObjectKeypointTrainer
Object Memory Transformer for Object Goal Navigation
Mar 24, 2022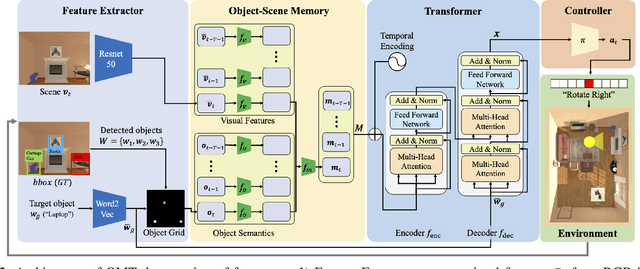
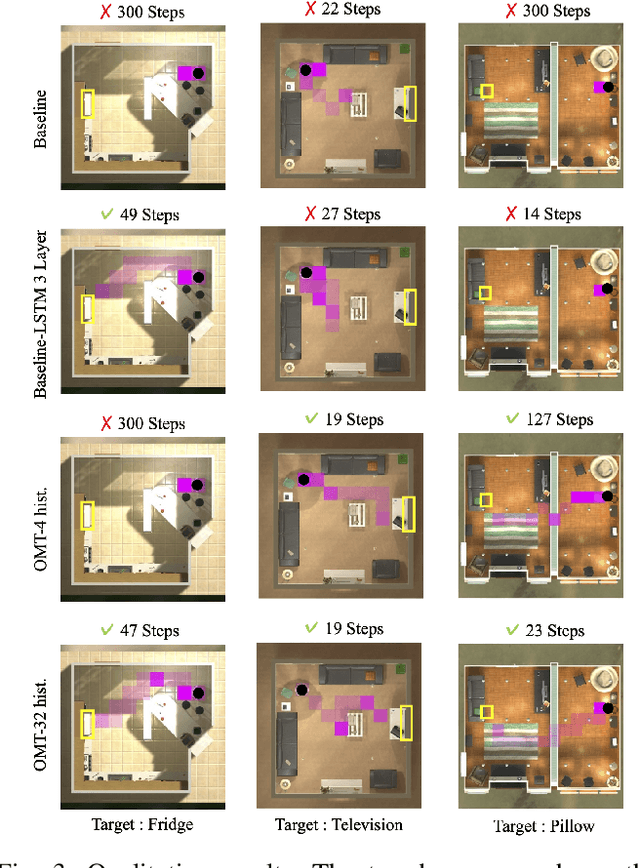
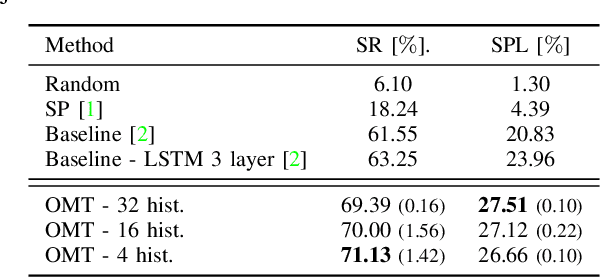
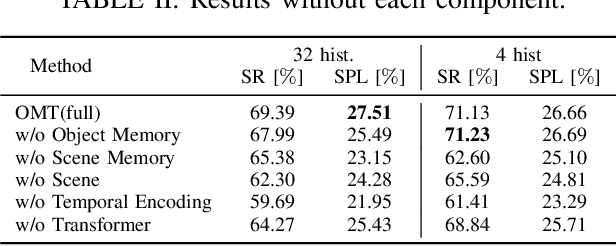
This paper presents a reinforcement learning method for object goal navigation (ObjNav) where an agent navigates in 3D indoor environments to reach a target object based on long-term observations of objects and scenes. To this end, we propose Object Memory Transformer (OMT) that consists of two key ideas: 1) Object-Scene Memory (OSM) that enables to store long-term scenes and object semantics, and 2) Transformer that attends to salient objects in the sequence of previously observed scenes and objects stored in OSM. This mechanism allows the agent to efficiently navigate in the indoor environment without prior knowledge about the environments, such as topological maps or 3D meshes. To the best of our knowledge, this is the first work that uses a long-term memory of object semantics in a goal-oriented navigation task. Experimental results conducted on the AI2-THOR dataset show that OMT outperforms previous approaches in navigating in unknown environments. In particular, we show that utilizing the long-term object semantics information improves the efficiency of navigation.
Rapid Pose Label Generation through Sparse Representation of Unknown Objects
Nov 07, 2020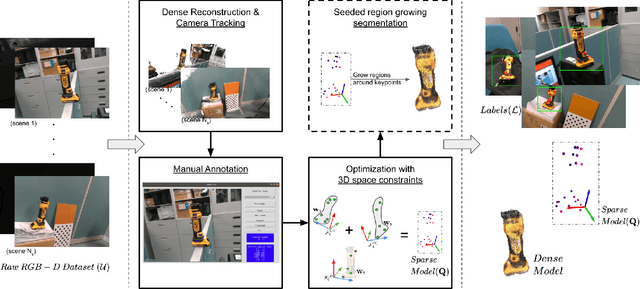
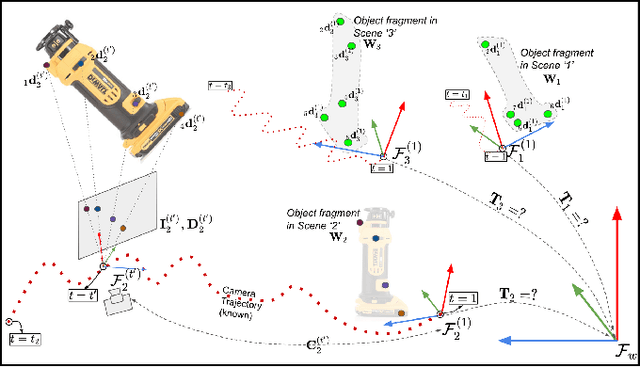

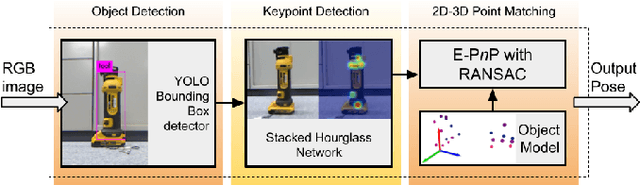
Deep Convolutional Neural Networks (CNNs) have been successfully deployed on robots for 6-DoF object pose estimation through visual perception. However, obtaining labeled data on a scale required for the supervised training of CNNs is a difficult task - exacerbated if the object is novel and a 3D model is unavailable. To this end, this work presents an approach for rapidly generating real-world, pose-annotated RGB-D data for unknown objects. Our method not only circumvents the need for a prior 3D object model (textured or otherwise) but also bypasses complicated setups of fiducial markers, turntables, and sensors. With the help of a human user, we first source minimalistic labelings of an ordered set of arbitrarily chosen keypoints over a set of RGB-D videos. Then, by solving an optimization problem, we combine these labels under a world frame to recover a sparse, keypoint-based representation of the object. The sparse representation leads to the development of a dense model and the pose labels for each image frame in the set of scenes. We show that the sparse model can also be efficiently used for scaling to a large number of new scenes. We demonstrate the practicality of the generated labeled dataset by training a pipeline for 6-DoF object pose estimation and a pixel-wise segmentation network.
Deep Reactive Planning in Dynamic Environments
Nov 05, 2020
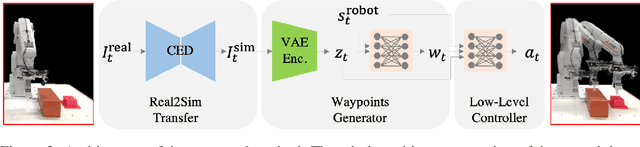


The main novelty of the proposed approach is that it allows a robot to learn an end-to-end policy which can adapt to changes in the environment during execution. While goal conditioning of policies has been studied in the RL literature, such approaches are not easily extended to cases where the robot's goal can change during execution. This is something that humans are naturally able to do. However, it is difficult for robots to learn such reflexes (i.e., to naturally respond to dynamic environments), especially when the goal location is not explicitly provided to the robot, and instead needs to be perceived through a vision sensor. In the current work, we present a method that can achieve such behavior by combining traditional kinematic planning, deep learning, and deep reinforcement learning in a synergistic fashion to generalize to arbitrary environments. We demonstrate the proposed approach for several reaching and pick-and-place tasks in simulation, as well as on a real system of a 6-DoF industrial manipulator. A video describing our work could be found \url{https://youtu.be/hE-Ew59GRPQ}.
Efficient Exploration in Constrained Environments with Goal-Oriented Reference Path
Mar 03, 2020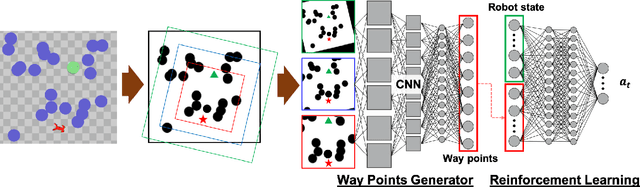
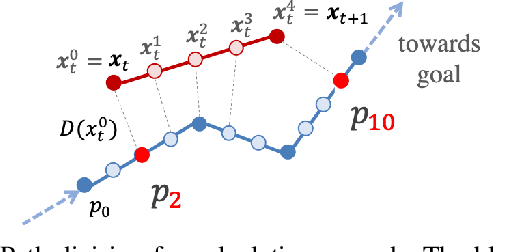
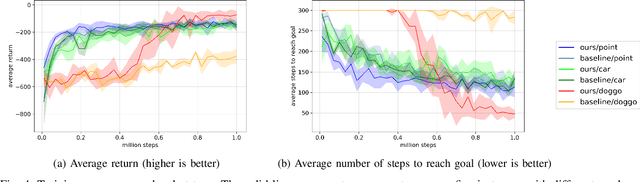
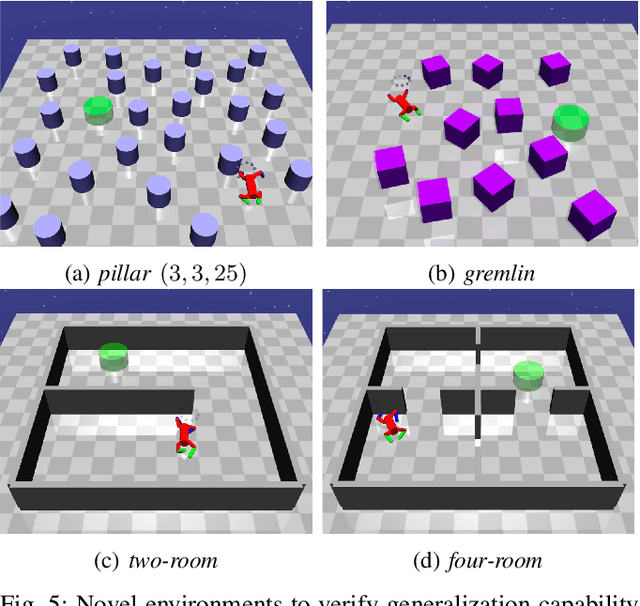
In this paper, we consider the problem of building learning agents that can efficiently learn to navigate in constrained environments. The main goal is to design agents that can efficiently learn to understand and generalize to different environments using high-dimensional inputs (a 2D map), while following feasible paths that avoid obstacles in obstacle-cluttered environment. To achieve this, we make use of traditional path planning algorithms, supervised learning, and reinforcement learning algorithms in a synergistic way. The key idea is to decouple the navigation problem into planning and control, the former of which is achieved by supervised learning whereas the latter is done by reinforcement learning. Specifically, we train a deep convolutional network that can predict collision-free paths based on a map of the environment-- this is then used by a reinforcement learning algorithm to learn to closely follow the path. This allows the trained agent to achieve good generalization while learning faster. We test our proposed method in the recently proposed Safety Gym suite that allows testing of safety-constraints during training of learning agents. We compare our proposed method with existing work and show that our method consistently improves the sample efficiency and generalization capability to novel environments.