 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Pose Label Generation through Sparse Representation of Unknown Objects
Paper and Code
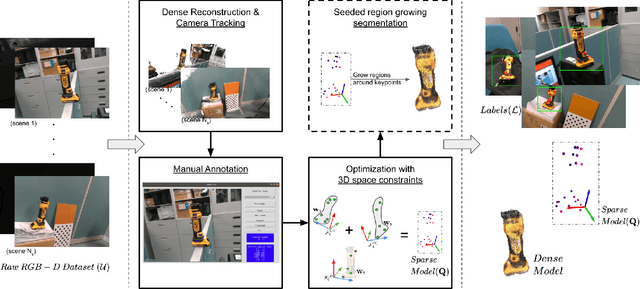
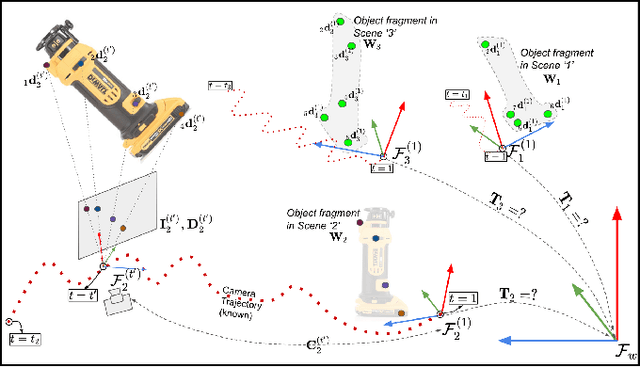

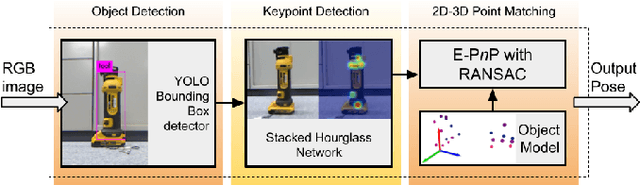
Deep Convolutional Neural Networks (CNNs) have been successfully deployed on robots for 6-DoF object pose estimation through visual perception. However, obtaining labeled data on a scale required for the supervised training of CNNs is a difficult task - exacerbated if the object is novel and a 3D model is unavailable. To this end, this work presents an approach for rapidly generating real-world, pose-annotated RGB-D data for unknown objects. Our method not only circumvents the need for a prior 3D object model (textured or otherwise) but also bypasses complicated setups of fiducial markers, turntables, and sensors. With the help of a human user, we first source minimalistic labelings of an ordered set of arbitrarily chosen keypoints over a set of RGB-D videos. Then, by solving an optimization problem, we combine these labels under a world frame to recover a sparse, keypoint-based representation of the object. The sparse representation leads to the development of a dense model and the pose labels for each image frame in the set of scenes. We show that the sparse model can also be efficiently used for scaling to a large number of new scenes. We demonstrate the practicality of the generated labeled dataset by training a pipeline for 6-DoF object pose estimation and a pixel-wise segmentation network.