 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Bipedal Walking for Humanoids with Current Feedback
Mar 07, 2023



Recent advances in deep reinforcement learning (RL) based techniques combined with training in simulation have offered a new approach to developing control policies for legged robots. However, the application of such approaches to real hardware has largely been limited to quadrupedal robots with direct-drive actuators and light-weight bipedal robots with low gear-ratio transmission systems. Application to life-sized humanoid robots has been elusive due to the large sim-to-real gap arising from their large size, heavier limbs, and a high gear-ratio transmission systems. In this paper, we present an approach for effectively overcoming the sim-to-real gap issue for humanoid robots arising from inaccurate torque tracking at the actuator level. Our key idea is to utilize the current feedback from the motors on the real robot, after training the policy in a simulation environment artificially degraded with poor torque tracking. Our approach successfully trains an end-to-end policy in simulation that can be deployed on a real HRP-5P humanoid robot for bipedal locomotion on challenging terrain. We also perform robustness tests on the RL policy and compare its performance against a conventional model-based controller for walking on uneven terrain. YouTube video: https://youtu.be/IeUaSsBRbNY
Instance-specific 6-DoF Object Pose Estimation from Minimal Annotations
Jul 27, 2022
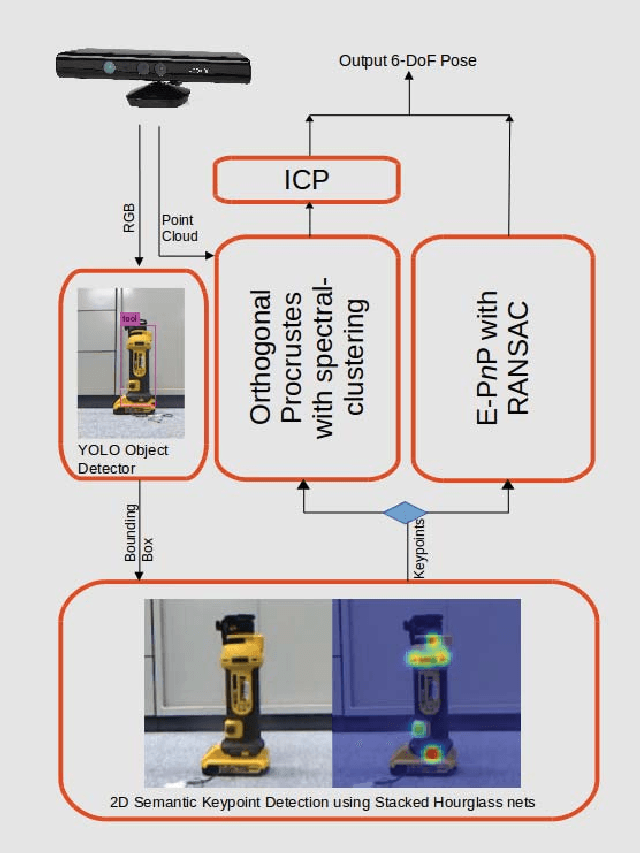
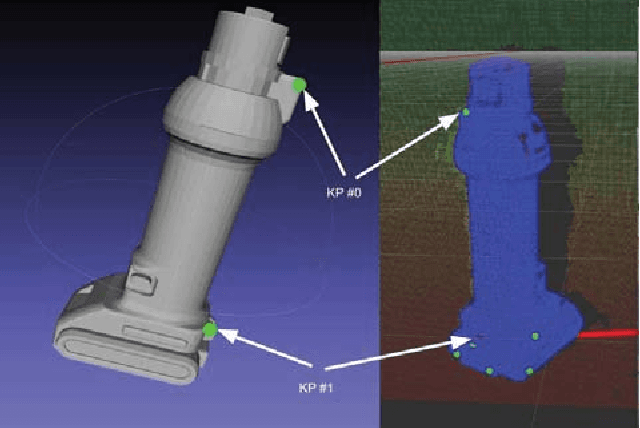
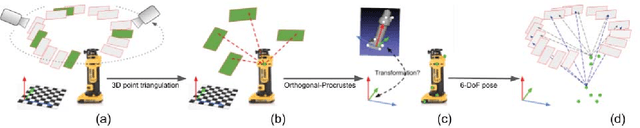
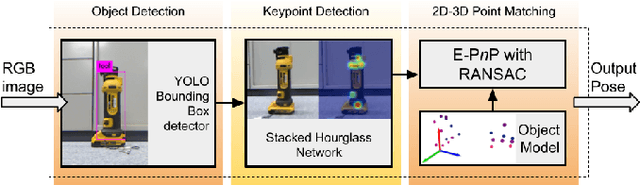
In many robotic applications, the environment setting in which the 6-DoF pose estimation of a known, rigid object and its subsequent grasping is to be performed, remains nearly unchanging and might even be known to the robot in advance. In this paper, we refer to this problem as instance-specific pose estimation: the robot is expected to estimate the pose with a high degree of accuracy in only a limited set of familiar scenarios. Minor changes in the scene, including variations in lighting conditions and background appearance, are acceptable but drastic alterations are not anticipated. To this end, we present a method to rapidly train and deploy a pipeline for estimating the continuous 6-DoF pose of an object from a single RGB image. The key idea is to leverage known camera poses and rigid body geometry to partially automate the generation of a large labeled dataset. The dataset, along with sufficient domain randomization, is then used to supervise the training of deep neural networks for predicting semantic keypoints. Experimentally, we demonstrate the convenience and effectiveness of our proposed method to accurately estimate object pose requiring only a very small amount of manual annotation for training.
* GitHub code: https://github.com/rohanpsingh/ObjectKeypointTrainer
Learning Bipedal Walking On Planned Footsteps For Humanoid Robots
Jul 26, 2022



Deep reinforcement learning (RL) based controllers for legged robots have demonstrated impressive robustness for walking in different environments for several robot platforms. To enable the application of RL policies for humanoid robots in real-world settings, it is crucial to build a system that can achieve robust walking in any direction, on 2D and 3D terrains, and be controllable by a user-command. In this paper, we tackle this problem by learning a policy to follow a given step sequence. The policy is trained with the help of a set of procedurally generated step sequences (also called footstep plans). We show that simply feeding the upcoming 2 steps to the policy is sufficient to achieve omnidirectional walking, turning in place, standing, and climbing stairs. Our method employs curriculum learning on the complexity of terrains, and circumvents the need for reference motions or pre-trained weights. We demonstrate the application of our proposed method to learn RL policies for 2 new robot platforms - HRP5P and JVRC-1 - in the MuJoCo simulation environment. The code for training and evaluation is available online.
Rapid Pose Label Generation through Sparse Representation of Unknown Objects
Nov 07, 2020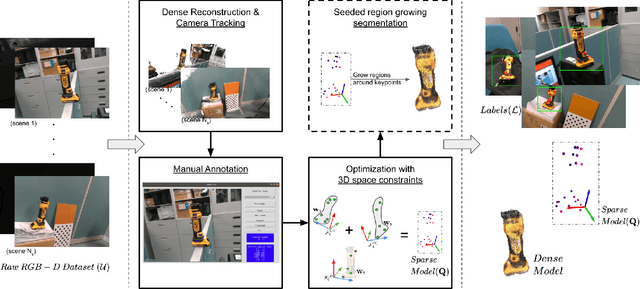
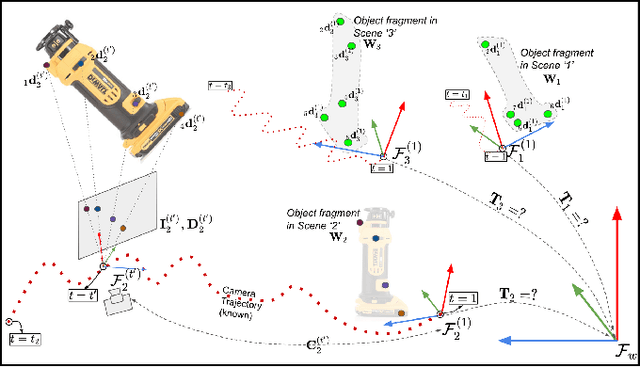

Deep Convolutional Neural Networks (CNNs) have been successfully deployed on robots for 6-DoF object pose estimation through visual perception. However, obtaining labeled data on a scale required for the supervised training of CNNs is a difficult task - exacerbated if the object is novel and a 3D model is unavailable. To this end, this work presents an approach for rapidly generating real-world, pose-annotated RGB-D data for unknown objects. Our method not only circumvents the need for a prior 3D object model (textured or otherwise) but also bypasses complicated setups of fiducial markers, turntables, and sensors. With the help of a human user, we first source minimalistic labelings of an ordered set of arbitrarily chosen keypoints over a set of RGB-D videos. Then, by solving an optimization problem, we combine these labels under a world frame to recover a sparse, keypoint-based representation of the object. The sparse representation leads to the development of a dense model and the pose labels for each image frame in the set of scenes. We show that the sparse model can also be efficiently used for scaling to a large number of new scenes. We demonstrate the practicality of the generated labeled dataset by training a pipeline for 6-DoF object pose estimation and a pixel-wise segmentation network.