 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanoid Loco-Manipulations Pattern Generation and Stabilization Control
May 30, 2025



In order for a humanoid robot to perform loco-manipulation such as moving an object while walking, it is necessary to account for sustained or alternating external forces other than ground-feet reaction, resulting from humanoid-object contact interactions. In this letter, we propose a bipedal control strategy for humanoid loco-manipulation that can cope with such external forces. First, the basic formulas of the bipedal dynamics, i.e., linear inverted pendulum mode and divergent component of motion, are derived, taking into account the effects of external manipulation forces. Then, we propose a pattern generator to plan center of mass trajectories consistent with the reference trajectory of the manipulation forces, and a stabilizer to compensate for the error between desired and actual manipulation forces. The effectiveness of our controller is assessed both in simulation and loco-manipulation experiments with real humanoid robots.
Humanoid Loco-manipulation Planning based on Graph Search and Reachability Maps
May 29, 2025In this letter, we propose an efficient and highly versatile loco-manipulation planning for humanoid robots. Loco-manipulation planning is a key technological brick enabling humanoid robots to autonomously perform object transportation by manipulating them. We formulate planning of the alternation and sequencing of footsteps and grasps as a graph search problem with a new transition model that allows for a flexible representation of loco-manipulation. Our transition model is quickly evaluated by relocating and switching the reachability maps depending on the motion of both the robot and object. We evaluate our approach by applying it to loco-manipulation use-cases, such as a bobbin rolling operation with regrasping, where the motion is automatically planned by our framework.
Centroidal Trajectory Generation and Stabilization based on Preview Control for Humanoid Multi-contact Motion
May 29, 2025



Multi-contact motion is important for humanoid robots to work in various environments. We propose a centroidal online trajectory generation and stabilization control for humanoid dynamic multi-contact motion. The proposed method features the drastic reduction of the computational cost by using preview control instead of the conventional model predictive control that considers the constraints of all sample times. By combining preview control with centroidal state feedback for robustness to disturbances and wrench distribution for satisfying contact constraints, we show that the robot can stably perform a variety of multi-contact motions through simulation experiments.
Whole-body Multi-contact Motion Control for Humanoid Robots Based on Distributed Tactile Sensors
May 26, 2025
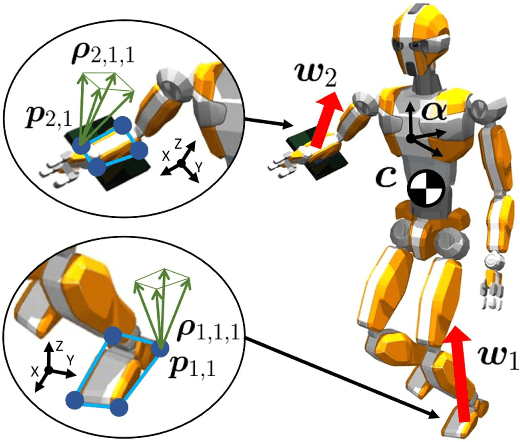
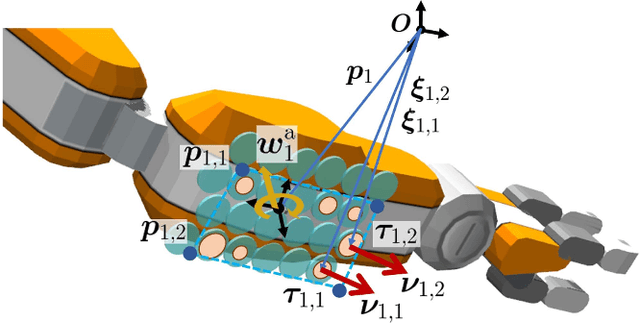

To enable humanoid robots to work robustly in confined environments, multi-contact motion that makes contacts not only at extremities, such as hands and feet, but also at intermediate areas of the limbs, such as knees and elbows, is essential. We develop a method to realize such whole-body multi-contact motion involving contacts at intermediate areas by a humanoid robot. Deformable sheet-shaped distributed tactile sensors are mounted on the surface of the robot's limbs to measure the contact force without significantly changing the robot body shape. The multi-contact motion controller developed earlier, which is dedicated to contact at extremities, is extended to handle contact at intermediate areas, and the robot motion is stabilized by feedback control using not only force/torque sensors but also distributed tactile sensors. Through verification on dynamics simulations, we show that the developed tactile feedback improves the stability of whole-body multi-contact motion against disturbances and environmental errors. Furthermore, the life-sized humanoid RHP Kaleido demonstrates whole-body multi-contact motions, such as stepping forward while supporting the body with forearm contact and balancing in a sitting posture with thigh contacts.
Robust Humanoid Walking on Compliant and Uneven Terrain with Deep Reinforcement Learning
Apr 18, 2025For the deployment of legged robots in real-world environments, it is essential to develop robust locomotion control methods for challenging terrains that may exhibit unexpected deformability and irregularity. In this paper, we explore the application of sim-to-real deep reinforcement learning (RL) for the design of bipedal locomotion controllers for humanoid robots on compliant and uneven terrains. Our key contribution is to show that a simple training curriculum for exposing the RL agent to randomized terrains in simulation can achieve robust walking on a real humanoid robot using only proprioceptive feedback. We train an end-to-end bipedal locomotion policy using the proposed approach, and show extensive real-robot demonstration on the HRP-5P humanoid over several difficult terrains inside and outside the lab environment. Further, we argue that the robustness of a bipedal walking policy can be improved if the robot is allowed to exhibit aperiodic motion with variable stepping frequency. We propose a new control policy to enable modification of the observed clock signal, leading to adaptive gait frequencies depending on the terrain and command velocity. Through simulation experiments, we show the effectiveness of this policy specifically for walking over challenging terrains by controlling swing and stance durations. The code for training and evaluation is available online at https://github.com/rohanpsingh/LearningHumanoidWalking. Demo video is available at https://www.youtube.com/watch?v=ZgfNzGAkk2Q.
Scalable, Training-Free Visual Language Robotics: A Modular Multi-Model Framework for Consumer-Grade GPUs
Feb 03, 2025


The integration of language instructions with robotic control, particularly through Vision Language Action (VLA) models, has shown significant potential. However, these systems are often hindered by high computational costs, the need for extensive retraining, and limited scalability, making them less accessible for widespread use. In this paper, we introduce SVLR (Scalable Visual Language Robotics), an open-source, modular framework that operates without the need for retraining, providing a scalable solution for robotic control. SVLR leverages a combination of lightweight, open-source AI models including the Vision-Language Model (VLM) Mini-InternVL, zero-shot image segmentation model CLIPSeg, Large Language Model Phi-3, and sentence similarity model all-MiniLM to process visual and language inputs. These models work together to identify objects in an unknown environment, use them as parameters for task execution, and generate a sequence of actions in response to natural language instructions. A key strength of SVLR is its scalability. The framework allows for easy integration of new robotic tasks and robots by simply adding text descriptions and task definitions, without the need for retraining. This modularity ensures that SVLR can continuously adapt to the latest advancements in AI technologies and support a wide range of robots and tasks. SVLR operates effectively on an NVIDIA RTX 2070 (mobile) GPU, demonstrating promising performance in executing pick-and-place tasks. While these initial results are encouraging, further evaluation across a broader set of tasks and comparisons with existing VLA models are needed to assess SVLR's generalization capabilities and performance in more complex scenarios.
Humanoid Robot RHP Friends: Seamless Combination of Autonomous and Teleoperated Tasks in a Nursing Context
Dec 30, 2024



This paper describes RHP Friends, a social humanoid robot developed to enable assistive robotic deployments in human-coexisting environments. As a use-case application, we present its potential use in nursing by extending its capabilities to operate human devices and tools according to the task and by enabling remote assistance operations. To meet a wide variety of tasks and situations in environments designed by and for humans, we developed a system that seamlessly integrates the slim and lightweight robot and several technologies: locomanipulation, multi-contact motion, teleoperation, and object detection and tracking. We demonstrated the system's usage in a nursing application. The robot efficiently performed the daily task of patient transfer and a non-routine task, represented by a request to operate a circuit breaker. This demonstration, held at the 2023 International Robot Exhibition (IREX), conducted three times a day over three days.
The Kinetics Observer: A Tightly Coupled Estimator for Legged Robots
Jun 19, 2024



In this paper, we propose the "Kinetics Observer", a novel estimator addressing the challenge of state estimation for legged robots using proprioceptive sensors (encoders, IMU and force/torque sensors). Based on a Multiplicative Extended Kalman Filter, the Kinetics Observer allows the real-time simultaneous estimation of contact and perturbation forces, and of the robot's kinematics, which are accurate enough to perform proprioceptive odometry. Thanks to a visco-elastic model of the contacts linking their kinematics to the ones of the centroid of the robot, the Kinetics Observer ensures a tight coupling between the whole-body kinematics and dynamics of the robot. This coupling entails a redundancy of the measurements that enhances the robustness and the accuracy of the estimation. This estimator was tested on two humanoid robots performing long distance walking on even terrain and non-coplanar multi-contact locomotion.
Analysis and Perspectives on the ANA Avatar XPRIZE Competition
Jan 10, 2024

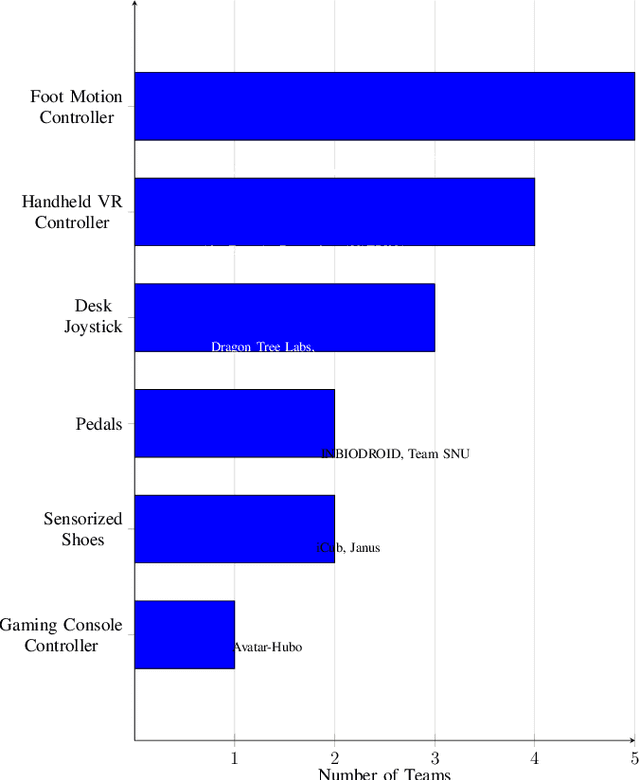
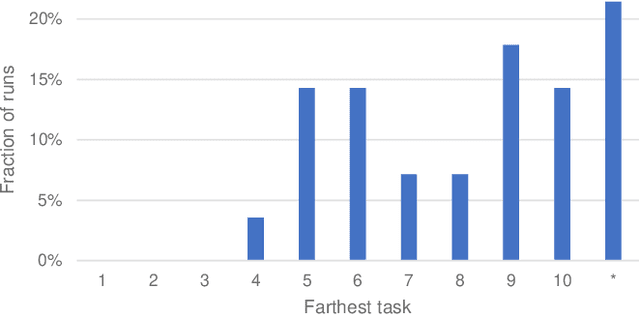
The ANA Avatar XPRIZE was a four-year competition to develop a robotic "avatar" system to allow a human operator to sense, communicate, and act in a remote environment as though physically present. The competition featured a unique requirement that judges would operate the avatars after less than one hour of training on the human-machine interfaces, and avatar systems were judged on both objective and subjective scoring metrics. This paper presents a unified summary and analysis of the competition from technical, judging, and organizational perspectives. We study the use of telerobotics technologies and innovations pursued by the competing teams in their avatar systems, and correlate the use of these technologies with judges' task performance and subjective survey ratings. It also summarizes perspectives from team leads, judges, and organizers about the competition's execution and impact to inform the future development of telerobotics and telepresence.
TransFusionOdom: Interpretable Transformer-based LiDAR-Inertial Fusion Odometry Estimation
Apr 26, 2023Multi-modal fusion of sensors is a commonly used approach to enhance the performance of odometry estimation, which is also a fundamental module for mobile robots. However, the question of \textit{how to perform fusion among different modalities in a supervised sensor fusion odometry estimation task?} is still one of challenging issues remains. Some simple operations, such as element-wise summation and concatenation, are not capable of assigning adaptive attentional weights to incorporate different modalities efficiently, which make it difficult to achieve competitive odometry results. Recently, the Transformer architecture has shown potential for multi-modal fusion tasks, particularly in the domains of vision with language. In this work, we propose an end-to-end supervised Transformer-based LiDAR-Inertial fusion framework (namely TransFusionOdom) for odometry estimation. The multi-attention fusion module demonstrates different fusion approaches for homogeneous and heterogeneous modalities to address the overfitting problem that can arise from blindly increasing the complexity of the model. Additionally, to interpret the learning process of the Transformer-based multi-modal interactions, a general visualization approach is introduced to illustrate the interactions between modalities. Moreover, exhaustive ablation studies evaluate different multi-modal fusion strategies to verify the performance of the proposed fusion strategy. A synthetic multi-modal dataset is made public to validate the generalization ability of the proposed fusion strategy, which also works for other combinations of different modalities. The quantitative and qualitative odometry evaluations on the KITTI dataset verify the proposed TransFusionOdom could achieve superior performance compared with other related works.